题目
X1,X2,X3,X4是来自总体X1,X2,X3,X4的样本,则下列正确的是().A.X1,X2,X3,X4B.X1,X2,X3,X4C.X1,X2,X3,X4D.X1,X2,X3,X4
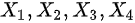 是来自总体
是来自总体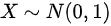 的样本,则下列正确的是().
的样本,则下列正确的是().
A.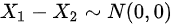
B.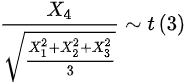
C.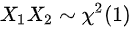
D.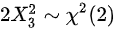
题目解答
答案
来自总体的样本相互独立且都服从总体的分布,则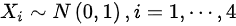 ,则
,则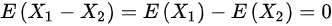 ,
,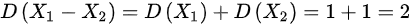 ,则
,则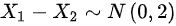 ,则选项A错误;
,则选项A错误;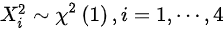 ,则
,则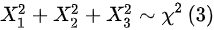 ,则,则选项B正确;
,则,则选项B正确;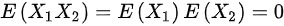 ,
,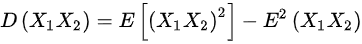
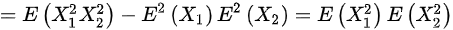
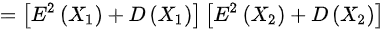
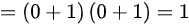 ,则
,则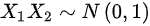 ,则选项C错误,相互独立的卡方分布具有可加性,则选项D错误,因此选择B。
,则选项C错误,相互独立的卡方分布具有可加性,则选项D错误,因此选择B。
解析
步骤 1:分析选项A
${X}_{1}-{X}_{2}$的期望和方差计算如下:
$E({X}_{1}-{X}_{2})=E({X}_{1})-E({X}_{2})=0-0=0$
$D({X}_{1}-{X}_{2})=D({X}_{1})+D({X}_{2})=1+1=2$
因此,${X}_{1}-{X}_{2}\sim N(0,2)$,选项A错误。
步骤 2:分析选项B
${{X}_{1}}^{2}+{{X}_{2}}^{2}+{{X}_{3}}^{2}\sim {\chi }^{2}(3)$,因为${X}_{i}\sim N(0,1)$,所以${{X}_{i}}^{2}\sim {\chi }^{2}(1)$,且相互独立。
$\dfrac {{X}_{4}}{\sqrt {{{X}_{1}}^{2}+{{X}_{2}}^{2}+{{X}_{3}}^{2}}}\sim t(3)$,因为${X}_{4}\sim N(0,1)$,且${{X}_{1}}^{2}+{{X}_{2}}^{2}+{{X}_{3}}^{2}\sim {\chi }^{2}(3)$,所以选项B正确。
步骤 3:分析选项C
${X}_{1}{X}_{2}$的期望和方差计算如下:
$E({X}_{1}{X}_{2})=E({X}_{1})E({X}_{2})=0$
$D({X}_{1}{X}_{2})=E[ {({X}_{1}{X}_{2})}^{2}] -{E}^{2}({X}_{1}{X}_{2})=E({{X}_{1}}^{2}{{X}_{2}}^{2})-{E}^{2}({X}_{1}){E}^{2}({X}_{2})=E({{X}_{1}}^{2})E({{X}_{2}}^{2})=(0+1)(0+1)=1$
因此,${X}_{1}{X}_{2}\sim N(0,1)$,选项C错误。
步骤 4:分析选项D
$2{{X}_{3}}^{2}\sim {\chi }^{2}(2)$,因为${X}_{3}\sim N(0,1)$,所以${{X}_{3}}^{2}\sim {\chi }^{2}(1)$,且$2{{X}_{3}}^{2}\sim {\chi }^{2}(2)$,所以选项D错误。
${X}_{1}-{X}_{2}$的期望和方差计算如下:
$E({X}_{1}-{X}_{2})=E({X}_{1})-E({X}_{2})=0-0=0$
$D({X}_{1}-{X}_{2})=D({X}_{1})+D({X}_{2})=1+1=2$
因此,${X}_{1}-{X}_{2}\sim N(0,2)$,选项A错误。
步骤 2:分析选项B
${{X}_{1}}^{2}+{{X}_{2}}^{2}+{{X}_{3}}^{2}\sim {\chi }^{2}(3)$,因为${X}_{i}\sim N(0,1)$,所以${{X}_{i}}^{2}\sim {\chi }^{2}(1)$,且相互独立。
$\dfrac {{X}_{4}}{\sqrt {{{X}_{1}}^{2}+{{X}_{2}}^{2}+{{X}_{3}}^{2}}}\sim t(3)$,因为${X}_{4}\sim N(0,1)$,且${{X}_{1}}^{2}+{{X}_{2}}^{2}+{{X}_{3}}^{2}\sim {\chi }^{2}(3)$,所以选项B正确。
步骤 3:分析选项C
${X}_{1}{X}_{2}$的期望和方差计算如下:
$E({X}_{1}{X}_{2})=E({X}_{1})E({X}_{2})=0$
$D({X}_{1}{X}_{2})=E[ {({X}_{1}{X}_{2})}^{2}] -{E}^{2}({X}_{1}{X}_{2})=E({{X}_{1}}^{2}{{X}_{2}}^{2})-{E}^{2}({X}_{1}){E}^{2}({X}_{2})=E({{X}_{1}}^{2})E({{X}_{2}}^{2})=(0+1)(0+1)=1$
因此,${X}_{1}{X}_{2}\sim N(0,1)$,选项C错误。
步骤 4:分析选项D
$2{{X}_{3}}^{2}\sim {\chi }^{2}(2)$,因为${X}_{3}\sim N(0,1)$,所以${{X}_{3}}^{2}\sim {\chi }^{2}(1)$,且$2{{X}_{3}}^{2}\sim {\chi }^{2}(2)$,所以选项D错误。