题目
采用正态近似法估计总体率的95%置信区间,其公式为() A. (p-1.96S/√n,p+1.96S/√n)-|||-B. (p-2.58S/sqrt (n),p+2.58S/sqrt (n))-|||-C. (p-1.96(s)_(p),p+1.96(s)_(p))-|||-D. (p-2.58(s)_(p),p+2.58(s)_(p))-|||-E. (p-1.965,p+1.965)A B C D E
采用正态近似法估计总体率的95%置信区间,其公式为()
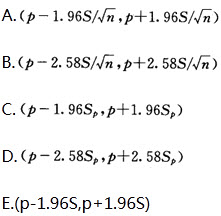
A
B
C
D
E
题目解答
答案
C. $(p-1.96{s}_{p},p+1.96{s}_{p})$
解析
考查要点:本题主要考查正态近似法下总体率95%置信区间的公式形式,需明确区分不同参数(如均值、比例)的置信区间构造方式,并掌握对应的临界值和标准误表达式。
解题核心思路:
- 识别参数类型:题目明确为“总体率”,因此需使用比例的置信区间公式。
- 确定临界值:95%置信水平对应正态分布的临界值为$1.96$。
- 标准误形式:总体率的标准误应为$\sqrt{\frac{p(1-p)}{n}}$,通常用$s_p$表示。
- 排除干扰项:注意区分均值与比例的标准误形式,以及不同置信水平对应的临界值。
破题关键点:
- 临界值$1.96$对应95%置信区间。
- 标准误$s_p$应为$\sqrt{\frac{p(1-p)}{n}}$,而非$\frac{s}{\sqrt{n}}$(后者用于均值的标准误)。
选项分析
选项A:$(p-1.96s/\sqrt{n}, p+1.96s/\sqrt{n})$
- 错误原因:标准误形式错误。$s/\sqrt{n}$是均值的标准误,而非比例的标准误。
选项B:$(p-2.58s/\sqrt{n}, p+2.58s/\sqrt{n})$
- 错误原因:临界值$2.58$对应99%置信水平,且标准误形式仍为均值形式。
选项C:$(p-1.96s_p, p+1.96s_p)$
- 正确性分析:
- 临界值:$1.96$符合95%置信水平。
- 标准误:$s_p = \sqrt{\frac{p(1-p)}{n}}$,正确对应总体率的标准误。
- 结论:公式形式完全正确。
选项D:$(p-2.58s_p, p+2.58s_p)$
- 错误原因:临界值$2.58$对应99%置信水平,与题干要求不符。
选项E:$(p-1.965, p+1.965)$
- 错误原因:未体现标准误,且数值$1.965$无明确统计学意义。