题目
设((X)_(1),(X)_(2),(X)_(3)... ... (X)_(25))是来自正态总体((X)_(1),(X)_(2),(X)_(3)... ... (X)_(25))的样本,((X)_(1),(X)_(2),(X)_(3)... ... (X)_(25))是样本均值,则((X)_(1),(X)_(2),(X)_(3)... ... (X)_(25))注:((X)_(1),(X)_(2),(X)_(3)... ... (X)_(25))A.0.4514B.0.5441C.0.4415D.0.5414
设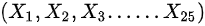 是来自正态总体
是来自正态总体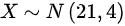 的样本,
的样本,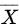 是样本均值,则
是样本均值,则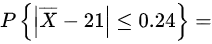
注: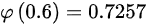
A.0.4514
B.0.5441
C.0.4415
D.0.5414
题目解答
答案
解:
根据题意,由于,样本容量n=25
则可得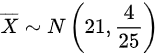
即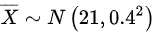
则可得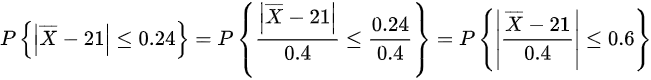
则可得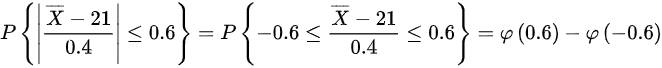
=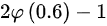
带入
得到=0.7257×2-1=0.4514
综上所述:本题选择A选项。
解析
考查要点:本题主要考查正态总体样本均值的分布及其概率计算,涉及标准化转换和标准正态分布函数的应用。
解题核心思路:
- 确定样本均值的分布:根据正态总体的性质,样本均值$\overline{X}$仍服从正态分布,其均值与总体均值相同,方差为总体方差除以样本容量。
- 标准化转换:将原概率问题转化为标准正态分布变量$Z$的范围问题。
- 利用标准正态分布函数:通过$\varphi(0.6)$的值计算概率,注意绝对值不等式的处理。
破题关键点:
- 正确计算样本均值的标准差:$\sigma_{\overline{X}} = \sqrt{\frac{4}{25}} = 0.4$。
- 标准化公式:$\frac{\overline{X} - \mu}{\sigma_{\overline{X}}}$对应标准正态变量$Z$。
- 绝对值概率公式:$P(|Z| \leq z) = 2\varphi(z) - 1$。
步骤1:确定样本均值的分布
总体$X \sim N(21, 4)$,样本容量$n=25$,则样本均值$\overline{X}$服从:
$\overline{X} \sim N\left(21, \frac{4}{25}\right) \implies \overline{X} \sim N(21, 0.4^2)$
步骤2:标准化转换
将不等式$|\overline{X} - 21| \leq 0.24$标准化:
$P\left( \left|\frac{\overline{X} - 21}{0.4}\right| \leq \frac{0.24}{0.4} \right) = P(|Z| \leq 0.6)$
其中$Z \sim N(0,1)$。
步骤3:计算概率
根据标准正态分布函数$\varphi(0.6) = 0.7257$:
$P(|Z| \leq 0.6) = 2\varphi(0.6) - 1 = 2 \times 0.7257 - 1 = 0.4514$