题目
某产品由甲、乙、丙三个厂家共同生产,生产份额为5:3:2,各厂的次品率分别为5:3:2,现随机抽取一件检验为次品,求该产品是乙厂生产的概率。
某产品由甲、乙、丙三个厂家共同生产,生产份额为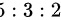 ,各厂的次品率分别为
,各厂的次品率分别为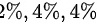 ,现随机抽取一件检验为次品,求该产品是乙厂生产的概率。
,现随机抽取一件检验为次品,求该产品是乙厂生产的概率。
题目解答
答案
甲厂生产次品的概率为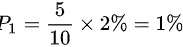 ,乙厂生产次品的概率为
,乙厂生产次品的概率为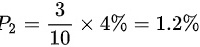 ,丙厂生产次品的概率为
,丙厂生产次品的概率为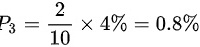 ,
,
次品是乙厂生产的条件概率为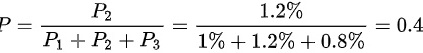
解析
考查要点:本题主要考查条件概率的应用,特别是利用全概率公式和贝叶斯定理解决实际问题的能力。
解题核心思路:
- 确定各厂的生产概率:根据生产份额比例转化为概率。
- 计算各厂的次品概率:生产概率乘以次品率。
- 求总次品概率:将各厂的次品概率相加。
- 应用条件概率公式:用乙厂的次品概率除以总次品概率,得到所求结果。
破题关键点:
- 正确转化生产份额为概率(如甲厂概率为$\frac{5}{10}$)。
- 区分“次品率”与“次品概率”:次品率是条件概率,需与生产概率相乘。
- 全概率公式的应用:总次品概率是各厂次品概率的加权和。
步骤1:计算各厂的生产概率
生产份额为5:3:2,总份额为$5+3+2=10$,因此:
- 甲厂生产概率:$\frac{5}{10}=0.5$
- 乙厂生产概率:$\frac{3}{10}=0.3$
- 丙厂生产概率:$\frac{2}{10}=0.2$
步骤2:计算各厂的次品概率
各厂次品率分别为2%、4%、4%,因此:
- 甲厂次品概率:$0.5 \times 2\% = 1\%$
- 乙厂次品概率:$0.3 \times 4\% = 1.2\%$
- 丙厂次品概率:$0.2 \times 4\% = 0.8\%$
步骤3:求总次品概率
总次品概率为各厂次品概率之和:
$P(\text{次品}) = 1\% + 1.2\% + 0.8\% = 3\%$
步骤4:计算乙厂的条件概率
根据条件概率公式:
$P(\text{乙厂} \mid \text{次品}) = \frac{P(\text{次品} \mid \text{乙厂}) \cdot P(\text{乙厂})}{P(\text{次品})} = \frac{1.2\%}{3\%} = 0.4$