题目
望远镜的放大率,经重复测量8次得物镜主焦距cm,重复测量4次得目镜的主焦距cm,求:1)放大率测量中由f1 、f2引起的不确定度分量和放大率D的标准不确定度。2)有效自由度3)直径D在置信概率P=95%时的展伸不确定度。(t 0.05(8)=2.31 t 0.05(9)=2.26 t 0.05(10)=2.23) (20分)
望远镜的放大率,经重复测量8次得物镜主焦距cm,重复测量4次得目镜的主焦距cm,求:
1)放大率测量中由f1 、f2引起的不确定度分量和放大率D的标准不确定度。
2)有效自由度
3)直径D在置信概率P=95%时的展伸不确定度。
(t 0.05(8)=2.31 t 0.05(9)=2.26 t 0.05(10)=2.23) (20分)
题目解答
答案
解:1)由f1引起的标准不确定度分量
系数 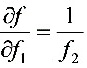
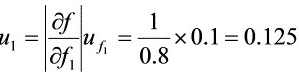 (4分)
(4分)
由f2引起的标准不确定度分量
系数 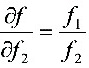
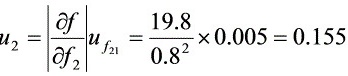 (8分)
(8分)
放在率D的 标准不确定度
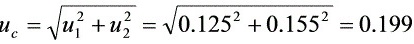 (12分)
(12分)
2) 其自由度为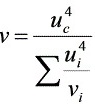 =
=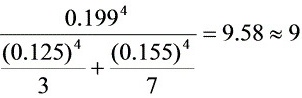 (17分)
(17分)
3)求扩展不确定度:
置信概率P=95%时,由自由度=9查表得t 0.05(9)=2.26,即包含因子为2.26,于是
U95=2.26*0.199=0.45(cm)(或由自由度=10查表得t0.05(10)=2.23,即包含因子为2.23,于是U95=2.23*0.199=0.44(cm)) (20分)
解析
步骤 1:计算由f1引起的不确定度分量
根据题目,物镜主焦距f1的测量值为19.8cm,重复测量8次,其标准不确定度为0.1cm。放大率D的计算公式为D = f1 / f2,其中f2为目镜的主焦距。因此,由f1引起的不确定度分量为:
系数 $\dfrac {\partial D}{\partial {f}_{1}}=\dfrac {1}{{f}_{2}}$
${u}_{1}=|\dfrac {\partial D}{\partial {f}_{1}}{u}_{{f}_{1}}=\dfrac {1}{0.8}\times 0.1=0.125$ (4分)
步骤 2:计算由f2引起的不确定度分量
根据题目,目镜的主焦距f2的测量值为0.8cm,重复测量4次,其标准不确定度为0.005cm。因此,由f2引起的不确定度分量为:
系数 $\dfrac {\partial D}{\partial {f}_{2}}=\dfrac {{f}_{1}}{{f}_{2}^{2}}$
${u}_{2}=|\dfrac {\partial D}{\partial {f}_{2}}{u}_{{f}_{2}}=\dfrac {19.8}{{0.8}^{2}}\times 0.005=0.155$ (8分)
步骤 3:计算放大率D的标准不确定度
放大率D的标准不确定度为由f1和f2引起的不确定度分量的平方和的平方根,即:
${u}_{c}=\sqrt {{{u}_{1}}^{2}+{{u}_{2}}^{2}}=\sqrt {{0.125}^{2}+{0.155}^{2}}=0.199$ (12分)
步骤 4:计算有效自由度
有效自由度为:
$v=\dfrac {{{u}_{c}}^{4}}{\sum _{i=1}^{n}{t}_{i}}$=$\dfrac {{0.199}^{4}}{3}+\dfrac {{(0.155)}^{4}}{7}=9.58\approx 9$ (17分)
步骤 5:计算置信概率P=95%时的展伸不确定度
置信概率P=95%时,由自由度=9查表得t 0.05(9)=2.26,即包含因子为2.26,于是
U95=2.26*0.199=0.45(cm)(或由自由度=10查表得t0.05(10)=2.23,即包含因子为2.23,于是U95=2.23*0.199=0.44(cm)) (20分)
根据题目,物镜主焦距f1的测量值为19.8cm,重复测量8次,其标准不确定度为0.1cm。放大率D的计算公式为D = f1 / f2,其中f2为目镜的主焦距。因此,由f1引起的不确定度分量为:
系数 $\dfrac {\partial D}{\partial {f}_{1}}=\dfrac {1}{{f}_{2}}$
${u}_{1}=|\dfrac {\partial D}{\partial {f}_{1}}{u}_{{f}_{1}}=\dfrac {1}{0.8}\times 0.1=0.125$ (4分)
步骤 2:计算由f2引起的不确定度分量
根据题目,目镜的主焦距f2的测量值为0.8cm,重复测量4次,其标准不确定度为0.005cm。因此,由f2引起的不确定度分量为:
系数 $\dfrac {\partial D}{\partial {f}_{2}}=\dfrac {{f}_{1}}{{f}_{2}^{2}}$
${u}_{2}=|\dfrac {\partial D}{\partial {f}_{2}}{u}_{{f}_{2}}=\dfrac {19.8}{{0.8}^{2}}\times 0.005=0.155$ (8分)
步骤 3:计算放大率D的标准不确定度
放大率D的标准不确定度为由f1和f2引起的不确定度分量的平方和的平方根,即:
${u}_{c}=\sqrt {{{u}_{1}}^{2}+{{u}_{2}}^{2}}=\sqrt {{0.125}^{2}+{0.155}^{2}}=0.199$ (12分)
步骤 4:计算有效自由度
有效自由度为:
$v=\dfrac {{{u}_{c}}^{4}}{\sum _{i=1}^{n}{t}_{i}}$=$\dfrac {{0.199}^{4}}{3}+\dfrac {{(0.155)}^{4}}{7}=9.58\approx 9$ (17分)
步骤 5:计算置信概率P=95%时的展伸不确定度
置信概率P=95%时,由自由度=9查表得t 0.05(9)=2.26,即包含因子为2.26,于是
U95=2.26*0.199=0.45(cm)(或由自由度=10查表得t0.05(10)=2.23,即包含因子为2.23,于是U95=2.23*0.199=0.44(cm)) (20分)