题目
抽样技术答案作业一书本P632.9如果在解决习题2.5的问题时可以得到这些家庭月总支出,得到如下表:单位:元编号文化支出总支出编号文化支出总支出120023001115016002150170012160170031702000131802000415015001413014005160170015150160061301400161001200714015001718019008100120018100110091101200191701800101401500201201300全部家庭的总支出平均为1600元,利用比估计的方法估计平均文化支出,给出置信水平95%的置信区间,并比较比估计和简单估计的效率。解析:由题可知又故平均文化支出的95%的置信区间为代入数据得(146.329±1.96*1.892)即为[142.621,150.037]2.10某养牛场购进了120头肉牛,购进时平均体重100千克。现从中抽取10头,记录重量,3个月后再次测量,结果如下:单位:千克用回归估计法计算120头牛现在的平均重量,计算其方差的估计,并和简单估计的结果进行比较。
抽样技术答案
作业一
书本P63
2.9如果在解决习题2.5的问题时可以得到这些家庭月总支出,得到如下表:
单位:元
编号
文化支出
总支出
编号
文化支出
总支出
1
200
2300
11
150
1600
2
150
1700
12
160
1700
3
170
2000
13
180
2000
4
150
1500
14
130
1400
5
160
1700
15
150
1600
6
130
1400
16
100
1200
7
140
1500
17
180
1900
8
100
1200
18
100
1100
9
110
1200
19
170
1800
10
140
1500
20
120
1300
全部家庭的总支出平均为1600元,利用比估计的方法估计平均文化支出,给出置信水平95%的置信区间,并比较比估计和简单估计的效率。
解析:由题可知
又
故平均文化支出的95%的置信区间为
代入数据得(146.329±1.96*1.892)
即为[142.621,150.037]
2.10某养牛场购进了120头肉牛,购进时平均体重100千克。现从中抽取10头,记录重量,3个月后再次测量,结果如下:
单位:千克
用回归估计法计算120头牛现在的平均重量,计算其方差的估计,并和简单估计的结果进行比较。
题目解答
答案
==0.924
根据各层层权及抽样比的结果,可得
()==0.000396981
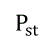 =1.99%
=1.99%
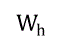 估计量的标准差为1.99%,比例为9.24%
估计量的标准差为1.99%,比例为9.24%
按比例分配:n=2663
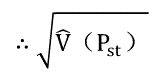 =479, =559, =373, =240, =426, =586
=479, =559, =373, =240, =426, =586
内曼分配:n=2565
=536, =520, =417, =304, =396, =392