题目
某种曲奇饼干礼盒中有100块同款饼干,每块质量的期望值5克,标准差0.2克。则由中心极限定理,整盒饼干的质量X近似服从_ (填完整的分布记号,如U(2,5),字母,符号用英文符输入),按照上述分布,任抽一盒,X与标重之间的绝对误差不超过5克的概率_.(第二空答案写到小数点后面4位)
某种曲奇饼干礼盒中有100块同款饼干,每块质量的期望值5克,标准差0.2克。则由中心极限定理,整盒饼干的质量X近似服从_ (填完整的分布记号,如U(2,5),字母,符号用英文符输入),按照上述分布,任抽一盒,X与标重之间的绝对误差不超过5克的概率_.(第二空答案写到小数点后面4位)
题目解答
答案
整盒饼干质量X近似服从正态分布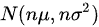
即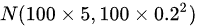 即N(500,4)
即N(500,4)
设标重为 m = 500 克,将 X 标准化,令 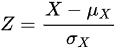
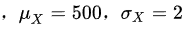
则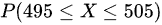
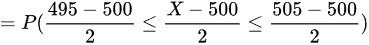
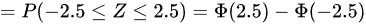
根据正态分布的性质,Φ(-z) = 1 - Φ(z)
所以 P(-2.5 ≤ Z ≤ 2.5) = Φ(2.5) - (1 - Φ(2.5)) = 2Φ(2.5) - 1
查标准正态分布表可得 Φ(2.5) = 0.9938
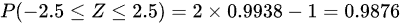
故第一空:N(500, 4); 第二空:0.9876。
解析
步骤 1:确定整盒饼干质量的分布
根据中心极限定理,当样本量足够大时,样本均值的分布近似于正态分布。这里,每块饼干的质量期望值为5克,标准差为0.2克,共有100块饼干。因此,整盒饼干的质量X近似服从正态分布N(nμ,nσ^2),其中n=100,μ=5克,σ=0.2克。
步骤 2:计算整盒饼干质量的期望值和方差
整盒饼干质量的期望值为E(X) = nμ = 100 × 5 = 500克,方差为Var(X) = nσ^2 = 100 × (0.2)^2 = 4克^2。因此,整盒饼干的质量X近似服从正态分布N(500, 4)。
步骤 3:计算X与标重之间的绝对误差不超过5克的概率
设标重为m = 500克,将X标准化,令$\dfrac {x-m}{\sigma_x}=z$,其中$\mu_x=500$,$\sigma_x=2$。则$P(495\leqslant X\leqslant 505)$
$=P(\dfrac {495-500}{2}\leqslant \dfrac {x-500}{2}\leqslant \dfrac {505-500}{2})$
$=P(-2.5\leqslant Z\leqslant 2.5)=(2.5)-(-2.5)$
根据正态分布的性质,Φ(-z) = 1 - Φ(z)
所以 P(-2.5 ≤ Z ≤ 2.5) = Φ(2.5) - (1 - Φ(2.5)) = 2Φ(2.5) - 1
查标准正态分布表可得 Φ(2.5) = 0.9938
$P(-2.5\leqslant Z\leqslant 2.5)=2\times 0.9938-1=0.9876$
根据中心极限定理,当样本量足够大时,样本均值的分布近似于正态分布。这里,每块饼干的质量期望值为5克,标准差为0.2克,共有100块饼干。因此,整盒饼干的质量X近似服从正态分布N(nμ,nσ^2),其中n=100,μ=5克,σ=0.2克。
步骤 2:计算整盒饼干质量的期望值和方差
整盒饼干质量的期望值为E(X) = nμ = 100 × 5 = 500克,方差为Var(X) = nσ^2 = 100 × (0.2)^2 = 4克^2。因此,整盒饼干的质量X近似服从正态分布N(500, 4)。
步骤 3:计算X与标重之间的绝对误差不超过5克的概率
设标重为m = 500克,将X标准化,令$\dfrac {x-m}{\sigma_x}=z$,其中$\mu_x=500$,$\sigma_x=2$。则$P(495\leqslant X\leqslant 505)$
$=P(\dfrac {495-500}{2}\leqslant \dfrac {x-500}{2}\leqslant \dfrac {505-500}{2})$
$=P(-2.5\leqslant Z\leqslant 2.5)=(2.5)-(-2.5)$
根据正态分布的性质,Φ(-z) = 1 - Φ(z)
所以 P(-2.5 ≤ Z ≤ 2.5) = Φ(2.5) - (1 - Φ(2.5)) = 2Φ(2.5) - 1
查标准正态分布表可得 Φ(2.5) = 0.9938
$P(-2.5\leqslant Z\leqslant 2.5)=2\times 0.9938-1=0.9876$