题目
在某地区10000户家庭中,按简单随机抽样抽取400户,调查一个月的文化支出(单位:元)。经计算:400 400-|||-yi = 165712, y yn^2=119110251.39-|||-i=1(1)试估计该地区平均每户每月的文化支出,并估计其标准差。(忽略f) (2)给出置信度为95%时该地区平均每户每月文化支出的近似置信区间。(忽略f)
在某地区10000户家庭中,按简单随机抽样抽取400户,调查一个月的文化支出(单位:元)。
经计算: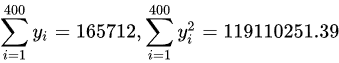 (1)试估计该地区平均每户每月的文化支出,并估计其标准差。(忽略f)
(1)试估计该地区平均每户每月的文化支出,并估计其标准差。(忽略f)
(2)给出置信度为95%时该地区平均每户每月文化支出的近似置信区间。(忽略f)
题目解答
答案
(1) 估计该地区平均每户每月的文化支出及标准差:
估计平均文化支出:
样本平均数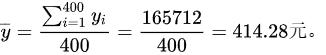
以此估计该地区平均每户每月的文化支出为414.28元。
估计标准差:
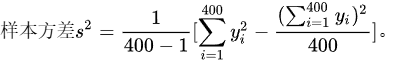
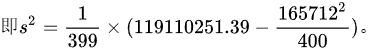
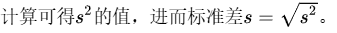
(2)计算置信度为95%时该地区平均每户每月文化支出的近似置信区间:
由于样本量较大,可使用中心极限定理,近似认为样本均值服从正态分布。
对于95%的置信度,对应的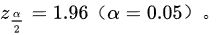
置信区间为
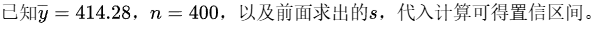
解析
步骤 1:估计该地区平均每户每月的文化支出
样本平均数 $\overline{y} = \dfrac{\sum_{i=1}^{400} y_i}{400} = \dfrac{165712}{400} = 414.28$ 元。
以此估计该地区平均每户每月的文化支出为 414.28 元。
步骤 2:估计标准差
样本方差 $s^2 = \dfrac{1}{400-1} \left( \sum_{i=1}^{400} y_i^2 - \dfrac{(\sum_{i=1}^{400} y_i)^2}{400} \right)$
代入已知数据:
$s^2 = \dfrac{1}{399} \left( 119110251.39 - \dfrac{165712^2}{400} \right)$
计算可得 $s^2$ 的值,进而标准差 $s = \sqrt{s^2}$。
步骤 3:计算置信度为95%时该地区平均每户每月文化支出的近似置信区间
由于样本量较大,可使用中心极限定理,近似认为样本均值服从正态分布。
对于95%的置信度,对应的 $z_{\frac{\alpha}{2}} = 1.96$。
置信区间为 $\overline{y} \pm z_{\frac{\alpha}{2}} \dfrac{s}{\sqrt{n}}$。
已知 $\overline{y} = 414.28$,$n = 400$,以及前面求出的 $s$,代入计算可得置信区间。
样本平均数 $\overline{y} = \dfrac{\sum_{i=1}^{400} y_i}{400} = \dfrac{165712}{400} = 414.28$ 元。
以此估计该地区平均每户每月的文化支出为 414.28 元。
步骤 2:估计标准差
样本方差 $s^2 = \dfrac{1}{400-1} \left( \sum_{i=1}^{400} y_i^2 - \dfrac{(\sum_{i=1}^{400} y_i)^2}{400} \right)$
代入已知数据:
$s^2 = \dfrac{1}{399} \left( 119110251.39 - \dfrac{165712^2}{400} \right)$
计算可得 $s^2$ 的值,进而标准差 $s = \sqrt{s^2}$。
步骤 3:计算置信度为95%时该地区平均每户每月文化支出的近似置信区间
由于样本量较大,可使用中心极限定理,近似认为样本均值服从正态分布。
对于95%的置信度,对应的 $z_{\frac{\alpha}{2}} = 1.96$。
置信区间为 $\overline{y} \pm z_{\frac{\alpha}{2}} \dfrac{s}{\sqrt{n}}$。
已知 $\overline{y} = 414.28$,$n = 400$,以及前面求出的 $s$,代入计算可得置信区间。