25、35、70。(f) 画出数据的盒图。略。(g) 分位数—分位数图与分位数图的不同之处是什么?分位数图是一种用来展示数据值低于或等于在一个单变量分布中独立的变量的粗略百分比。这样,他可以展示所有数的分位数信息,而为独立变量测得的值(纵轴)相对于它们的分位数(横轴)被描绘出来。但分位数—分位数图用纵轴表示一种单变量分布的分位数,用横轴表示另一单变量分布的分位数。两个坐标轴显示它们的测量值相应分布的值域,且点按照两种分布分位数值展示。一条线(y=x)可画到图中,以增加图像的信息。落在该线以上的点表示在y 轴上显示的值的分布比x 轴的相应的等同分位数对应的值的分布高。反之,对落在该线以下的点则低。2.3设给定的数据集已经分组到区间。这些区间和对应频率如下所示:A. ge frequency B. 1-5 200 C. 6-15 450 D. 16-20 300 E. 21-50 1500 F. 51-80 700 G. 80-110 44计算该数据的近似中位数。2.4假设医院对18个随机挑选的成年人检查年龄和身体肥胖,得到如下结果:ge 23 23 27 27 39 41 47 49 50at 9.5 26.5 7.8 17.8 31.4 25.9 27.4 27.2 31.2ge 52 54 54 56 57 58 58 60 61at 34.6 42.5 28.8 33.4 30.2 34.1 32.9 41.2 35.7计算age和%fat的均值,中位数和标准差。绘制age和%fat的盒图。绘制基于这两个变量的散点图和q-q图。age的平均值-|||-l (23+23+27+27+39+41+47+45+50+52+54+504+56+57+58+58+50-|||-+61/8-|||-=46.44-|||-%fat的平均值-|||-+33.4+30.2+34.1+32.9+41.2+35.7)/18-|||-=28.78-|||-age的中位数是50和52的平均值是51-|||-%fat的中位数是28.8和30.2的平均值是29.5age的平均值-|||-l (23+23+27+27+39+41+47+45+50+52+54+504+56+57+58+58+50-|||-+61/8-|||-=46.44-|||-%fat的平均值-|||-+33.4+30.2+34.1+32.9+41.2+35.7)/18-|||-=28.78-|||-age的中位数是50和52的平均值是51-|||-%fat的中位数是28.8和30.2的平均值是29.5age的平均值-|||-l (23+23+27+27+39+41+47+45+50+52+54+504+56+57+58+58+50-|||-+61/8-|||-=46.44-|||-%fat的平均值-|||-+33.4+30.2+34.1+32.9+41.2+35.7)/18-|||-=28.78-|||-age的中位数是50和52的平均值是51-|||-%fat的中位数是28.8和30.2的平均值是29.5age的平均值-|||-l (23+23+27+27+39+41+47+45+50+52+54+504+56+57+58+58+50-|||-+61/8-|||-=46.44-|||-%fat的平均值-|||-+33.4+30.2+34.1+32.9+41.2+35.7)/18-|||-=28.78-|||-age的中位数是50和52的平均值是51-|||-%fat的中位数是28.8和30.2的平均值是29.5三ge包括如下值(以递增序):13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70.使用蒌3的箱,用箱均值光滑以上数据。说明你的步骤,讨论这种技术对缎带定数据的效果。如何确定该数据中的离群点?还有什么其他方法来光滑数据?使用分箱均值光滑对以上数据进行光滑,箱的深度为3。解释你的步骤。评述对于给定的数据,该技术的效果。用箱深度为3 的分箱均值光滑对以上数据进行光滑需要以下步骤:? 步骤1:对数据排序。(因为数据已被排序,所以此时不需要该步骤。)? 步骤2:将数据划分到大小为3 的等频箱中。箱1:13,15,16 箱2:16,19,20 箱3:20,21,22箱4:22,25,25 箱5:25,25,30 箱6:33,33,35箱7:35,35,35 箱8:36,40,45 箱9:46,52,70? 步骤3:计算每个等频箱的算数均值。? 步骤4:用各箱计算出的算数均值替换每箱中的每个值。箱1:44/3,44/3,44/3 箱2:55/3,55/3,55/3 箱3:21,21,21箱4:24,24,24 箱5:80/3,80/3,80/3 箱6:101/3,101/3,101/3箱7:35,35,35 箱8:121/3,121/3,121/3 箱9:56,56,56如何确定数据中的离群点?聚类的方法可用来将相似的点分成组或“簇”,并检测离群点。落到簇的集外的值可以被视为离群点。作为选择,一种人机结合的检测可被采用,而计算机用一种事先决定的数据分布来区分可能的离群点。这些可能的离群点能被用人工轻松的检验,而不必检查整个数据集。对于数据光滑,还有哪些其他方法?其它可用来数据光滑的方法包括别的分箱光滑方法,如中位数光滑和箱边界光滑。作为选择,等宽箱可被用来执行任何分箱方式,其中每个箱中的数据范围均是常量。除了分箱方法外,可以使用回归技术拟合成函数来光滑数据,如通过线性或多线性回归。分类技术也能被用来对概念分层,这是通过将低级概念上卷到高级概念来光滑数据。3.5如下规范化方法的值域是什么?最小-最大规范化Z分数规范化。Z分数规范化,使用均值绝对念头而不是标准差。小数定标规范化。min-max 规范化。[new_min, new_max]。z-score 规范化。[(old_min-mean)/σ,(old_max-mean)/σ],总的来说,对于所有可能的数据集的值域是(-∞,+∞)。小数定标规范化。值域是(-1.0,1.0)。3.6使用如下方法规范化如下数据组:200,300,400,600,1000min=0,max=1,最小-最大规范化。Z分数规范化。Z分数规范化,使用均值绝对偏差而不是标准差。小数定标规范化。min-max 规范化。[new_min, new_max]。z-score 规范化。[(old_min-mean)/σ,(old_max-mean)/σ],总的来说,对于所有可能的数据集的值域是(-∞,+∞)。小数定标规范化。值域是(-1.0,1.0)。4.1试述对于多个异构信息源的集成,为什么许多公司更愿意使用更 新驱动的方法(构造和使用数据仓库),而不是查询驱动的方法(使用包装程序和集成程序)。描述一些查询驱动方法比更 新驱动方法更可取的情况。答: 因为对于多个异种, 查询驱动方法需要复杂的信息过滤和集成处理, 并且与局部数据源上的处理竞争资源,是一种低效的方法,并且对于频繁的查询,特别是需 要聚集操作的查询,开销很大。而更新驱动方法为集成的异种数据库系统带来了高性能,因 为数据被处理和重新组织到一个语义一致的数据存储中, 进行查询的同时并不影响局部数据 源上进行的处理。此外,数据仓库存储并集成历史信息,支持复杂的多维查询。4.2简略比较以下概念,可以用例子解释你的观点。雪花模式、事实星座、星网查询模型。数据清理、数据变换、刷新。发现驱动的立方体、多特征冷言冷语腐朽 、虚拟仓库雪花形模式、事实星座形、星形网查询模型。 答:雪花形和事实星形模式都是变形的星形模式,都是由事实表和维表组成,雪花形模式的维表都是规范化的;而事实星座形的某几个事实表可能会共享一些维表;星形网查询模型是一个查询模型而不是模式模型,它是由中心点发出的涉嫌组成,其中每一条射线代表一个维的概念分层。数据清理、数据变换、刷新 答:数据清理是指检测数据中的错误,可能时订正它们;数据变换是将数据由遗产或宿主格式转换成数据仓库格式;刷新是指传播由数据源到数据仓库的更新。te,spectator,location,game,2个度量——count和charge,其中charge是观众在给定的日期观看节目的费用。观众可以是学生、成年人或老年人,每类观众有不同的收费标准。画出该数据仓库的星形模式图[date,spectator,location,game]开始,为列出2010年学生观众在GM_place的总付费,应当执行哪些OLAP操作?对于数据仓库,位图是有用的。以该数据立方体为例,简略讨论使用位图索引结构的优点和问题。priori算法使用子集支持度性质的先验知识。证明频繁项集的所有非空子集一定也是频繁的。证明项集s的任意非空子集s’的支持度至少与s的支持度一样大。给定频繁项集l和l的子集s,证明规则“s=>l(s’)”的置信度不可能大于“s=>l(s)”的置信度。其中,s’是s的子集priori算法的一种变形将事务数据库D中的事务划分成n个不重叠的分区。证明在D中频繁的项集至少在D的一个分区中是频繁的。
25、35、70。
(f) 画出数据的盒图。
略。
(g) 分位数—分位数图与分位数图的不同之处是什么?
分位数图是一种用来展示数据值低于或等于在一个单变量分布中独立的变
量的粗略百分比。这样,他可以展示所有数的分位数信息,而为独立变量测得的
值(纵轴)相对于它们的分位数(横轴)被描绘出来。
但分位数—分位数图用纵轴表示一种单变量分布的分位数,用横轴表示另一
单变量分布的分位数。两个坐标轴显示它们的测量值相应分布的值域,且点按照
两种分布分位数值展示。一条线(y=x)可画到图中,以增加图像的信息。落在
该线以上的点表示在y 轴上显示的值的分布比x 轴的相应的等同分位数对应的值
的分布高。反之,对落在该线以下的点则低。
2.3设给定的数据集已经分组到区间。这些区间和对应频率如下所示:
A. ge frequencyB. 1-5 200
C. 6-15 450
D. 16-20 300
E. 21-50 1500
F. 51-80 700
G. 80-110 44
计算该数据的近似中位数。
2.4假设医院对18个随机挑选的成年人检查年龄和身体肥胖,得到如下结果:
ge 23 23 27 27 39 41 47 49 50
at 9.5 26.5 7.8 17.8 31.4 25.9 27.4 27.2 31.2
ge 52 54 54 56 57 58 58 60 61
at 34.6 42.5 28.8 33.4 30.2 34.1 32.9 41.2 35.7
计算age和%fat的均值,中位数和标准差。
绘制age和%fat的盒图。
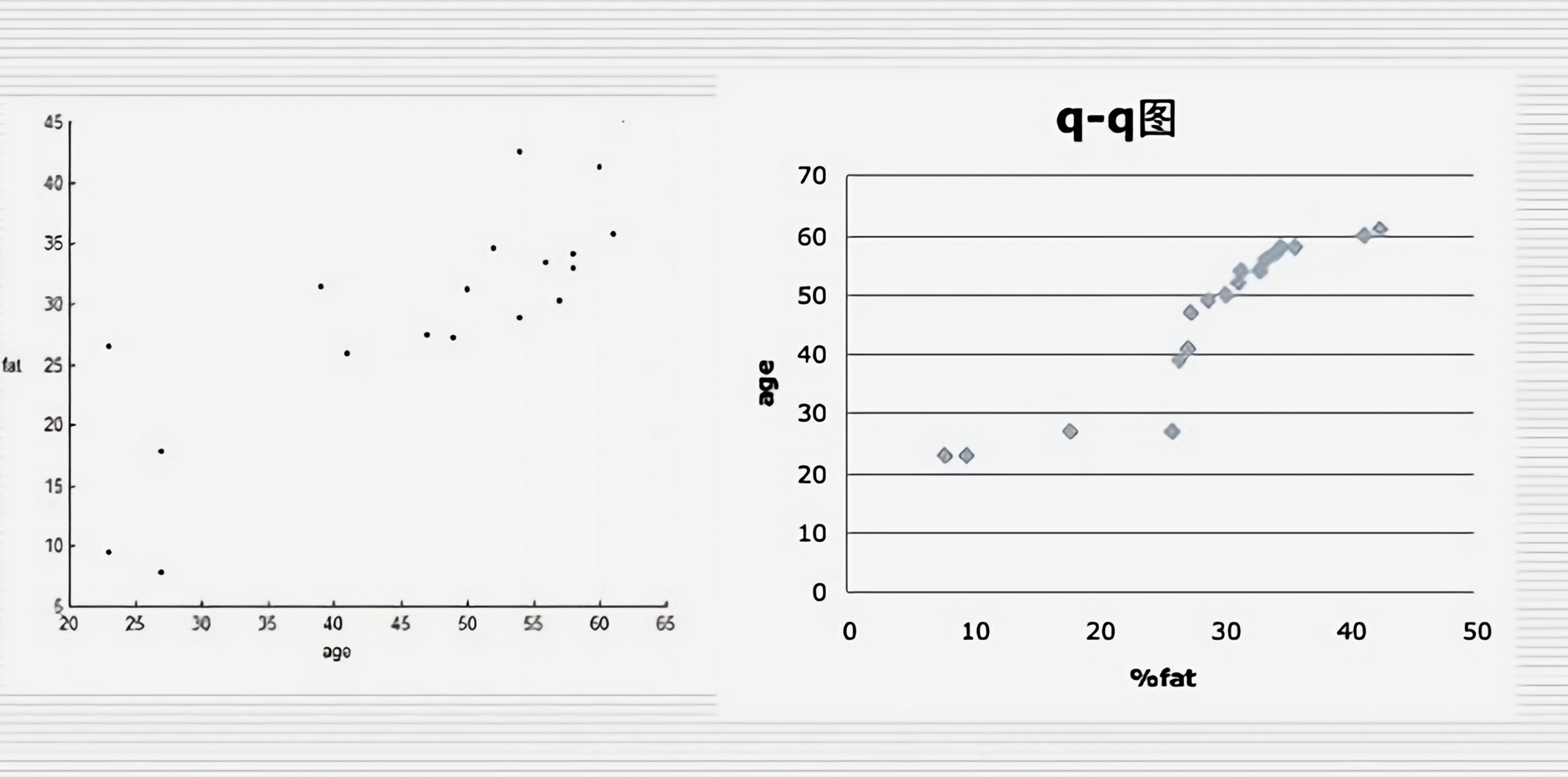
绘制基于这两个变量的散点图和q-q图。

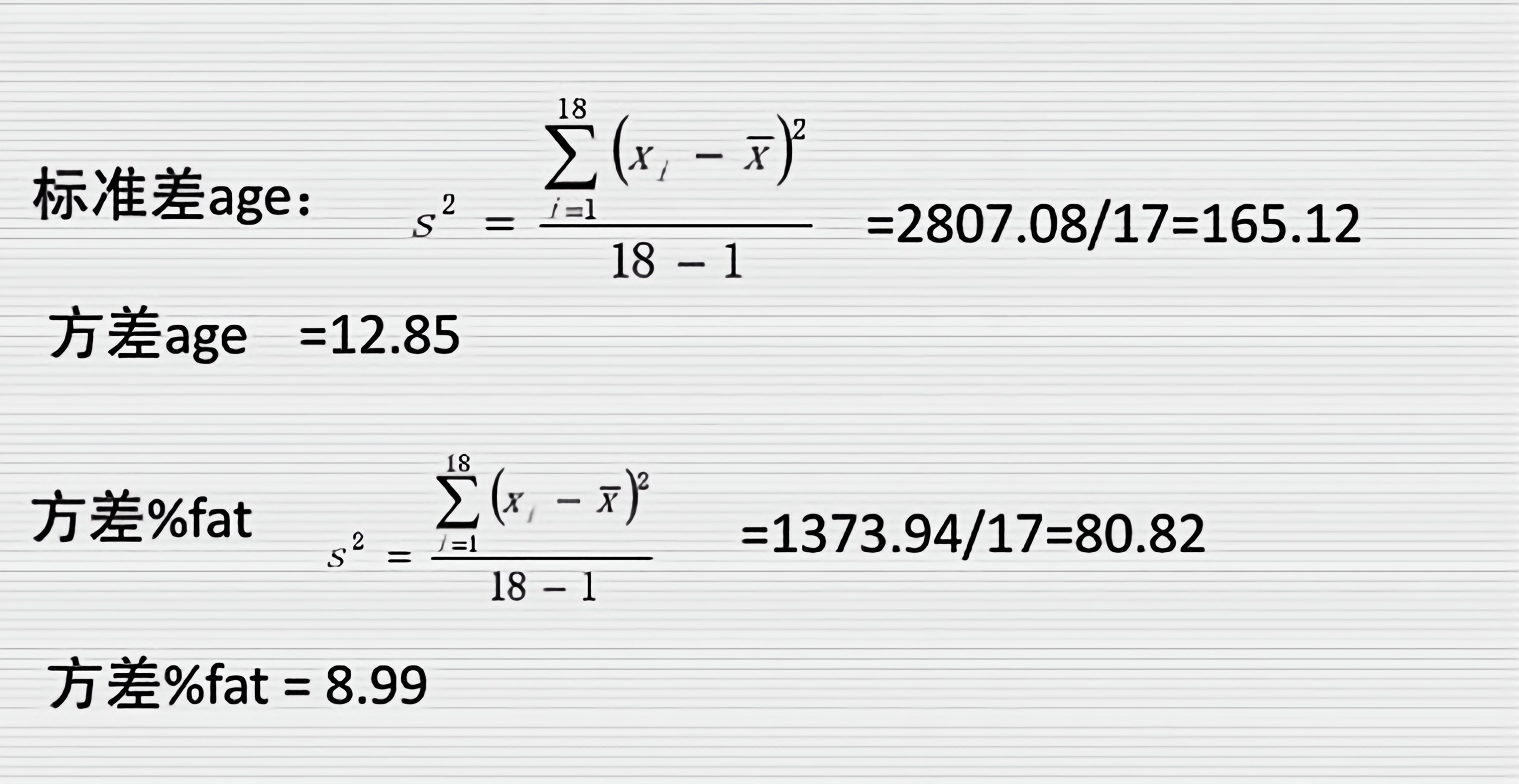
三
ge包括如下值(以递增序):13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70.
使用蒌3的箱,用箱均值光滑以上数据。说明你的步骤,讨论这种技术对缎带定数据的效果。
如何确定该数据中的离群点?
还有什么其他方法来光滑数据?
使用分箱均值光滑对以上数据进行光滑,箱的深度为3。解释你的步骤。
评述对于给定的数据,该技术的效果。
用箱深度为3 的分箱均值光滑对以上数据进行光滑需要以下步骤:
? 步骤1:对数据排序。(因为数据已被排序,所以此时不需要该步骤。)
? 步骤2:将数据划分到大小为3 的等频箱中。
箱1:13,15,16 箱2:16,19,20 箱3:20,21,22
箱4:22,25,25 箱5:25,25,30 箱6:33,33,35
箱7:35,35,35 箱8:36,40,45 箱9:46,52,70
? 步骤3:计算每个等频箱的算数均值。
? 步骤4:用各箱计算出的算数均值替换每箱中的每个值。
箱1:44/3,44/3,44/3 箱2:55/3,55/3,55/3 箱3:21,21,21
箱4:24,24,24 箱5:80/3,80/3,80/3 箱6:101/3,101/3,101/3
箱7:35,35,35 箱8:121/3,121/3,121/3 箱9:56,56,56
如何确定数据中的离群点?
聚类的方法可用来将相似的点分成组或“簇”,并检测离群点。落到簇的集
外的值可以被视为离群点。作为选择,一种人机结合的检测可被采用,而计算机
用一种事先决定的数据分布来区分可能的离群点。这些可能的离群点能被用人工
轻松的检验,而不必检查整个数据集。
对于数据光滑,还有哪些其他方法?
其它可用来数据光滑的方法包括别的分箱光滑方法,如中位数光滑和箱边界
光滑。作为选择,等宽箱可被用来执行任何分箱方式,其中每个箱中的数据范围
均是常量。除了分箱方法外,可以使用回归技术拟合成函数来光滑数据,如通过
线性或多线性回归。分类技术也能被用来对概念分层,这是通过将低级概念上卷
到高级概念来光滑数据。
3.5如下规范化方法的值域是什么?
最小-最大规范化
Z分数规范化。
Z分数规范化,使用均值绝对念头而不是标准差。
小数定标规范化。
min-max 规范化。
[new_min, new_max]。
z-score 规范化。
[(old_min-mean)/σ,(old_max-mean)/σ],总的来说,对于所有可能
的数据集的值域是(-∞,+∞)。
小数定标规范化。
值域是(-1.0,1.0)。
3.6使用如下方法规范化如下数据组:200,300,400,600,1000
min=0,max=1,最小-最大规范化。
Z分数规范化。
Z分数规范化,使用均值绝对偏差而不是标准差。
小数定标规范化。
min-max 规范化。
[new_min, new_max]。
z-score 规范化。
[(old_min-mean)/σ,(old_max-mean)/σ],总的来说,对于所有可能
的数据集的值域是(-∞,+∞)。
小数定标规范化。
值域是(-1.0,1.0)。
4.1试述对于多个异构信息源的集成,为什么许多公司更愿意使用更 新驱动的方法(构造和使用数据仓库),而不是查询驱动的方法(使用包装程序和集成程序)。描述一些查询驱动方法比更 新驱动方法更可取的情况。
答: 因为对于多个异种, 查询驱动方法需要复杂的信息过滤和集成处理, 并且与局部数据源上的处理竞争资源,是一种低效的方法,并且对于频繁的查询,特别是需 要聚集操作的查询,开销很大。而更新驱动方法为集成的异种数据库系统带来了高性能,因 为数据被处理和重新组织到一个语义一致的数据存储中, 进行查询的同时并不影响局部数据 源上进行的处理。此外,数据仓库存储并集成历史信息,支持复杂的多维查询。
4.2简略比较以下概念,可以用例子解释你的观点。
雪花模式、事实星座、星网查询模型。
数据清理、数据变换、刷新。
发现驱动的立方体、多特征冷言冷语腐朽 、虚拟仓库
雪花形模式、事实星座形、星形网查询模型。 答:雪花形和事实星形模式都是变形的星形模式,都是由事实表和维表组成,雪花形模式的维表都是规范化的;而事实星座形的某几个事实表可能会共享一些维表;星形网查询模型是一个查询模型而不是模式模型,它是由中心点发出的涉嫌组成,其中每一条射线代表一个维的概念分层。
数据清理、数据变换、刷新 答:数据清理是指检测数据中的错误,可能时订正它们;数据变换是将数据由遗产或宿主格式转换成数据仓库格式;刷新是指传播由数据源到数据仓库的更新。
te,spectator,location,game,2个度量——count和charge,其中charge是观众在给定的日期观看节目的费用。观众可以是学生、成年人或老年人,每类观众有不同的收费标准。
画出该数据仓库的星形模式图
[date,spectator,location,game]开始,为列出2010年学生观众在GM_place的总付费,应当执行哪些OLAP操作?
对于数据仓库,位图是有用的。以该数据立方体为例,简略讨论使用位图索引结构的优点和问题。
priori算法使用子集支持度性质的先验知识。
证明频繁项集的所有非空子集一定也是频繁的。
证明项集s的任意非空子集s’的支持度至少与s的支持度一样大。
给定频繁项集l和l的子集s,证明规则“s=>l(s’)”的置信度不可能大于“s=>l(s)”的置信度。其中,s’是s的子集
priori算法的一种变形将事务数据库D中的事务划分成n个不重叠的分区。证明在D中频繁的项集至少在D的一个分区中是频繁的。
题目解答
答案
Age frequency 1-5 200 6-15 450 16-20 300 21-50 1500 51-80 700 80-110 44 计算该数据的近似中位数。 2.4 假设医院对 18 个随机挑选的成年人检查年龄和身体肥胖,得到如下结果: Age 23 23 27 27 39 41 47 49 50 Fat 9.5 26.5 7.8 17.8 31.4 25.9 27.4 27.2 31.2 Age 52 54 54 56 57 58 58 60 61 Fat 34.6 42.5 28.8 33.4 30.2 34.1 32.9 41.2 35.7 计算 age 和 %fat 的均值,中位数和标准差。 绘制 age 和 %fat 的盒图。 绘制基于这两个变量的散点图和 q-q 图。 三 3.3 在习题 2.2 中, age 包括如下值(以递增序): 13 , 15 , 16 , 16 , 19 , 20 , 20 , 21 , 22 , 22 , 25 , 25 , 25 , 25 , 30 , 33 , 33 , 35 , 35 , 35 , 35 , 36 , 40 , 45 , 46 , 52 , 70. 使用蒌 3 的箱,用箱均值光滑以上数据。说明你的步骤,讨论这种技术对缎带定数据的效果。 如何确定该数据中的离群点? 还有什么其他方法来光滑数据? 3.5 如下规范化方法的值域是什么? 最小 - 最大规范化 Z 分数规范化。 Z 分数规范化,使用均值绝对念头而不是标准差。 小数定标规范化。 3.6 使用如下方法规范化如下数据组: 200 , 300 , 400 , 600 , 1000 min=0,max=1 ,最小 - 最大规范化。 Z 分数规范化。 Z 分数规范化,使用均值绝对偏差而不是标准差。 小数定标规范化。 4.1 试述对于多个异构信息源的集成,为什么许多公司更愿意使用更 新驱动的方法(构造和使用数据仓库),而不是查询驱动的方法(使用包装程序和集成程序)。描述一些查询驱动方法比更 新驱动方法更可取的情况。 答: 因为对于多个异种, 查询驱动方法需要复杂的信息过滤和集成处理, 并且与局部数据源上的处理竞争资源,是一种低效的方法,并且对于频繁的查询,特别是需 要聚集操作的查询,开销很大。而更新驱动方法为集成的异种数据库系统带来了高性能,因 为数据被处理和重新组织到一个语义一致的数据存储中, 进行查询的同时并不影响局部数据 源上进行的处理。此外,数据仓库存储并集成历史信息,支持复杂的多维查询。 4.2 简略比较以下概念,可以用例子解释你的观点。 雪花模式、事实星座、星网查询模型。 数据清理、数据变换、刷新。 发现驱动的立方体、多特征冷言冷语腐朽 、虚拟仓库 4.5 假定数据仓库包含 4 个维—— date,spectator,location,game , 2 个度量—— count 和 charge ,其中 charge 是观众在给定的日期观看节目的费用。观众可以是学生、成年人或老年人,每类观众有不同的收费标准。 画出该数据仓库的星形模式图 由基本方体【 date,spectator,location,game 】开始,为列出 2010 年学生观众在 GM_place 的总付费,应当执行哪些 OLAP 操作? 对于数据仓库,位图是有用的。以该数据立方体为例,简略讨论使用位图索引结构的优点和问题。 6.3 Apriori 算法使用子集支持度性质的先验知识。 证明频繁项集的所有非空子集一定也是频繁的。 证明项集 s 的任意非空子集 s ’ 的支持度至少与 s 的支持度一样大。 给定频繁项集 l 和 l 的子集 s ,证明规则“ s=>l(s ’ ) ”的置信度不可能大于“ s=>l(s) ”的置信度。其中, s ’ 是 s 的子集 Apriori 算法的一种变形将事务数据库 D 中的事务划分成 n 个不重叠的分区。证明在 D 中频繁的项集至少在 D 的一个分区中是频繁的。