题目
频率-|||-组距-|||-0.20-|||-0.10-|||-2a-|||-a -|||-o 19 21 23 25 27 29 31 增长长度(cm)为了解某养殖产品在某段时间内的生长情况,在该批产品中随机抽取了120件样本,测量其增长长度(单位:cm),经统计其增长长度均在区间[19,31]内,将其按[19,21),[21,23),[23,25),[25,27),[27,29),[29,31]分成6组,制成频率分布直方图,如图所示其中增长长度为27cm及以上的产品为优质产品.(Ⅰ)求图中a的值;(Ⅱ)已知这120件产品来自于A,B两个试验区,部分数据如下列联表: A试验区 B试验区 合计 优质产品 20 非优质产品 60 合计 将联表补充完整,并判断是否有99.9%的把握认为优质产品与A,B两个试验区有关系,并说明理由;下面的临界值表仅供参考: P(K2≥k) 0.15 0.10 0.05 0.025 0.010 0.005 0.001 k 2.072 2.706 3.841 5.024 6.635 7.879 10.828 (参考公式:(K^2)=((n{{(ad-bc))^2}})/((a+b)(c+d)(a+c)(b+d)),其中n=a+b+c+d)(Ⅲ)以样本的频率代表产品的概率,从这批产品中随机抽取4件进行分析研究,计算抽取的这4件产品中含优质产品的件数X的分布列和数学期望EX.
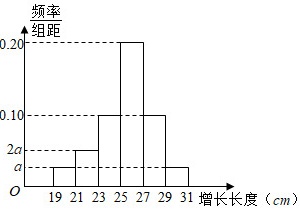 为了解某养殖产品在某段时间内的生长情况,在该批产品中随机抽取了120件样本,测量其增长长度(单位:cm),经统计其增长长度均在区间[19,31]内,将其按[19,21),[21,23),[23,25),[25,27),[27,29),[29,31]分成6组,制成频率分布直方图,如图所示其中增长长度为27cm及以上的产品为优质产品.
为了解某养殖产品在某段时间内的生长情况,在该批产品中随机抽取了120件样本,测量其增长长度(单位:cm),经统计其增长长度均在区间[19,31]内,将其按[19,21),[21,23),[23,25),[25,27),[27,29),[29,31]分成6组,制成频率分布直方图,如图所示其中增长长度为27cm及以上的产品为优质产品.(Ⅰ)求图中a的值;
(Ⅱ)已知这120件产品来自于A,B两个试验区,部分数据如下列联表:
| A试验区 | B试验区 | 合计 | |
| 优质产品 | 20 | ||
| 非优质产品 | 60 | ||
| 合计 |
下面的临界值表仅供参考:
| P(K2≥k) | 0.15 | 0.10 | 0.05 | 0.025 | 0.010 | 0.005 | 0.001 |
| k | 2.072 | 2.706 | 3.841 | 5.024 | 6.635 | 7.879 | 10.828 |
(Ⅲ)以样本的频率代表产品的概率,从这批产品中随机抽取4件进行分析研究,计算抽取的这4件产品中含优质产品的件数X的分布列和数学期望EX.
题目解答
答案
解:(Ⅰ)根据频率分布直方图数据,得:
2(a+a+2a+0.2+0.2)=1,
解得a=0.025.
(Ⅱ)根据频率分布直方图得:
样本中优质产品有120(0.100×2+0.025×2)=30,
列联表如下表所示:
∴${K^2}=\frac{{n{{(ad-bc)}^2}}}{(a+b)(c+d)(a+c)(b+d)}$=$\frac{120(10×30-20×60)^{2}}{70×50×30×90}$≈10.3<10.828,
∴没有99.9%的把握认为优质产品与A,B两个试验区有关系.
(Ⅲ)由已知从这批产品中随机抽取一件为优质产品的概率是$\frac{1}{4}$,
随机抽取4件中含有优质产品的件数X的可能取值为0,1,2,3,4,且X~B(4,$\frac{1}{4}$),
∴P(X=0)=${C}_{4}^{0}(\frac{3}{4})^{4}$=$\frac{81}{256}$,
P(X=1)=${C}_{4}^{1}(\frac{1}{4})(\frac{3}{4})^{3}=\frac{108}{256}$,
P(X=2)=${C}_{4}^{2}(\frac{1}{4})^{2}(\frac{3}{4})^{2}$=$\frac{54}{256}$,
P(X=3)=${C}_{4}^{3}(\frac{1}{4})^{3}(\frac{3}{4})$=$\frac{12}{256}$,
P(X=4)=${C}_{4}^{4}(\frac{1}{4})^{4}$=$\frac{1}{256}$,
∴X的分布列为:
EX=4×$\frac{1}{4}$=1.
2(a+a+2a+0.2+0.2)=1,
解得a=0.025.
(Ⅱ)根据频率分布直方图得:
样本中优质产品有120(0.100×2+0.025×2)=30,
列联表如下表所示:
| A试验区 | B试验区 | 合计 | |
| 优质产品 | 10 | 20 | 30 |
| 非优质产品 | 60 | 30 | 90 |
| 合计 | 70 | 50 | 120 |
∴没有99.9%的把握认为优质产品与A,B两个试验区有关系.
(Ⅲ)由已知从这批产品中随机抽取一件为优质产品的概率是$\frac{1}{4}$,
随机抽取4件中含有优质产品的件数X的可能取值为0,1,2,3,4,且X~B(4,$\frac{1}{4}$),
∴P(X=0)=${C}_{4}^{0}(\frac{3}{4})^{4}$=$\frac{81}{256}$,
P(X=1)=${C}_{4}^{1}(\frac{1}{4})(\frac{3}{4})^{3}=\frac{108}{256}$,
P(X=2)=${C}_{4}^{2}(\frac{1}{4})^{2}(\frac{3}{4})^{2}$=$\frac{54}{256}$,
P(X=3)=${C}_{4}^{3}(\frac{1}{4})^{3}(\frac{3}{4})$=$\frac{12}{256}$,
P(X=4)=${C}_{4}^{4}(\frac{1}{4})^{4}$=$\frac{1}{256}$,
∴X的分布列为:
| X | 0 | 1 | 2 | 3 | 4 |
| P | $\frac{81}{256}$ | $\frac{108}{256}$ | $\frac{54}{256}$ | $\frac{12}{256}$ | $\frac{1}{256}$ |
解析
步骤 1:求图中a的值
根据频率分布直方图,频率之和为1,因此可以列出方程求解a的值。
步骤 2:补充列联表并判断优质产品与试验区的关系
根据频率分布直方图,计算出优质产品和非优质产品的数量,然后补充列联表。使用卡方检验公式计算K^2值,与临界值表进行比较,判断是否有99.9%的把握认为优质产品与A,B两个试验区有关系。
步骤 3:计算X的分布列和数学期望
根据频率分布直方图,计算出优质产品的概率,然后使用二项分布计算X的分布列和数学期望。
根据频率分布直方图,频率之和为1,因此可以列出方程求解a的值。
步骤 2:补充列联表并判断优质产品与试验区的关系
根据频率分布直方图,计算出优质产品和非优质产品的数量,然后补充列联表。使用卡方检验公式计算K^2值,与临界值表进行比较,判断是否有99.9%的把握认为优质产品与A,B两个试验区有关系。
步骤 3:计算X的分布列和数学期望
根据频率分布直方图,计算出优质产品的概率,然后使用二项分布计算X的分布列和数学期望。