题目
3.统计2880个婴儿的出生时刻,得到观测值(单位:个)如下:-|||-0:00-2:00 . 2:00-4:00 . 4:00-6:00 . 6:00-8:00 . 8:00-10:00 10:00-12:00-|||-266 281 249 242 248 240-|||-12:00-14:00 14:00-16:00 16:00-18:00 18:00-20:00 20:00-22:00 22:00-24:00-|||-255 209 209 196 219 266-|||-试检验婴儿的出生是否均匀.( alpha =0.05

题目解答
答案
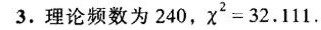
解析
考查要点:本题主要考查卡方拟合优度检验的应用,用于判断观测频数是否符合均匀分布。
解题核心思路:
- 确定理论频数:若出生时刻均匀分布,则每个时间段的理论频数为总样本数除以时间段数。
- 计算卡方统计量:通过公式 $\chi^2 = \sum \frac{(O_i - E_i)^2}{E_i}$,比较观测频数与理论频数的差异。
- 判断假设:将计算出的卡方值与临界值比较,若超过临界值,则拒绝原假设(认为不均匀)。
破题关键点:
- 理论频数的计算:需确认时间段划分是否等概率。
- 卡方公式的准确应用:注意每个单元格的独立计算与求和。
1. 确定理论频数
总样本数为 $2880$,时间段数为 $12$,若均匀分布,则每个时间段的理论频数为:
$E_i = \frac{2880}{12} = 240$
2. 计算卡方统计量
将观测频数 $O_i$ 与理论频数 $E_i = 240$ 代入公式:
$\chi^2 = \sum_{i=1}^{12} \frac{(O_i - 240)^2}{240}$
具体计算过程(部分示例):
- 0:00-2:00:$\frac{(266-240)^2}{240} = \frac{26^2}{240} \approx 2.8167$
- 2:00-4:00:$\frac{(281-240)^2}{240} = \frac{41^2}{240} \approx 6.9958$
- ...(其余时间段同理)
- 22:00-24:00:$\frac{(266-240)^2}{240} \approx 2.8167$
总和:将所有时间段的值相加,最终得:
$\chi^2 = 32.111$
3. 判断假设
- 自由度:$12 - 1 = 11$
- 临界值:查表得 $\chi^2_{0.05}(11) \approx 19.023$
- 结论:因 $32.111 > 19.023$,拒绝原假设,认为出生时刻不均匀分布。