市场分析与预测SPSS结果目录________________________________________________________________________________________________________________________________________________________________________________________________________________________一元线性回归Correlations相关系数矩阵拟合优度方差分析表系数移动平均平滑用EXCEL比较简便,结果见教师版题目EXCEL文件中“时间序列的成分和预测方法”工作表。简单指数平滑保存变量截图回归直线拟合优度方差分析系数Holt指数平滑保存变量截图指数曲线保存变量截图多阶曲线Curve Fit保存变量截图残差自相关检验Winters指数平滑模型保存变量截图季节哑变量多元回归回归检验系数估计分解预测Seasonal Decomposition保存变量截图根据分离季节性因素的序列确定线性趋势方程,即使用STC_1数据进行一元回归Regression系数根据回归方程求出不含季节因素的预测值PRE_2,预测值乘以相应的季节指数SAF_1,即为分解预测的最终预测值保存变量截图NResidual 人-|||-均GDP Mode-|||-11-|||-2230.74 0.04-|||-2479.10 -square -|||-2727.36 .36 170.04-|||-3315.64 64 269.04-|||-4271.83 83 358.48-|||-5675.82 -43.76-|||-.82-|||-6633.89 .89 -201.69 .69-|||-7232.46 46 -225.97-|||-7580.86 .86 -198.52-|||-7758.25 .25 -13.43-|||-24 336.75-|||-年份 人均GDP Predicted_人均GDP LCL 人均GD UCL人均GD-|||-Model_1 P_Model_1 P Model 1-|||-1990 1644.47 1644.43 1058.11 2230.74-|||-1991 1892.76 1892.79 1306.47 2479.10-|||-1992 2311.09 2141.05 1554.74 2727.36-|||-.09-|||-1993 2998.36 36 2729.32 2143.01 3315.64-|||-1994 4044.00 3685.52 3099.21 1.21 4271.83-|||-1995 5045.73 5089.51 4503.20 20 5675.82-|||-1996 5845.89 6047.58 5461.26 !B 6633.89-|||-1997 6420.18 .18 6646.15 6059.84 .84 7232.46-|||-1998 6796.03 6994.55 6408.23 7580.86-|||-1999 7158.50 7171.93 .93 6585.62 7758.25-|||-2000 7857.68 7520.93 .93 6934.61 8107.24-|||-2001 8621.71 8556.67 .67 7970.36 .36 9142.98-|||-2002 9398.05 05 9385.79 8799.48 48 9972.10-|||-2003 10541.97 10174.40 9588.09 10760.71-|||-.97-|||-2004 12335.58 11685.69 11099.37 12272.00-|||-2005 14040.00 14128.92 13542.61 14715.23-|||-9142.98 65.04-|||-9972.10 12.26 .26-|||-10-|||-1.71 367.57-|||-649.89-|||--12.92预测曲线Interactive GraphNResidual 人-|||-均GDP Mode-|||-11-|||-2230.74 0.04-|||-2479.10 -square -|||-2727.36 .36 170.04-|||-3315.64 64 269.04-|||-4271.83 83 358.48-|||-5675.82 -43.76-|||-.82-|||-6633.89 .89 -201.69 .69-|||-7232.46 46 -225.97-|||-7580.86 .86 -198.52-|||-7758.25 .25 -13.43-|||-24 336.75-|||-年份 人均GDP Predicted_人均GDP LCL 人均GD UCL人均GD-|||-Model_1 P_Model_1 P Model 1-|||-1990 1644.47 1644.43 1058.11 2230.74-|||-1991 1892.76 1892.79 1306.47 2479.10-|||-1992 2311.09 2141.05 1554.74 2727.36-|||-.09-|||-1993 2998.36 36 2729.32 2143.01 3315.64-|||-1994 4044.00 3685.52 3099.21 1.21 4271.83-|||-1995 5045.73 5089.51 4503.20 20 5675.82-|||-1996 5845.89 6047.58 5461.26 !B 6633.89-|||-1997 6420.18 .18 6646.15 6059.84 .84 7232.46-|||-1998 6796.03 6994.55 6408.23 7580.86-|||-1999 7158.50 7171.93 .93 6585.62 7758.25-|||-2000 7857.68 7520.93 .93 6934.61 8107.24-|||-2001 8621.71 8556.67 .67 7970.36 .36 9142.98-|||-2002 9398.05 05 9385.79 8799.48 48 9972.10-|||-2003 10541.97 10174.40 9588.09 10760.71-|||-.97-|||-2004 12335.58 11685.69 11099.37 12272.00-|||-2005 14040.00 14128.92 13542.61 14715.23-|||-9142.98 65.04-|||-9972.10 12.26 .26-|||-10-|||-1.71 367.57-|||-649.89-|||--12.92多元线性回归一般形式拟合优度方差分析表系数多重共线性及其处理Correlations相关系数逐步回归变量的进入和移出标准两个模型的拟合优度两个模型的方差分析表两个模型的系数矩阵含有哑变量的回归只含有一个哑变量的回归方差分析表系数估计含有哑变量和数值变量的回归方差分析表系数估计Profile Plots均值图线性概率模型与logit回归(二元选择)基本操作步骤:(1)选择菜单:Analyze-Regression-Binary Logistic(2)选择一个被解释变量到Dependent框中,选择一个或多个解释变量到Covariates框中。(3)在Method框后选择解释变量的筛选策略;(4)如果希望分析解释变量的交互影响是否对被解释变量产生显著的线性影响,可选择相应的变量,并按“>a*b>”按钮到Covariates框中;(5)如果解释变量为分类变量,可按Categorical按钮指定如何生成虚拟变量。选择Covariates框中的分类变量到Categorical Covariates框中,在Change Contrast框中的Contrast选项中选择参照类,并按change按钮。(6)按Option按钮,可指定输出内容和设置建模中的某些参数;(7)按Save按钮,可以SPSS变量的形式将预测结果、残差等保存到数据编辑窗口中。输出结果(一):给出了分类因变量y的取值编码与分布情况。输出结果(二):显示了Logit回归初始阶段(第0步,方程中只有常数项)的情况。可以看到,661人投了Bush的票且模型预测正确,正确率为100%;278人投了Perot的票,但模型预测错误,正确率为0%。模型总的预测正确率为70.4%。输出结果(三):显示了方程中只有常数项时的回归系数方面的指标,各数据项的含义一次为:回归系数、回归系数标准误差、Wald检验统计量的观测值、自由度、Wald检验统计量的概率P值、相对风险比。由于此模型中为包含任何解释变量,该表并无太多实际意义。输出结果(四):显示了待进入方程的解释变量的情况。各数据项的含义依次是:Score检验统计量的观测值、自由度和概率P值。例如,如果下一步受教育水平(Educ)进入方程,其概率P值为0.115大于显著性水平a=0.05,所以不能进入方程。但是这里采用Enter策略,因此所有解释变量将强行进入方程。输出结果(五):显示了所有解释变量强行进入方程时回归方程的总体情况,各数据项的含义依次是:似然比卡方的观测值、自由度和概率P值。本例所选变量均进入方程,与前一步相比,似然比卡方的观测值为46.234,概率P值为0.000,小于显著性水平a=0.05,应拒绝原假设,认为所有回归系数不同时为0,该模型是合理的。这里分别输出了三行似然比卡方值。其中,Step(步骤)行是本步与前一步相比的似然比卡方;Block(块)行是本块与前面一块相比的似然比卡方;Model(模型)行是本模型与前一模型相比的似然比卡方值。本例中,由于解释变量是一次性强制进入模型的,所以三行结果相同。输出结果(六):显示了当前模型拟合优度方面的指标,-2倍的对数似然函数越小,则模型拟合优度越高,本例中的该值较大,拟合优度并不理想,且CoxSnelly R2以及Nagelkerke R2都很小,也说明拟合优度较低。输出结果(七):显示了当前模型的预测结果矩阵,脚注中切割点.500表示,如果预测概率值大于0.05,则认为解释变量的分类预测值为1;如果小于0.05,则认为被解释变量的分类预测值为0。在投票给Bush的661人中,模型正确识别了659人,错误识别了人,正确率为99.7%;在投票给Perot的278人中,正确识别了1人,错误识别了277人,正确率仅有0.4%。模型总体的预测正确率70.3%。输出结果(八):显示了当前模型中各回归系数方面的指标。可以看出,如果显著性水平a为0.05,Age的Wald检验的概率P值小于显著性水平a,而Education和Sex的Wald检验的概率P值大于显著性水平a,因此,Age(年龄)对选民投票倾向的影响是显著的,而Education(受教育水平)和Sex(性别)对选民投票倾向无显著影响。根据模型系数判断,年长的选民更倾向于将选票投给Bush,年轻的选民则倾向于将选票投给Perot。logit模型(多元选择)基本操作步骤:(1)选择菜单:Analyze-Regression-Multinomial Logistic;(2)选择被解释变量到Dependent框中,按Reference Category按钮指定被解释变量的参照类别;(3)选择分类型解释变量到Factors框中,选择数值型解释变量到Covariates框中;(4)按Model按钮指定模型类型;(5)按Statistics按钮指定输出哪些统计量。(6)按Save按钮,选择适当选项后,SPSS将自动将预测结果以变量的形式存储到数据编辑窗口中。输出结果(一):给出了选民投票和选民性别的分布情况。输出结果(二):给出了当前模型的拟合优度指标,前两个跟二项Logisitic回归分析相同。第三个统计量McFadden一般在0.3至0.5之间就相当理想了。输出结果(三):给出了只有截距项的模型和最终模型的回归方程显著性检验结果。可以看出,仅含截距项的模型的-2倍的对数似然值为2537,而最终模型为2447,似然比卡方值为89.888,概率P值为0.000,小于显著性水平a=0.05,说明解释变量总体上对被解释变量的影响是显著的,也就说模型总体来讲是有效的。输出结果(四):给出了模型参数的估计结果,表中项目依次为回归系数估计值、标准误差、Wald统计量的观测值、自由度、Wald统计量观测值对应的概率P值等。于是得到两个方程,第一个方程被解释变量为选择Bush的概率与选择Perot的概率之比的自然对数,第二个方程为选择Clinton的概率与选择Perot的概率之比的自然对数。根据两个方程的显著性水平来看,在a=0.05的条件下,受教育水平(Education)都是不显著的,而年龄和性别则是显著的。根据模型的系数可见,相对于Perot而言,年长者和女性跟倾向于选择Bush;相对于Perot而言,年长者和女性更倾向于选择Clinton。
市场分析与预测SPSS结果
目录
________________
________________
________
________
________
________
________
________
________________________
________________
________
________
________
________________
________
________
________
________________
________
________
一元线性回归
Correlations相关系数矩阵
拟合优度
方差分析表
系数
移动平均平滑
用EXCEL比较简便,结果见教师版题目EXCEL文件中“时间序列的成分和预测方法”工作表。
简单指数平滑
保存变量截图
回归直线
拟合优度
方差分析
系数
Holt指数平滑
保存变量截图
指数曲线
保存变量截图
多阶曲线
Curve Fit
保存变量截图
残差自相关检验
Winters指数平滑模型
保存变量截图
季节哑变量多元回归
回归检验
系数估计
分解预测
Seasonal Decomposition
保存变量截图
根据分离季节性因素的序列确定线性趋势方程,即使用STC_1数据进行一元回归
Regression
系数
根据回归方程求出不含季节因素的预测值PRE_2,预测值乘以相应的季节指数SAF_1,即为分解预测的最终预测值
保存变量截图
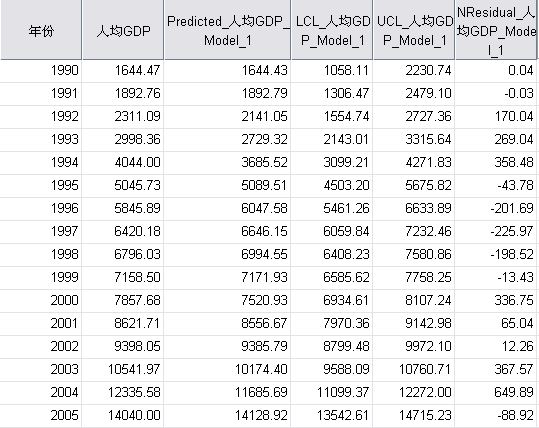
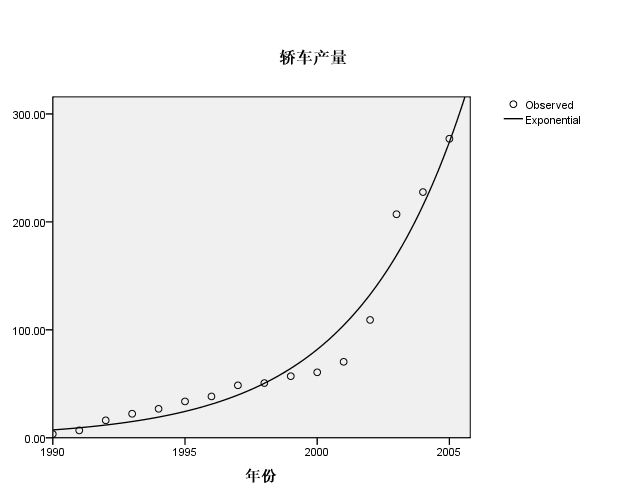
预测曲线
Interactive Graph
多元线性回归
一般形式
拟合优度
方差分析表
系数
多重共线性及其处理
Correlations相关系数
逐步回归
变量的进入和移出标准
两个模型的拟合优度
两个模型的方差分析表
两个模型的系数矩阵
含有哑变量的回归
只含有一个哑变量的回归
方差分析表
系数估计
含有哑变量和数值变量的回归
方差分析表
系数估计
Profile Plots均值图
线性概率模型与logit回归(二元选择)
基本操作步骤:
(1)选择菜单:Analyze-Regression-Binary Logistic
(2)选择一个被解释变量到Dependent框中,选择一个或多个解释变量到Covariates框中。
(3)在Method框后选择解释变量的筛选策略;
(4)如果希望分析解释变量的交互影响是否对被解释变量产生显著的线性影响,可选择相应的变量,并按“>a*b>”按钮到Covariates框中;
(5)如果解释变量为分类变量,可按Categorical按钮指定如何生成虚拟变量。选择Covariates框中的分类变量到Categorical Covariates框中,在Change Contrast框中的Contrast选项中选择参照类,并按change按钮。
(6)按Option按钮,可指定输出内容和设置建模中的某些参数;
(7)按Save按钮,可以SPSS变量的形式将预测结果、残差等保存到数据编辑窗口中。
输出结果(一):给出了分类因变量y的取值编码与分布情况。
输出结果(二):显示了Logit回归初始阶段(第0步,方程中只有常数项)的情况。可以看到,661人投了Bush的票且模型预测正确,正确率为100%;278人投了Perot的票,但模型预测错误,正确率为0%。模型总的预测正确率为70.4%。
输出结果(三):显示了方程中只有常数项时的回归系数方面的指标,各数据项的含义一次为:回归系数、回归系数标准误差、Wald检验统计量的观测值、自由度、Wald检验统计量的概率P值、相对风险比。由于此模型中为包含任何解释变量,该表并无太多实际意义。
输出结果(四):显示了待进入方程的解释变量的情况。各数据项的含义依次是:Score检验统计量的观测值、自由度和概率P值。例如,如果下一步受教育水平(Educ)进入方程,其概率P值为0.115大于显著性水平a=0.05,所以不能进入方程。但是这里采用Enter策略,因此所有解释变量将强行进入方程。
输出结果(五):显示了所有解释变量强行进入方程时回归方程的总体情况,各数据项的含义依次是:似然比卡方的观测值、自由度和概率P值。本例所选变量均进入方程,与前一步相比,似然比卡方的观测值为46.234,概率P值为0.000,小于显著性水平a=0.05,应拒绝原假设,认为所有回归系数不同时为0,该模型是合理的。
这里分别输出了三行似然比卡方值。其中,Step(步骤)行是本步与前一步相比的似然比卡方;Block(块)行是本块与前面一块相比的似然比卡方;Model(模型)行是本模型与前一模型相比的似然比卡方值。本例中,由于解释变量是一次性强制进入模型的,所以三行结果相同。
输出结果(六):显示了当前模型拟合优度方面的指标,-2倍的对数似然函数越小,则模型拟合优度越高,本例中的该值较大,拟合优度并不理想,且CoxSnelly R2以及Nagelkerke R2都很小,也说明拟合优度较低。
输出结果(七):显示了当前模型的预测结果矩阵,脚注中切割点.500表示,如果预测概率值大于0.05,则认为解释变量的分类预测值为1;如果小于0.05,则认为被解释变量的分类预测值为0。在投票给Bush的661人中,模型正确识别了659人,错误识别了人,正确率为99.7%;在投票给Perot的278人中,正确识别了1人,错误识别了277人,正确率仅有0.4%。模型总体的预测正确率70.3%。
输出结果(八):显示了当前模型中各回归系数方面的指标。可以看出,如果显著性水平a为0.05,Age的Wald检验的概率P值小于显著性水平a,而Education和Sex的Wald检验的概率P值大于显著性水平a,因此,Age(年龄)对选民投票倾向的影响是显著的,而Education(受教育水平)和Sex(性别)对选民投票倾向无显著影响。
根据模型系数判断,年长的选民更倾向于将选票投给Bush,年轻的选民则倾向于将选票投给Perot。
logit模型(多元选择)
基本操作步骤:
(1)选择菜单:Analyze-Regression-Multinomial Logistic;
(2)选择被解释变量到Dependent框中,按Reference Category按钮指定被解释变量的参照类别;
(3)选择分类型解释变量到Factors框中,选择数值型解释变量到Covariates框中;
(4)按Model按钮指定模型类型;
(5)按Statistics按钮指定输出哪些统计量。
(6)按Save按钮,选择适当选项后,SPSS将自动将预测结果以变量的形式存储到数据编辑窗口中。
输出结果(一):给出了选民投票和选民性别的分布情况。
输出结果(二):给出了当前模型的拟合优度指标,前两个跟二项Logisitic回归分析相同。第三个统计量McFadden一般在0.3至0.5之间就相当理想了。
输出结果(三):给出了只有截距项的模型和最终模型的回归方程显著性检验结果。可以看出,仅含截距项的模型的-2倍的对数似然值为2537,而最终模型为2447,似然比卡方值为89.888,概率P值为0.000,小于显著性水平a=0.05,说明解释变量总体上对被解释变量的影响是显著的,也就说模型总体来讲是有效的。
输出结果(四):给出了模型参数的估计结果,表中项目依次为回归系数估计值、标准误差、Wald统计量的观测值、自由度、Wald统计量观测值对应的概率P值等。于是得到两个方程,第一个方程被解释变量为选择Bush的概率与选择Perot的概率之比的自然对数,第二个方程为选择Clinton的概率与选择Perot的概率之比的自然对数。根据两个方程的显著性水平来看,在a=0.05的条件下,受教育水平(Education)都是不显著的,而年龄和性别则是显著的。根据模型的系数可见,相对于Perot而言,年长者和女性跟倾向于选择Bush;相对于Perot而言,年长者和女性更倾向于选择Clinton。
题目解答
答案
一元 线性回归 多元 线性回归 一般形式 多重共线性及其处理 逐步回归 含有哑变量的回归 只含有一个哑变量的回归 含有哑变量和数值变量的回归 线性概率模型与 logit 回归(二元选择) logit 模型(多元选择) 移动平均平滑 简单指数平滑 回归直线 Holt 指数平滑 指数曲线 多阶曲线 残差自相关检验 Winters 指数平滑模型 季节哑变量多元回归 分解预测