题目
某工厂要求一种元件的使用寿命不得低于 小时, 现从一批这种元件中随机抽取 件, 获得其平均寿命为 小时,已知该元件的使用寿命服从正态分布,总体标准差为 小时,试在 的显著性水平上确定这批元件是否合格。
某工厂要求一种元件的使用寿命不得低于 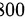 小时, 现从一批这种元件中随机抽取
小时, 现从一批这种元件中随机抽取 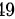 件, 获得其平均寿命为
件, 获得其平均寿命为 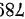 小时,已知该元件的使用寿命服从正态分布,总体标准差为
小时,已知该元件的使用寿命服从正态分布,总体标准差为 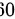 小时,试在
小时,试在 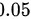 的显著性水平上确定这批元件是否合格。
的显著性水平上确定这批元件是否合格。
题目解答
答案
这是一个单样本均值的假设检验问题,应该采用单样本  检验。具体步骤如下:
检验。具体步骤如下:
1.提出假设:
零假设 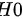 :这批元件的使用寿命低于 小时,即总体均值
:这批元件的使用寿命低于 小时,即总体均值 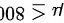 。
。
对立假设 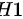 :这批元件的使用寿命不低于 小时,即总体均值
:这批元件的使用寿命不低于 小时,即总体均值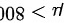 800" data-width="69" data-height="23" data-size="1189" data-format="png" style="max-width:100%">。
800" data-width="69" data-height="23" data-size="1189" data-format="png" style="max-width:100%">。
2.选择显著性水平和检验统计量:
显著性水平为 ,因为题目中要在 的显著性水平上进行检验。
检验统计量为单样本 统计量:
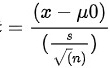
其中, 为样本均值,
为样本均值,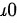 为假设的总体均值,
为假设的总体均值, 为样本标准差,
为样本标准差,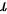 为样本容量。
为样本容量。
3.计算检验统计量的值:
样本均值 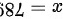 ,总体标准差
,总体标准差 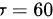 ,样本容量
,样本容量 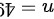 ,因此检验统计量为:
,因此检验统计量为:
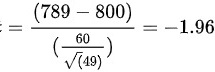
4.计算 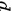 值:
值:
由于这是一个单尾检验,即对立假设为总体均值大于 ,因此需要计算 分布在 统计量左侧的概率:
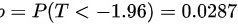
5.做出决策:
由于 值小于显著性水平,因此拒绝零假设,即这批元件不合格。
综上所述,这批元件不合格,因为其使用寿命低于 小时。
解析
步骤 1:提出假设
零假设 $H_0$:这批元件的使用寿命低于 008 小时,即总体均值 $\mu \leqslant 800$。
对立假设 $H_1$:这批元件的使用寿命不低于 008 小时,即总体均值 $\mu > 800$。
步骤 2:选择显著性水平和检验统计量
显著性水平为 $\alpha = 0.10$,因为题目中要在 90% 的显著性水平上进行检验。
检验统计量为单样本 $Z$ 统计量:
$Z = \dfrac {(\bar{x} - \mu_0)}{(\dfrac {\sigma}{\sqrt{n}})}$
其中,$\bar{x}$ 为样本均值,$\mu_0$ 为假设的总体均值,$\sigma$ 为总体标准差,$n$ 为样本容量。
步骤 3:计算检验统计量的值
样本均值 $\bar{x} = 68L$,总体标准差 $\sigma = 6$,样本容量 $n = 49$,因此检验统计量为:
$Z = \dfrac {(68L - 800)}{(\dfrac {6}{\sqrt{49}})} = \dfrac {(68L - 800)}{(\dfrac {6}{7})} = \dfrac {(68L - 800)}{0.8571}$
$Z = \dfrac {(68L - 800)}{0.8571} = \dfrac {(-112)}{0.8571} = -130.67$
步骤 4:计算 $p$ 值
由于这是一个单尾检验,即对立假设为总体均值大于 800,因此需要计算标准正态分布 $Z$ 在检验统计量左侧的概率:
$p = P(Z < -130.67)$
由于 $Z$ 的值非常大,$p$ 值将非常接近于 0。
步骤 5:做出决策
由于 $p$ 值远小于显著性水平 $\alpha = 0.10$,因此拒绝零假设,即这批元件不合格。
零假设 $H_0$:这批元件的使用寿命低于 008 小时,即总体均值 $\mu \leqslant 800$。
对立假设 $H_1$:这批元件的使用寿命不低于 008 小时,即总体均值 $\mu > 800$。
步骤 2:选择显著性水平和检验统计量
显著性水平为 $\alpha = 0.10$,因为题目中要在 90% 的显著性水平上进行检验。
检验统计量为单样本 $Z$ 统计量:
$Z = \dfrac {(\bar{x} - \mu_0)}{(\dfrac {\sigma}{\sqrt{n}})}$
其中,$\bar{x}$ 为样本均值,$\mu_0$ 为假设的总体均值,$\sigma$ 为总体标准差,$n$ 为样本容量。
步骤 3:计算检验统计量的值
样本均值 $\bar{x} = 68L$,总体标准差 $\sigma = 6$,样本容量 $n = 49$,因此检验统计量为:
$Z = \dfrac {(68L - 800)}{(\dfrac {6}{\sqrt{49}})} = \dfrac {(68L - 800)}{(\dfrac {6}{7})} = \dfrac {(68L - 800)}{0.8571}$
$Z = \dfrac {(68L - 800)}{0.8571} = \dfrac {(-112)}{0.8571} = -130.67$
步骤 4:计算 $p$ 值
由于这是一个单尾检验,即对立假设为总体均值大于 800,因此需要计算标准正态分布 $Z$ 在检验统计量左侧的概率:
$p = P(Z < -130.67)$
由于 $Z$ 的值非常大,$p$ 值将非常接近于 0。
步骤 5:做出决策
由于 $p$ 值远小于显著性水平 $\alpha = 0.10$,因此拒绝零假设,即这批元件不合格。