题目
[十五] 测定某种溶液中的水份,它的10个测定值给出s=0.037%,设测定值总体为正态分布,σ 2为总体方差。试在水平α = 0.05下检验假设H0:σ ≥0.04%;H1:σ <0.04%。
[十五] 测定某种溶液中的水份,它的10个测定值给出s=0.037%,设测定值总体为正态分布,σ 2为总体方差。试在水平α = 0.05下检验假设H0:σ ≥0.04%;H1:σ <0.04%。
题目解答
答案
解:(1)H:σ 2 ≥(0.04%)2;H1:σ 2 < (0.04%)2
(2)H的拒绝域为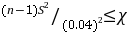
(3)n=10,α = 0.05,S=0.037%,查表知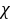
由计算知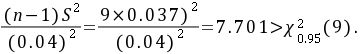
(4)故在α = 0.05下,接受H,认为σ大于0.04%
解析
步骤 1:确定假设
根据题目,我们需要检验的假设是:
H₀: σ ≥ 0.04% (原假设)
H₁: σ < 0.04% (备择假设)
步骤 2:确定检验统计量
由于总体方差未知,且样本量较小(n=10),我们使用卡方检验统计量。检验统计量为:
χ² = (n-1) * s² / σ₀²
其中,n是样本量,s是样本标准差,σ₀是原假设中的总体标准差。
步骤 3:确定拒绝域
在显著性水平α = 0.05下,我们需要找到卡方分布的临界值。由于这是一个左侧检验,我们需要找到χ²分布的左侧临界值。查卡方分布表,自由度为n-1=9,α = 0.05,得到临界值χ²₀.₀₅(9)。
步骤 4:计算检验统计量
将已知数据代入检验统计量公式:
χ² = (10-1) * (0.037%)² / (0.04%)²
步骤 5:比较检验统计量与临界值
将计算得到的检验统计量与临界值进行比较,如果检验统计量小于临界值,则拒绝原假设H₀,接受备择假设H₁;否则,不拒绝原假设H₀。
步骤 6:得出结论
根据比较结果,得出最终结论。
根据题目,我们需要检验的假设是:
H₀: σ ≥ 0.04% (原假设)
H₁: σ < 0.04% (备择假设)
步骤 2:确定检验统计量
由于总体方差未知,且样本量较小(n=10),我们使用卡方检验统计量。检验统计量为:
χ² = (n-1) * s² / σ₀²
其中,n是样本量,s是样本标准差,σ₀是原假设中的总体标准差。
步骤 3:确定拒绝域
在显著性水平α = 0.05下,我们需要找到卡方分布的临界值。由于这是一个左侧检验,我们需要找到χ²分布的左侧临界值。查卡方分布表,自由度为n-1=9,α = 0.05,得到临界值χ²₀.₀₅(9)。
步骤 4:计算检验统计量
将已知数据代入检验统计量公式:
χ² = (10-1) * (0.037%)² / (0.04%)²
步骤 5:比较检验统计量与临界值
将计算得到的检验统计量与临界值进行比较,如果检验统计量小于临界值,则拒绝原假设H₀,接受备择假设H₁;否则,不拒绝原假设H₀。
步骤 6:得出结论
根据比较结果,得出最终结论。