题目
设总体sim N(mu ,4),其中sim N(mu ,4)未知,sim N(mu ,4)是来自总体的样本,sim N(mu ,4)为样本均值,sim N(mu ,4)为样本方差,则下列各式中不是统计量的是( )A.sim N(mu ,4)B.sim N(mu ,4)C.sim N(mu ,4)D.sim N(mu ,4)
设总体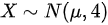 ,其中
,其中 未知,
未知,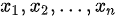 是来自总体的样本,
是来自总体的样本,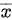 为样本均值,
为样本均值,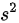 为样本方差,则下列各式中不是统计量的是( )
为样本方差,则下列各式中不是统计量的是( )
A.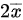
B.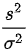
C.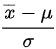
D.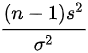
题目解答
答案
统计量中只能包含已知量,不能包含未知参数。表示总体X服从均值为,方差为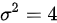 的正态分布,其中均值未知,方差已知,来自总体的样本为已知量,则包含未知参数的都不是统计量,样本均值
的正态分布,其中均值未知,方差已知,来自总体的样本为已知量,则包含未知参数的都不是统计量,样本均值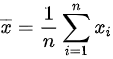 中样本都已知,则样本均值是统计量,样本方差
中样本都已知,则样本均值是统计量,样本方差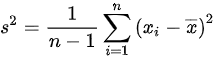 中样本和样本均值都为已知量,则样本方差是统计量,则中样本均值为已知量,则选项A是统计量;中样本方差和总体方差都已知,则选项B的是统计量;中包含未知参数,则选项C不是统计量;中样本方差和总体方差都已知,则选项D是统计量,因此选择C。
中样本和样本均值都为已知量,则样本方差是统计量,则中样本均值为已知量,则选项A是统计量;中样本方差和总体方差都已知,则选项B的是统计量;中包含未知参数,则选项C不是统计量;中样本方差和总体方差都已知,则选项D是统计量,因此选择C。
解析
统计量的定义是:仅由样本数据构成的函数,不能包含任何未知总体参数。本题中,总体方差$\sigma^2=4$已知,均值$\mu$未知。因此,若选项中出现未知参数$\mu$或依赖未知参数的表达式,则该选项不是统计量。
选项分析
A. $\bar{x}$
- 样本均值$\bar{x} = \frac{1}{n}\sum_{i=1}^n x_i$,仅依赖于样本数据$x_1, x_2, \dots, x_n$,不含未知参数,是统计量。
B. $\dfrac{s^2}{\sigma^2}$
- 样本方差$s^2 = \dfrac{1}{n-1}\sum_{i=1}^n (x_i - \bar{x})^2$,分母$\sigma^2=4$已知,因此该比值仅依赖于样本数据和已知参数,是统计量。
C. $\dfrac{0}{x - x}$
- 分母$x - x = 0$,导致表达式为$\dfrac{0}{0}$,数学上未定义。若题目实际为$\dfrac{0}{\mu - \bar{x}}$(可能输入错误),则分母含未知参数$\mu$,不是统计量。无论哪种情况,该选项均不符合统计量的定义。
D. $\dfrac{(n-1)s^2}{\sigma^2}$
- 分子$(n-1)s^2$是自由度调整后的样本方差,分母$\sigma^2=4$已知,因此该表达式是统计量(服从自由度为$n-1$的卡方分布)。