题目
设顾客在某银行的窗口等待服务的时间。(以min计)服从参数lambda =1/5的指数分布,某顾客在窗口等待服务,若超过10 min他就离开.他一个月要到银行5次,以p表示一个月内他未等到服务而离开窗口的次数,则lambda =1/5 ( ). A lambda =1/5B lambda =1/5
设顾客在某银行的窗口等待服务的时间。(以min计)服从参数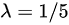 的指数分布,某顾客在窗口等待服务,若超过10 min他就离开.他一个月要到银行5次,以p表示一个月内他未等到服务而离开窗口的次数,则
的指数分布,某顾客在窗口等待服务,若超过10 min他就离开.他一个月要到银行5次,以p表示一个月内他未等到服务而离开窗口的次数,则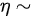 ( ).
( ).
A 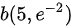
B 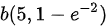
题目解答
答案
根据指数分布的性质,等待时间X的概率密度函数为:
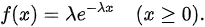
因此,
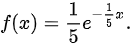
顾客在窗口等待超过 10 分钟的概率为:
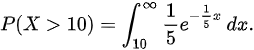 10) = \int_{10}^{\infty} \frac{1}{5} e^{-\frac{1}{5} x} \, dx." data-width="254" data-height="50" data-size="4480" data-format="png" style="">
10) = \int_{10}^{\infty} \frac{1}{5} e^{-\frac{1}{5} x} \, dx." data-width="254" data-height="50" data-size="4480" data-format="png" style="">
计算这个积分:
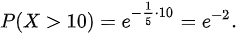 10)=e^{-\frac{1}{5}\cdot10}=e^{-2}." data-width="237" data-height="35" data-size="3075" data-format="png" style="">
10)=e^{-\frac{1}{5}\cdot10}=e^{-2}." data-width="237" data-height="35" data-size="3075" data-format="png" style="">
因此,顾客在 10 分钟内未等到服务而离开的概率为:
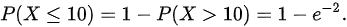 10)=1-e^{-2}." data-width="347" data-height="27" data-size="3520" data-format="png" style="">
10)=1-e^{-2}." data-width="347" data-height="27" data-size="3520" data-format="png" style="">
顾客一个月到银行 5 次,每次离开的事件是独立的。
因此,设 p 表示一个月内他未等到服务而离开窗口的次数,p服从二项分布B(n, p),其中n = 5 次,成功概率为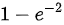 。
。
所以,有: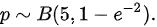
综上,正确答案为B.
解析
步骤 1:确定指数分布的概率密度函数
根据题目,顾客等待时间X服从参数$\lambda = 1/5$的指数分布,其概率密度函数为:
$f(x) = \lambda e^{-\lambda x} = \frac{1}{5} e^{-\frac{1}{5} x}$,其中$x \geq 0$。
步骤 2:计算顾客等待超过10分钟的概率
顾客等待超过10分钟的概率为:
$P(X > 10) = \int_{10}^{\infty} \frac{1}{5} e^{-\frac{1}{5} x} dx$。
计算这个积分,我们得到:
$P(X > 10) = e^{-\frac{1}{5} \cdot 10} = e^{-2}$。
步骤 3:计算顾客在10分钟内未等到服务而离开的概率
顾客在10分钟内未等到服务而离开的概率为:
$P(X \leq 10) = 1 - P(X > 10) = 1 - e^{-2}$。
步骤 4:确定顾客一个月内未等到服务而离开窗口的次数的分布
顾客一个月内到银行5次,每次离开的事件是独立的,因此,设p表示一个月内他未等到服务而离开窗口的次数,p服从二项分布B(n, p),其中n = 5次,成功概率为$1 - e^{-2}$。
所以,有:$p \sim B(5, 1 - e^{-2})$。
根据题目,顾客等待时间X服从参数$\lambda = 1/5$的指数分布,其概率密度函数为:
$f(x) = \lambda e^{-\lambda x} = \frac{1}{5} e^{-\frac{1}{5} x}$,其中$x \geq 0$。
步骤 2:计算顾客等待超过10分钟的概率
顾客等待超过10分钟的概率为:
$P(X > 10) = \int_{10}^{\infty} \frac{1}{5} e^{-\frac{1}{5} x} dx$。
计算这个积分,我们得到:
$P(X > 10) = e^{-\frac{1}{5} \cdot 10} = e^{-2}$。
步骤 3:计算顾客在10分钟内未等到服务而离开的概率
顾客在10分钟内未等到服务而离开的概率为:
$P(X \leq 10) = 1 - P(X > 10) = 1 - e^{-2}$。
步骤 4:确定顾客一个月内未等到服务而离开窗口的次数的分布
顾客一个月内到银行5次,每次离开的事件是独立的,因此,设p表示一个月内他未等到服务而离开窗口的次数,p服从二项分布B(n, p),其中n = 5次,成功概率为$1 - e^{-2}$。
所以,有:$p \sim B(5, 1 - e^{-2})$。