题目
某果汁产品中的维生素含量X服从正态分布(mu ,(sigma )^2),其中(mu ,(sigma )^2)未知,现随机抽取9件产品进行测量,测得样本均值(mu ,(sigma )^2),样本方差 (mu ,(sigma )^2) 问在(mu ,(sigma )^2)下检验该产品维生素含量为50是否成立?(mu ,(sigma )^2)
某果汁产品中的维生素含量X服从正态分布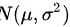 ,其中
,其中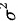 未知,现随机抽取9件产品进行测量,测得样本均值
未知,现随机抽取9件产品进行测量,测得样本均值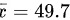 ,样本方差
,样本方差 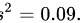 问在
问在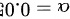 下检验该产品维生素含量为50是否成立?
下检验该产品维生素含量为50是否成立?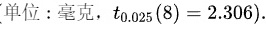
题目解答
答案
步骤 1:建立假设
零假设 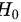 : 产品维生素含量为 50 毫克
: 产品维生素含量为 50 毫克 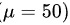
备择假设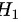 : 产品维生素含量不为 50 毫克
: 产品维生素含量不为 50 毫克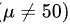
步骤 2:选择显著性水平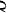
给定的显著性水平为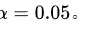
步骤 3:计算检验统计量
首先,计算样本标准差 s。样本方差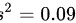 ,所以
,所以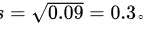
然后,计算 t 统计量:
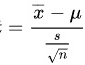
其中,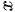 是样本均值,
是样本均值,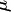 是总体均值,s 是样本标准差,n 是样本大小。
是总体均值,s 是样本标准差,n 是样本大小。
代入数据: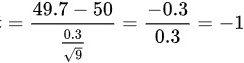
步骤 4:查找临界值
由于是双尾检验,我们需要查找 t 分布的临界值。给定显著性水平 和自由度 df = n - 1 = 8,查找 t 分布表格或计算器,可以得到 t 分布的临界值为 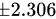 。
。
步骤 5:做出决策
在 t 分布上,找到 t 统计量对应的值。在本例中,t 统计量为 -1,它落在临界值 -2.306 和 2.306 的范围内。
因为 -1 不在拒绝域(临界值范围之外),所以我们无法拒绝零假设。
步骤 6:做出结论
在显著性水平 下,我们无法拒绝零假设 。因此,根据我们的样本数据,不能得出产品维生素含量不为 50 毫克的结论。
总结:在给定的显著性水平下,不能得出产品维生素含量与标称值 50 毫克不同的结论。
解析
步骤 1:建立假设
零假设 H0: 产品维生素含量为 50 毫克 $(\mu =50)$
备择假设 H1: 产品维生素含量不为 50 毫克 $(\mu \neq 50)$
步骤 2:选择显著性水平
给定的显著性水平为 $\alpha =0.05$
步骤 3:计算检验统计量
首先,计算样本标准差 s。样本方差 ${s}^{2}=0.09$,所以 $s=\sqrt {0.09}=0.3$
然后,计算 t 统计量:
$t=\dfrac {\overline {x}-\mu }{\dfrac {s}{\sqrt {n}}}$
其中,$\overline {x}$ 是样本均值,$\mu$ 是总体均值,s 是样本标准差,n 是样本大小。
代入数据:$t=\dfrac {49.7-50}{\dfrac {0.3}{\sqrt {9}}}=\dfrac {-0.3}{0.3}=-1$
步骤 4:查找临界值
由于是双尾检验,我们需要查找 t 分布的临界值。给定显著性水平 $\alpha =0.05$ 和自由度 df = n - 1 = 8,查找 t 分布表格或计算器,可以得到 t 分布的临界值为 $\pm 2.306$。
步骤 5:做出决策
在 t 分布上,找到 t 统计量对应的值。在本例中,t 统计量为 -1,它落在临界值 -2.306 和 2.306 的范围内。
因为 -1 不在拒绝域(临界值范围之外),所以我们无法拒绝零假设。
步骤 6:做出结论
在显著性水平 $\alpha =0.05$ 下,我们无法拒绝零假设 H0。因此,根据我们的样本数据,不能得出产品维生素含量不为 50 毫克的结论。
零假设 H0: 产品维生素含量为 50 毫克 $(\mu =50)$
备择假设 H1: 产品维生素含量不为 50 毫克 $(\mu \neq 50)$
步骤 2:选择显著性水平
给定的显著性水平为 $\alpha =0.05$
步骤 3:计算检验统计量
首先,计算样本标准差 s。样本方差 ${s}^{2}=0.09$,所以 $s=\sqrt {0.09}=0.3$
然后,计算 t 统计量:
$t=\dfrac {\overline {x}-\mu }{\dfrac {s}{\sqrt {n}}}$
其中,$\overline {x}$ 是样本均值,$\mu$ 是总体均值,s 是样本标准差,n 是样本大小。
代入数据:$t=\dfrac {49.7-50}{\dfrac {0.3}{\sqrt {9}}}=\dfrac {-0.3}{0.3}=-1$
步骤 4:查找临界值
由于是双尾检验,我们需要查找 t 分布的临界值。给定显著性水平 $\alpha =0.05$ 和自由度 df = n - 1 = 8,查找 t 分布表格或计算器,可以得到 t 分布的临界值为 $\pm 2.306$。
步骤 5:做出决策
在 t 分布上,找到 t 统计量对应的值。在本例中,t 统计量为 -1,它落在临界值 -2.306 和 2.306 的范围内。
因为 -1 不在拒绝域(临界值范围之外),所以我们无法拒绝零假设。
步骤 6:做出结论
在显著性水平 $\alpha =0.05$ 下,我们无法拒绝零假设 H0。因此,根据我们的样本数据,不能得出产品维生素含量不为 50 毫克的结论。