题目
某实验,有两个自变量A和B,其中A因素共有三类,B因素也有三类。交叉分组后共得到九种实验处理,每个处理中有两名被试。实验结束时对他们进行测试,最后获得的数据是反应时[1]间。经过数据分后,得到如下的结果分表。 差异来源 平方和 自由度 均方差 F值-|||-A因素 150-|||-B因素 180-|||-. B 160-|||-组内 160 ...-|||-总差异 ··· ··· ... 请问: (1)请将上表中空白的地方补充完整。(精确到小数点后两位) (2)指出该数据分的统计方法,检验了哪些效应,结果是否显著。 (下面是附表) 差异来源 平方和 自由度 均方差 F值-|||-A因素 150-|||-B因素 180-|||-. B 160-|||-组内 160 ...-|||-总差异 ··· ··· ...
某实验,有两个自变量A和B,其中A因素共有三类,B因素也有三类。交叉分组后共得到九种实验处理,每个处理中有两名被试。实验结束时对他们进行测试,最后获得的数据是反应时[1]间。经过数据分后,得到如下的结果分表。
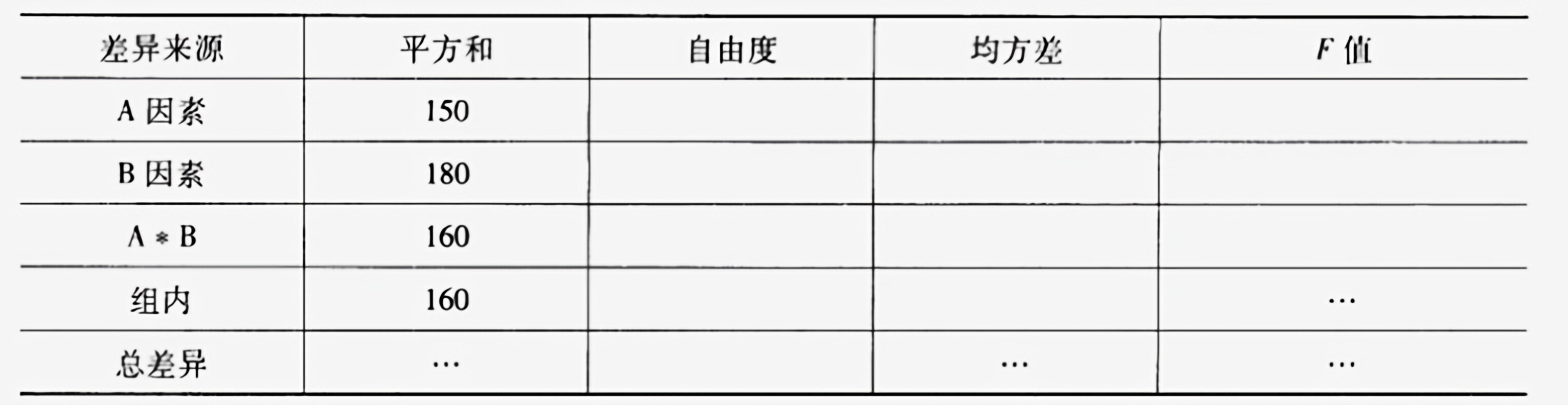 请问: (1)请将上表中空白的地方补充完整。(精确到小数点后两位) (2)指出该数据分的统计方法,检验了哪些效应,结果是否显著。 (下面是附表)
请问: (1)请将上表中空白的地方补充完整。(精确到小数点后两位) (2)指出该数据分的统计方法,检验了哪些效应,结果是否显著。 (下面是附表) 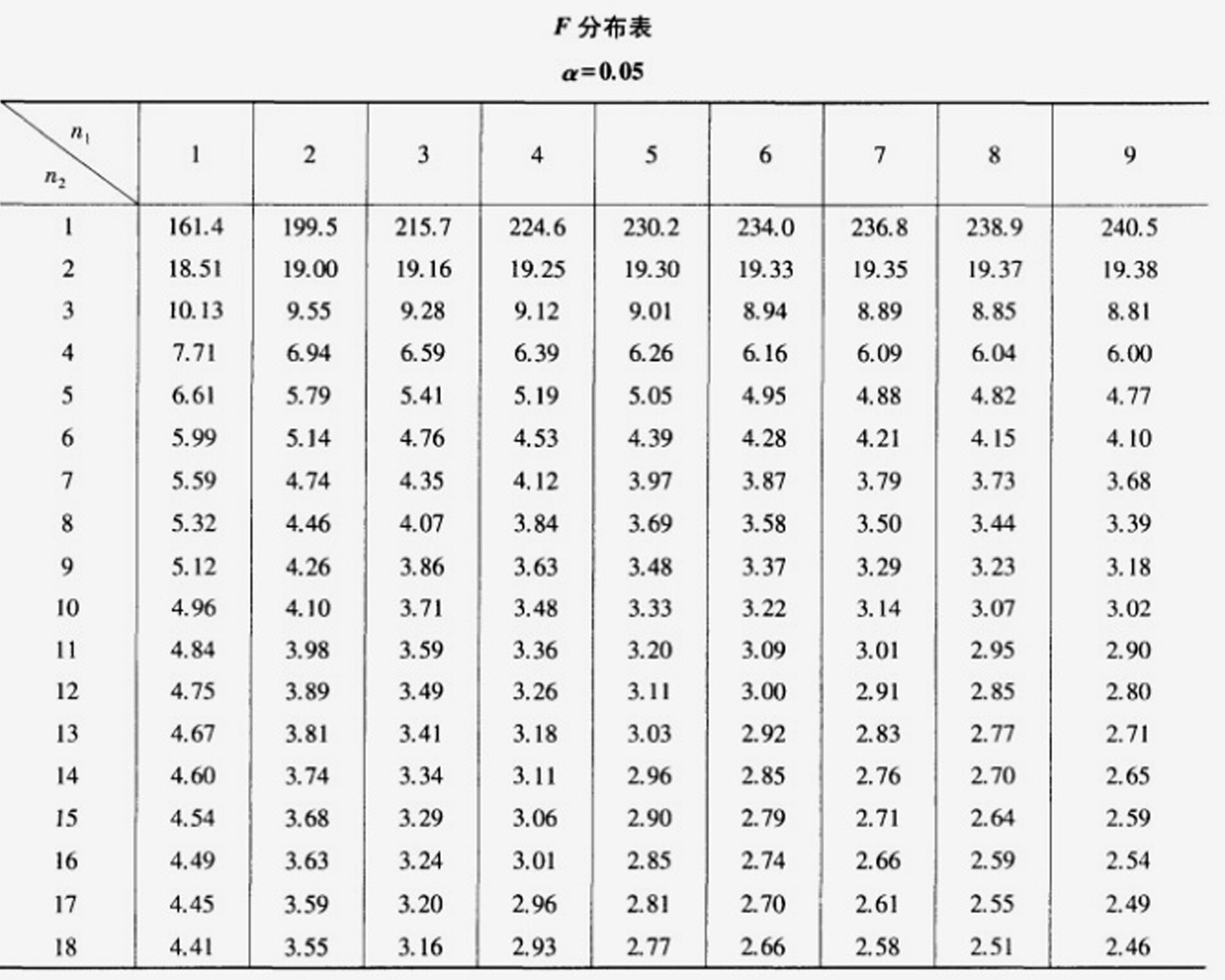
请问: (1)请将上表中空白的地方补充完整。(精确到小数点后两位) (2)指出该数据分的统计方法,检验了哪些效应,结果是否显著。 (下面是附表) 题目解答
答案
(1) (2)双因素方差分。检验了A因素主效应[2]、B因素主效应以及A和B的交互效应其中只有B因素的主效应是显著的。
本题考查被试对双因素方差分数据统计过程的掌握情况。
本题考查被试对双因素方差分数据统计过程的掌握情况。
解析
题目考察知识和解题思路
本题主要考察双因素方差分析的原理与应用,需补充方差分析表中空白单元格,并根据F值判断各效应的显著性。
(1)补充方差分析表空白处
关键参数计算
-
实验设计:A因素3类,B因素3类,每个处理2名被试,总被试数$N=3×3×2=18$。
-
自由度公式:
- A因素自由度:$df_A = a-1=3-1=2$
- B因素自由度:$df_B = b-1=3-1=2$
- 交互作用$A×B$自由度:$df_{A×B}=(a-1)(b-1)=2×2=4$
- 组内自由度:$df_{组内}=N-ab=18-9=9$
- 总自由度:$df_{总}=N-1=17$
-
均方(MS)计算:均方=平方和(SS)/自由度(df)
- $MS_A=SS_A/df_A=150/2=75$
- $MS_B=SS_B/df_B=180/2=90$
- $MS_{A×B}=SS_{A×B}/df_{A×B}=160/4=40$
- $MS_{组内}=SS_{组内}/df_{组内}=160/9≈17.78$(保留两位小数)
-
F值计算:$F=MS_{效应}/MS_{组内}$
- $F_A=75/17.78≈4.22$
- $F_B=90/17.78≈5.06$
- $F_{A×B}=40/17.78≈2.25$
-
总平方和($SS_{总}$):$SS_{总}=SS_A+SS_B+SS_{A×B}+SS_{组内}=150+180+160+160=650$
(2)统计方法与显著性检验
统计方法:双因素方差分析(完全随机设计,因每个处理独立样本)。
检验效应:A因素主效应、B因素主效应、A×B交互效应。
显著性判断($\alpha=0.05$):
- 组内自由度$df_2=9$,各效应分母自由度均为9,查F表得临界值:
- $F_{(2,9)}^{0.05}=4.26$(A因素、B因素、交互作用的分子自由度分别为2、2、4,对应临界值均为4.26)。
- 结果:
- $F_A≈4.22<4.26$,不显著;
- $F_B≈5.06>4.26$,显著;
- $F_{A×B}≈2.25<4.26$,不显著。