关于假设检验,下列( )项说法是正确的A. 单侧检验优于双侧检验B. 无效假设与备择假设均应分单,双侧检验两种形式C. 检验结果若P值大于0.05,则接受OH犯第一类错误的可能性很小D. 同一检验水准下,单侧检验比双侧检验更易得到接受OH的结论E. 结果有统计学意义则说明其有实际意义
关于假设检验,下列( )项说法是正确的
A. 单侧检验优于双侧检验
B. 无效假设与备择假设均应分单,双侧检验两种形式
C. 检验结果若P值大于0.05,则接受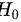 犯第一类错误的可能性很小
犯第一类错误的可能性很小
D. 同一检验水准下,单侧检验比双侧检验更易得到接受的结论
E. 结果有统计学意义则说明其有实际意义
题目解答
答案
A. 单侧检验优于双侧检验
单侧检验和双侧检验是根据备择假设的方向性来选择的,不是说哪一种检验本身就优于另一种。单侧检验只考虑总体参数大于或小于某个值的可能性,而双侧检验考虑总体参数不等于某个值的可能性。如果事先有明确的方向性假设,可以选择单侧检验,否则应该选择双侧检验。 故错误
B. 无效假设与备择假设均应分单,双侧检验两种形式
无效假设是指要被检验的假设,通常表示为总体参数等于某个值;备择假设是指与无效假设相反的假设,通常表示为总体参数大于、小于或不等于某个值。根据备择假设的形式,可以将假设检验分为单侧检验和双侧检验两种。单侧检验是指备择假设为单边区间的情况,例如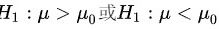 μ_0或H_1:μ<μ_0" data-width="224" data-height="29" data-size="2643" data-format="png" style="max-width:100%">;双侧检验是指备择假设为双边区间的情况,例如
μ_0或H_1:μ<μ_0" data-width="224" data-height="29" data-size="2643" data-format="png" style="max-width:100%">;双侧检验是指备择假设为双边区间的情况,例如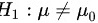 。 故正确
。 故正确
C. 检验结果若P值大于0.05,则接受H_0犯第一类错误的可能性很小
P值是指在无效假设成立的前提下,得到观察值或更极端情况出现的概率。P值越小,说明观察值与无效假设之间的矛盾程度越大,越有理由拒绝无效假设;P值越大,说明观察值与无效假设之间的矛盾程度越小,越没有理由拒绝无效假设。但是P值并不等于犯错误的概率,不能说P值大于0.05就一定接受,也不能说P值小于0.05就一定拒绝。犯错误的概率取决于事先确定的显著性水平α,α表示拒绝时犯第一类错误(弃真)的最大容许概率。如果P值小于α,就拒绝;如果P值大于α,就不拒绝。但是不拒绝H_0并不意味着接受,因为还有可能犯第二类错误(取伪),即在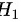 成立时没有拒绝。故选项错误
成立时没有拒绝。故选项错误
D. 同一检验水准下,单侧检验比双侧检验更易得到接受的结论
同一检验水准下,单侧检验比双侧检验更易得到拒绝的结论,而不是接受的结论。这是因为单侧检验的拒绝域只在一个方向上,而双侧检验的拒绝域在两个方向上,所以单侧检验的临界值比双侧检验的临界值更容易达到。例如,如果α=0.05,那么单侧检验的临界值为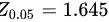 ,而双侧检验的临界值为
,而双侧检验的临界值为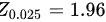 ,显然后者更难达到。 故错误
,显然后者更难达到。 故错误
E. 结果有统计学意义则说明其有实际意义
结果有统计学意义是指观察值与无效假设之间存在显著差异,即P值小于α,拒绝。但是这并不一定说明结果有实际意义,因为有可能观察值与无效假设之间的差异很小,只是由于样本量很大而导致统计显著。实际意义是指观察值与无效假设之间的差异在实际应用中具有重要价值,需要根据具体问题和领域来判断。例如,在医学研究中,某种药物对某种疾病的治愈率提高了0.1%,这可能是统计显著的,但不一定是实际显著的。故错误
故答案为B
解析
单侧检验和双侧检验是根据备择假设的方向性来选择的。单侧检验只考虑总体参数大于或小于某个值的可能性,而双侧检验考虑总体参数不等于某个值的可能性。如果事先有明确的方向性假设,可以选择单侧检验,否则应该选择双侧检验。
步骤 2:理解无效假设与备择假设
无效假设是指要被检验的假设,通常表示为总体参数等于某个值;备择假设是指与无效假设相反的假设,通常表示为总体参数大于、小于或不等于某个值。根据备择假设的形式,可以将假设检验分为单侧检验和双侧检验两种。
步骤 3:理解P值与犯错误的概率
P值是指在无效假设成立的前提下,得到观察值或更极端情况出现的概率。P值越小,说明观察值与无效假设之间的矛盾程度越大,越有理由拒绝无效假设;P值越大,说明观察值与无效假设之间的矛盾程度越小,越没有理由拒绝无效假设。但是P值并不等于犯错误的概率,不能说P值大于0.05就一定接受H0,也不能说P值小于0.05就一定拒绝H0。犯错误的概率取决于事先确定的显著性水平α,α表示拒绝H0时犯第一类错误(弃真)的最大容许概率。如果P值小于α,就拒绝H0;如果P值大于α,就不拒绝H0。但是不拒绝H0并不意味着接受H0,因为还有可能犯第二类错误(取伪),即在H1成立时没有拒绝H0。
步骤 4:理解单侧检验与双侧检验的临界值
同一检验水准下,单侧检验比双侧检验更易得到拒绝H0的结论,而不是接受H0的结论。这是因为单侧检验的拒绝域只在一个方向上,而双侧检验的拒绝域在两个方向上,所以单侧检验的临界值比双侧检验的临界值更容易达到。例如,如果α=0.05,那么单侧检验的临界值为${Z}_{0.05}=1.645$,而双侧检验的临界值为${2}_{0.025}=1.96$,显然后者更难达到。
步骤 5:理解统计学意义与实际意义
结果有统计学意义是指观察值与无效假设之间存在显著差异,即P值小于α,拒绝H0。但是这并不一定说明结果有实际意义,因为有可能观察值与无效假设之间的差异很小,只是由于样本量很大而导致统计显著。实际意义是指观察值与无效假设之间的差异在实际应用中具有重要价值,需要根据具体问题和领域来判断。例如,在医学研究中,某种药物对某种疾病的治愈率提高了0.1%,这可能是统计显著的,但不一定是实际显著的。