题目
100件产品中有50件一等品、30件二等品、20件三等品。从中任取5件,以X,Y分别表示取出的5件中一等品、二等品的件数,在以下情况下求(X,Y)的联合分布列:(1)不放回抽取;(2)有放回抽取.
100件产品中有50件一等品、30件二等品、20件三等品。从中任取5件,以X,Y分别表示取出的5件中一等品、二等品的件数,在以下情况下求(X,Y)的联合分布列:
(1)不放回抽取;
(2)有放回抽取.
题目解答
答案
解:
设取出的5件中一等品、二等品的件数分别为:i,j(i,j=0,1,2,3,4,5)且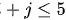
(1)根据题意得: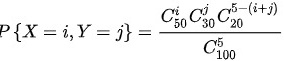
∴代入所有数据,可得(X,Y)的联合分布列:
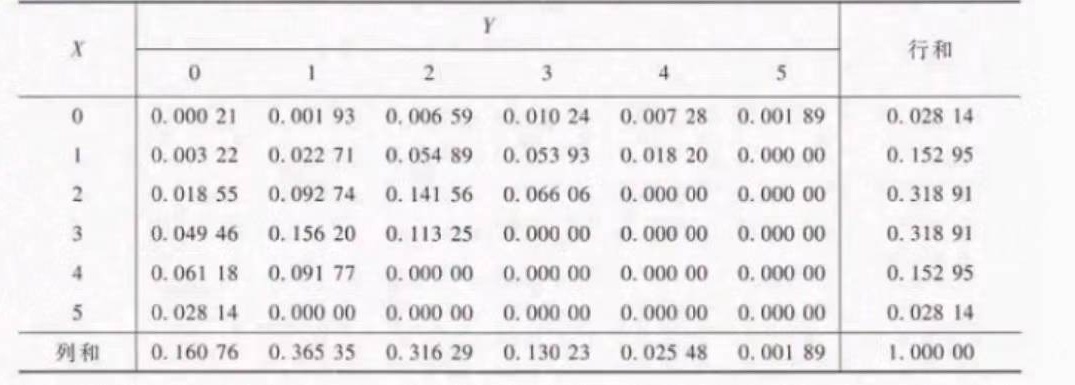
(2)根据题意可得:
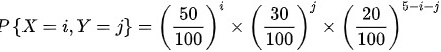
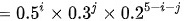
(i,j=0,1,2,3,4,5,且).
综上,我们分别求出两种情况下(X,Y)的联合分布列。
解析
考查要点:本题主要考查超几何分布和多项分布的应用,涉及不放回抽样与有放回抽样的联合分布列求解。
解题核心思路:
- 不放回抽样:属于多重超几何分布,需计算从不同类别中选取指定数量的组合数之比。
- 有放回抽样:属于多项分布,需利用独立事件的概率乘法公式结合排列组合计算。
破题关键点:
- 分类讨论:明确两种抽样方式对应的概率模型。
- 约束条件:始终满足一等品数$X$、二等品数$Y$及三等品数之和为5,即$i + j \leq 5$。
(1) 不放回抽取
概率公式推导
从100件产品中不放回抽取5件,联合概率为:
$P\{X=i, Y=j\} = \frac{{C}_{50}^{i} {C}_{30}^{j} {C}_{20}^{5-i-j}}{{C}_{100}^{5}}$
其中,$i, j$满足$i + j \leq 5$,且$5 - i - j \geq 0$。
关键步骤
- 组合数计算:分别从一等品、二等品、三等品中选取$i$、$j$、$5-i-j$件。
- 分母统一:所有可能的抽取方式为${C}_{100}^{5}$。
- 约束条件:若$5 - i - j > 20$或参数为负数,则对应概率为0。
(2) 有放回抽取
概率公式推导
每次抽取独立,联合概率为多项分布:
$P\{X=i, Y=j\} = \frac{5!}{i!j!(5-i-j)!} \left(0.5\right)^i \left(0.3\right)^j \left(0.2\right)^{5-i-j}$
其中,$i, j$满足$i + j \leq 5$。
关键步骤
- 多项式系数:$\frac{5!}{i!j!(5-i-j)!}$表示排列方式数。
- 概率乘积:各等品概率的独立乘积。
- 约束条件:若$5 - i - j < 0$,则概率为0。