题目
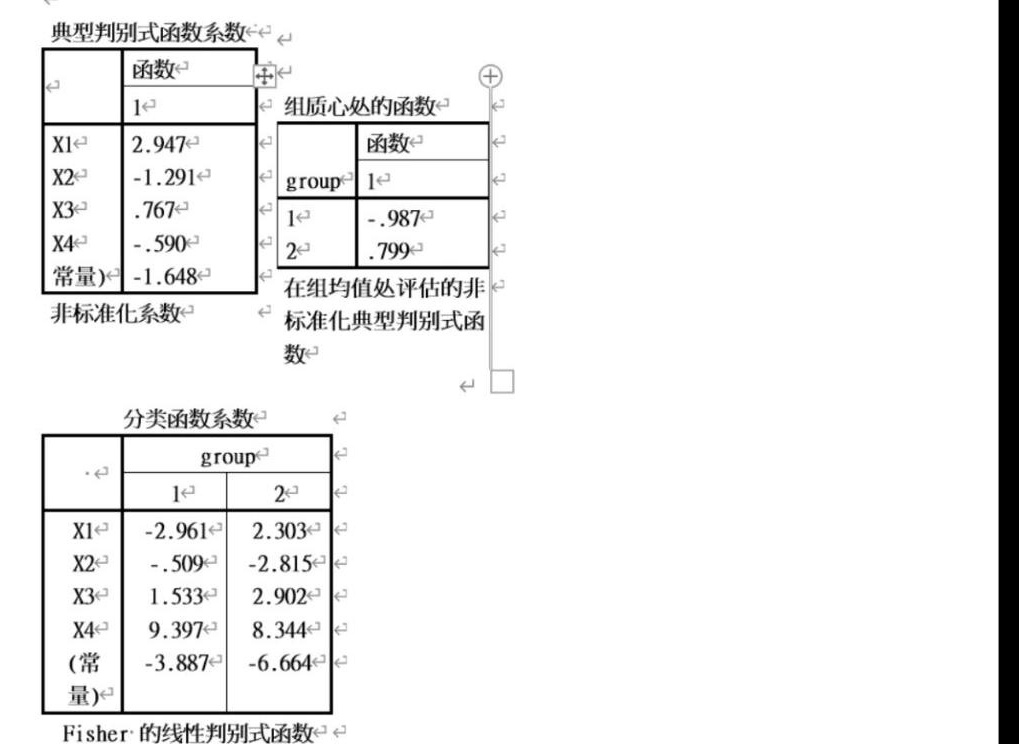
(数据二)为了研究中小企业的破产模型,选定4个经济指标:X 1为总负债率,X 2为收益性指标,X 3为短期支付能力,-X 4为生产效率性指标,对17个破产企业(1类)和21个正常运行企业(2类)进行了调查,得到的输出结果如下:假定各组样本出现概率相等,请完成如下分析:1,请写出贝叶斯判别函数,并指出如何对待判样品进行贝叶斯判别(文字解释即可)。2,请写出费歇尔判别函数,并指出如何对待判样品进行费进行费歇尔判别( 文字解释即可)。典型判别式函数系数-|||-函数 +-|||-1^( 组质心处的函数-|||-times 1 2.947 函数 k-|||-times 2 -1.291 group 1-|||-X3 .767 1^4 -.987-|||-times 4 -.590 2← .799-|||-常量) -1.648-|||-在组均值丛评估的非-|||-非标准化系数 标准化典型判别式函-|||-数-|||-square -|||-分类函数系数-|||--|||-https:/img.zuoyebang.cc/zyb_3a3700b022c20408c21168ee462fe2d4.jpglt 7 2-|||-X1← -2.961 2.303←-|||-X2 -509 -2.815 a-|||-X3 1.533 2.902-|||-X4 9.397 8.344-|||-(常 -3.887 -6.664 3-|||-量)-|||-Fisher 的线性判别式函数
(数据二)为了研究中小企业的破产模型,选定4个经济指标:X 1为总负债率,X 2为收益性指标,X 3为短期支付能力,-X 4为生产效率性指标,对17个破产企业(1类)和21个正常运行企业(2类)进行了调查,得到的输出结果如下:假定各组样本出现概率相等,请完成如下分析:
1,请写出贝叶斯判别函数,并指出如何对待判样品进行贝叶斯判别(文字解释即可)。
2,请写出费歇尔判别函数,并指出如何对待判样品进行费进行费歇尔判别( 文字解释即可)。
题目解答
答案


解析
贝叶斯判别的核心是后验概率最大化,通过计算待判样品属于各类的后验概率,将其归属为后验概率最大的类别。判别函数通常基于各类的概率密度函数和先验概率。
费歇尔判别的核心是线性判别函数,通过寻找能够最大化类间分离的线性组合,将高维数据投影到低维空间后进行分类。判别函数形式为线性组合,系数需通过组间方差最大化求解。
第1题:贝叶斯判别函数
- 判别函数形式
贝叶斯判别函数的一般形式为:
$Y = a_1 X_1 + a_2 X_2 + a_3 X_3 + a_4 X_4 + b$
其中,系数 $a_1, a_2, a_3, a_4$ 和常数项 $b$ 需从题目数据中提取。 - 系数提取
根据题目中“典型判别式函数系数”部分,标准化系数为:
$a_1 = 2.947, \quad a_2 = -1.291, \quad a_3 = 0.767, \quad a_4 = -0.987$
常数项 $b = -1.648$。 - 判别规则
将待判样品的指标值代入函数计算 $Y$,若 $Y > 0$,判为破产企业(1类);否则判为正常企业(2类)。
第2题:费歇尔判别函数
- 判别函数形式
费歇尔判别函数形式为:
$Y = c_1 X_1 + c_2 X_2 + c_3 X_3 + c_4 X_4 + d$
系数 $c_1, c_2, c_3, c_4$ 和常数项 $d$ 需从题目数据中提取。 - 系数提取
根据题目中“分类函数系数”部分,标准化系数为:
$c_1 = -2.961, \quad c_2 = -0.509, \quad c_3 = 1.533, \quad c_4 = 9.397$
常数项 $d = -3.887$。 - 判别规则
将待判样品的指标值代入函数计算 $Y$,若 $Y > 0$,判为破产企业(1类);否则判为正常企业(2类)。