题目
7.设总体X服从[0,θ]上的均匀分布,X 1,X2,X1为来自总体的简单随机样7.设总体X服从[0,θ]上的均匀分布,X 1,X2,X1为来自总体的简单随机样
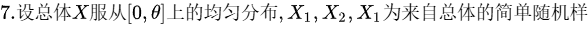
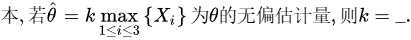
题目解答
答案
 \theta & & \end{cases}\mathrm{。} \\ & \text{那么}Y\text{的分布函数}F_Y(y)=[F_X(y)]^3\text{(这是根据求多个独立同分布随机变量最大值的分布函数的方法得来} \\ & \text{的),即:} \\ & F_Y(y)= \begin{cases} 0, & y<0 \\ \left(\frac{y}{\theta}\right)^3, & 0\leq y\leq\theta \\ 1, & y>\theta & \end{cases} \end{aligned}" data-width="855" data-height="278" data-size="42049" data-format="png" style="">
\theta & & \end{cases}\mathrm{。} \\ & \text{那么}Y\text{的分布函数}F_Y(y)=[F_X(y)]^3\text{(这是根据求多个独立同分布随机变量最大值的分布函数的方法得来} \\ & \text{的),即:} \\ & F_Y(y)= \begin{cases} 0, & y<0 \\ \left(\frac{y}{\theta}\right)^3, & 0\leq y\leq\theta \\ 1, & y>\theta & \end{cases} \end{aligned}" data-width="855" data-height="278" data-size="42049" data-format="png" style=""> \theta & & \end{cases} \end{aligned}" data-width="508" data-height="163" data-size="20266" data-format="png" style="">
\theta & & \end{cases} \end{aligned}" data-width="508" data-height="163" data-size="20266" data-format="png" style="">

解析
步骤 1:求 $max\{X_i\}$ 的分布函数
设 $Y=max\{X_i\}$,其中 $X_i$ 服从 $[0, \theta]$ 上的均匀分布,其分布函数为 $F_X(x)=\begin{cases} 0, & x<0 \\ \frac{x}{\theta}, & 0\leq x\leq \theta \\ 1, & x>\theta \end{cases}$。那么 $Y$ 的分布函数 $F_Y(y)=[F_X(y)]^3$,即:
$F_Y(y)=\begin{cases} 0, & y<0 \\ \left(\frac{y}{\theta}\right)^3, & 0\leq y\leq \theta \\ 1, & y>\theta \end{cases}$
步骤 2:求 $max\{X_i\}$ 的概率密度函数
对 $F_Y(y)$ 求导可得 $Y$ 的概率密度函数 $f_Y(y)$,即 $f_Y(y)=F_Y'(y)$,则:
$f_Y(y)=\begin{cases} 0, & y<0 \\ \frac{3y^2}{\theta^3}, & 0\leq y\leq \theta \\ 0, & y>\theta \end{cases}$
步骤 3:求 $E[max\{X_i\}]$
根据期望的计算公式 $E(Y)=\int_{-\infty}^{+\infty} y f_Y(y) dy$,可得:
$E(Y)=\int_{0}^{\theta} y \cdot \frac{3y^2}{\theta^3} dy = \frac{3}{\theta^3} \int_{0}^{\theta} y^3 dy = \frac{3}{\theta^3} \cdot \frac{y^4}{4} \Big|_{0}^{\theta} = \frac{3}{4}\theta$
步骤 4:根据无偏估计量的定义求 $k$
因为 $\hat{\theta}=kmax\{X_i\}$ 是 $\theta$ 的无偏估计量,根据无偏估计量的定义有 $E(\hat{\theta})=\theta$。而 $E(\hat{\theta})=E(kmax\{X_i\})=kE(max\{X_i\})$,又已知 $E(max\{X_i\})=\frac{3}{4}\theta$,所以:
$k \cdot \frac{3}{4}\theta = \theta$
$k=\frac{4}{3}$
设 $Y=max\{X_i\}$,其中 $X_i$ 服从 $[0, \theta]$ 上的均匀分布,其分布函数为 $F_X(x)=\begin{cases} 0, & x<0 \\ \frac{x}{\theta}, & 0\leq x\leq \theta \\ 1, & x>\theta \end{cases}$。那么 $Y$ 的分布函数 $F_Y(y)=[F_X(y)]^3$,即:
$F_Y(y)=\begin{cases} 0, & y<0 \\ \left(\frac{y}{\theta}\right)^3, & 0\leq y\leq \theta \\ 1, & y>\theta \end{cases}$
步骤 2:求 $max\{X_i\}$ 的概率密度函数
对 $F_Y(y)$ 求导可得 $Y$ 的概率密度函数 $f_Y(y)$,即 $f_Y(y)=F_Y'(y)$,则:
$f_Y(y)=\begin{cases} 0, & y<0 \\ \frac{3y^2}{\theta^3}, & 0\leq y\leq \theta \\ 0, & y>\theta \end{cases}$
步骤 3:求 $E[max\{X_i\}]$
根据期望的计算公式 $E(Y)=\int_{-\infty}^{+\infty} y f_Y(y) dy$,可得:
$E(Y)=\int_{0}^{\theta} y \cdot \frac{3y^2}{\theta^3} dy = \frac{3}{\theta^3} \int_{0}^{\theta} y^3 dy = \frac{3}{\theta^3} \cdot \frac{y^4}{4} \Big|_{0}^{\theta} = \frac{3}{4}\theta$
步骤 4:根据无偏估计量的定义求 $k$
因为 $\hat{\theta}=kmax\{X_i\}$ 是 $\theta$ 的无偏估计量,根据无偏估计量的定义有 $E(\hat{\theta})=\theta$。而 $E(\hat{\theta})=E(kmax\{X_i\})=kE(max\{X_i\})$,又已知 $E(max\{X_i\})=\frac{3}{4}\theta$,所以:
$k \cdot \frac{3}{4}\theta = \theta$
$k=\frac{4}{3}$