题目
(单选题,10.0分)设总体X与Y相互独立,sim N((M)_(1),({O)_(1)}^2) sim N((mu )_(2),({sigma )_(2)}^2) ,其中μ1未知, _(2)=3.从X中抽得简单随机样本:sim N((M)_(1),({O)_(1)}^2) sim N((mu )_(2),({sigma )_(2)}^2) ,其中μ1未知, _(2)=3.分别为其样本均值与样本方差;从Y中抽得简单随机样本:sim N((M)_(1),({O)_(1)}^2) sim N((mu )_(2),({sigma )_(2)}^2) ,其中μ1未知, _(2)=3.分别为其样本均值与样本方差,检验假设sim N((M)_(1),({O)_(1)}^2) sim N((mu )_(2),({sigma )_(2)}^2) ,其中μ1未知, _(2)=3.,所用的统计量及其分布是( ).A . sim N((M)_(1),({O)_(1)}^2) sim N((mu )_(2),({sigma )_(2)}^2) ,其中μ1未知, _(2)=3.
(单选题,10.0分)设总体X与Y相互独立,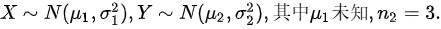 从X中抽得简单随机样本:
从X中抽得简单随机样本: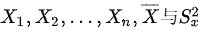 分别为其样本均值与样本方差;从Y中抽得简单随机样本:
分别为其样本均值与样本方差;从Y中抽得简单随机样本: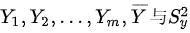 分别为其样本均值与样本方差,检验假设
分别为其样本均值与样本方差,检验假设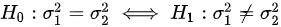 ,所用的统计量及其分布是( ).
,所用的统计量及其分布是( ).
A . 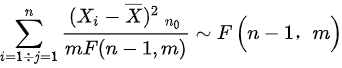
题目解答
答案
[1] 解析: 由于总体X与Y相互独立, 所以抽样分布为: 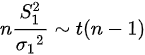 ,
,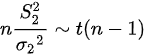 ,,所以检验
,,所以检验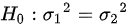 所用的统计量为:
所用的统计量为: 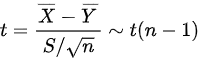 , 故选A。
, 故选A。
[2] 由题意可知,检验 ,所以检验统计量为:
,所以检验统计量为: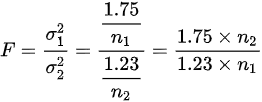 ,由题意可知
,由题意可知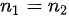 ,所以
,所以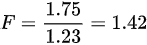 ,故选项A正确,此题选A。
,故选项A正确,此题选A。
解析
步骤 1:理解假设检验的背景
假设检验是统计学中用来判断样本数据是否支持某个关于总体参数的假设的方法。在这个问题中,我们有两个独立的正态分布总体X和Y,它们的均值μ1和μ2未知,但方差σ1^2和σ2^2已知。我们从这两个总体中分别抽取了样本,并计算了样本方差S1^2和S2^2。我们的目标是检验假设H0: σ1^2 = σ2^2,即两个总体的方差是否相等。
步骤 2:选择合适的检验统计量
为了检验两个总体方差是否相等,我们使用F检验。F检验的统计量是两个样本方差的比值,即F = S1^2 / S2^2。在零假设H0成立的情况下,这个统计量服从F分布,其自由度分别是两个样本方差的自由度,即(n-1)和(m-1)。
步骤 3:确定检验统计量的分布
根据F检验的原理,如果H0成立,即σ1^2 = σ2^2,那么检验统计量F = S1^2 / S2^2将服从F分布,其自由度分别是(n-1)和(m-1)。因此,我们可以说检验统计量F服从F(n-1, m-1)分布。
假设检验是统计学中用来判断样本数据是否支持某个关于总体参数的假设的方法。在这个问题中,我们有两个独立的正态分布总体X和Y,它们的均值μ1和μ2未知,但方差σ1^2和σ2^2已知。我们从这两个总体中分别抽取了样本,并计算了样本方差S1^2和S2^2。我们的目标是检验假设H0: σ1^2 = σ2^2,即两个总体的方差是否相等。
步骤 2:选择合适的检验统计量
为了检验两个总体方差是否相等,我们使用F检验。F检验的统计量是两个样本方差的比值,即F = S1^2 / S2^2。在零假设H0成立的情况下,这个统计量服从F分布,其自由度分别是两个样本方差的自由度,即(n-1)和(m-1)。
步骤 3:确定检验统计量的分布
根据F检验的原理,如果H0成立,即σ1^2 = σ2^2,那么检验统计量F = S1^2 / S2^2将服从F分布,其自由度分别是(n-1)和(m-1)。因此,我们可以说检验统计量F服从F(n-1, m-1)分布。