题目
3.(2021,Ⅲ)设(X1 Y1),(X2,Y2),···,(Xn,Yn)为来自总体N(μ1,-|||-μ2;σ1^2,σ2^2,ρ)的简单随机样本,令 theta =(mu )_(1)-(mu )_(2), overline (X)=dfrac (1)(n)sum _(i=1)^nX overline (Y)=dfrac (1)(n)sum _(i=1)^n(Y)_(i),-|||-hat (theta )=overline (X)-overline (Y), 则 () .-|||-(A) (hat (theta ))=theta ,D(hat (theta ))=dfrac ({{sigma )_(1)}^2+({sigma )_(2)}^2}(n)-|||-(B) (hat (theta ))=theta ,D(hat (theta ))=dfrac ({{sigma )_(1)}^2+({sigma )_(2)}^2-2(rho )_(2)(Q)_(2)}(n)-|||-(C) (theta )neq theta , (hat (theta ))=dfrac ({{sigma )_(1)}^2+({sigma )_(2)}^2}(n)-|||-(D) (theta )neq theta , (hat (theta ))=dfrac ({{sigma )_(1)}^2+({sigma )_(2)}^2-2rho (sigma )_(1)(sigma )_(2)}}(n)

题目解答
答案
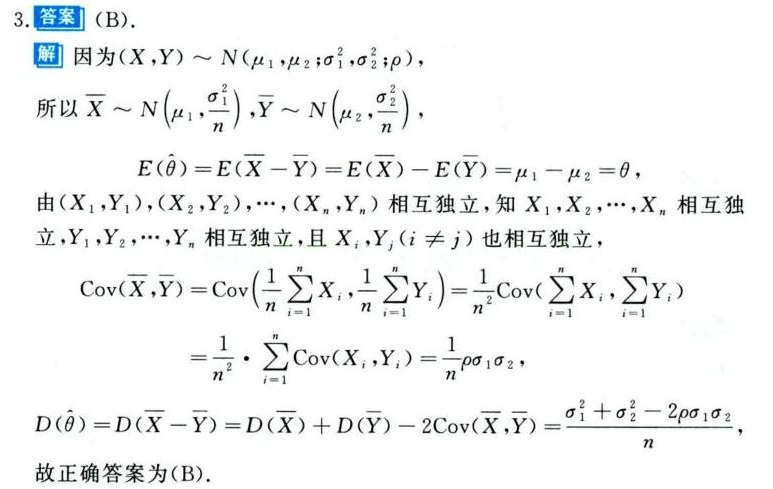
解析
考查要点:本题主要考查二元正态分布下样本均值差的期望与方差计算,重点在于理解协方差在独立样本中的作用。
解题核心思路:
- 期望计算:利用线性性质,直接求出$\hat{\theta} = \overline{X} - \overline{Y}$的期望。
- 方差计算:需考虑$\overline{X}$与$\overline{Y}$之间的协方差,因为原始变量$X_i$与$Y_i$存在相关性$\rho$。
破题关键点:
- 期望的线性性:$E(\hat{\theta}) = E(\overline{X}) - E(\overline{Y}) = \mu_1 - \mu_2 = \theta$。
- 方差的协方差项:由于$X_i$与$Y_i$相关,$D(\hat{\theta})$需包含$-2\rho\sigma_1\sigma_2/n$项,而选项A忽略了这一项。
期望计算
由$\overline{X} = \frac{1}{n}\sum X_i$和$\overline{Y} = \frac{1}{n}\sum Y_i$,根据期望的线性性:
$E(\hat{\theta}) = E(\overline{X} - \overline{Y}) = E(\overline{X}) - E(\overline{Y}) = \mu_1 - \mu_2 = \theta.$
方差计算
-
方差展开:
$D(\hat{\theta}) = D(\overline{X} - \overline{Y}) = D(\overline{X}) + D(\overline{Y}) - 2\text{Cov}(\overline{X}, \overline{Y}).$ -
计算各部分:
- $D(\overline{X}) = \frac{\sigma_1^2}{n}$,$D(\overline{Y}) = \frac{\sigma_2^2}{n}$。
- 协方差计算:
$\text{Cov}(\overline{X}, \overline{Y}) = \text{Cov}\left(\frac{1}{n}\sum X_i, \frac{1}{n}\sum Y_j\right) = \frac{1}{n^2}\sum_{i=1}^n \sum_{j=1}^n \text{Cov}(X_i, Y_j).$
由于当$i \neq j$时,$X_i$与$Y_j$独立,$\text{Cov}(X_i, Y_j) = 0$;当$i = j$时,$\text{Cov}(X_i, Y_i) = \rho\sigma_1\sigma_2$。因此:
$\text{Cov}(\overline{X}, \overline{Y}) = \frac{1}{n^2} \cdot n \cdot \rho\sigma_1\sigma_2 = \frac{\rho\sigma_1\sigma_2}{n}.$
- 代入方差公式:
$D(\hat{\theta}) = \frac{\sigma_1^2}{n} + \frac{\sigma_2^2}{n} - 2 \cdot \frac{\rho\sigma_1\sigma_2}{n} = \frac{\sigma_1^2 + \sigma_2^2 - 2\rho\sigma_1\sigma_2}{n}.$
结论:选项B正确。