题目
第三章、多元线性回归模型[1]例1.某地区通过一个样本容量[2]为722的调查数据得到劳动力受教育的一个回归方程为R=式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。问(1)sibs是否具有预期的影响为什么若medu与fedu保持不变,为了使预测[3]的受教育水平减少一年,需要sibs增加多少(2)请对medu的系数给予适当的解释。(3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数为12年,另一个的父母受教育的年数为16年,则两人受教育的年数预期相差多少解答:(1)预期sibs对劳动者受教育的年数有影响。因此在收入及支出预算约束一定的条件下,子女越多的家庭,每个孩子接受教育的时间会越短。根据多元回归模型偏回归系数的含义,sibs前的参数估计值表明,在其他条件不变的情况下,每增加1个兄弟姐妹,受教育年数会减少年,因此,要减少1年受教育的时间,兄弟姐妹需增加1/=个。(2)medu的系数表示当兄弟姐妹数与父亲受教育的年数保持不变时,母亲每增加1年受教育的机会,其子女作为劳动者就会预期增加年的教育机会。(3)首先计算两人受教育的年数分别为+12+12=+16+16=因此,两人的受教育年限的差别为例2.以企业研发支出(RD)占销售额的比重为被解释变量[4](Y),以企业销售额(X1)与利润占销售额的比重(X2)为解释变量,一个有32容量的样本企业的估计结果如下:其中括号中为系数估计值的标准差[5]。(1)解释log(X1)的系数。如果X1增加10%,估计Y会变化多少个百分点这在经济上是一个很大的影响吗(2)针对RD强度随销售额的增加而提高这一备择假设[6],检验它不虽X1而变化的假设。分别在5%和10%的显着性水平上进行这个检验。(3)利润占销售额的比重X2对RD强度Y是否在统计上有显着的影响解答:(1)log(x1)的系数表明在其他条件不变时,log(x1)变化1个单位,Y变化的单位数,即Y=log(X1)(X1/X1)=100%,换言之,当企业销售X1增长100%时,企业研发支出占销售额的比重Y会增加个百分点。由此,如果X1增加10%,Y会增加个百分点。这在经济上不是一个较大的影响。(2)针对备择假设H1:,检验原假设H0:。易知计算的t统计量的值为t==。在5%的显着性水平下,自由度[7]为32-3=29的t 分布的临界值为(单侧),计算的t值小于该临界值,所以不拒绝原假设。意味着RD强度不随销售额的增加而变化。在10%的显着性水平下,t分布的临界值为,计算的t 值小于该值,拒绝原假设,意味着RD强度随销售额的增加而增加。(3)对X2,参数估计值的t统计值为=,它比在10%的显着性水平下的临界值还小,因此可以认为它对Y在统计上没有显着的影响。例3.下表为有关经批准的私人住房单位及其决定因素的4个模型的估计量和相关统计值(括号内为p-值)(如果某项为空,则意味着模型中没有此变量)。数据为美国40个城市的数据。模型如下:式中housing——实际颁发的建筑许可证数量,density——每平方英里的人口密度,value——自由房屋的均值(单位:百美元),income——平均家庭的收入(单位:千美元),popchang——1980~1992年的人口增长百分比,unemp——失业率,localtax——人均交纳的地方税,statetax——人均缴纳的州税(1)检验模型A中的每一个回归系数在10%水平下是否为零(括号中的值为双边备择p-值)。根据检验结果,你认为应该把变量保留在模型中还是去掉(2)在模型A中,在10%水平下检验联合假设H: =0(i=1,5,6,7)。说明被择假设,计算检验统计值,说明其在零假设[8]条件下的分布,拒绝或接受零假设的标准。说明你的结论。(3)哪个模型是“最优的”解释你的选择标准。(4)说明最优模型中有哪些系数的符号是“错误的”。说明你的预期符号并解释原因。确认其是否为正确符号。解答:(1)直接给出了P-值,所以没有必要计算t-统计值以及查t分布表。根据题意,如果p-值<,则我们拒绝参数为零的原假设。由于表中所有参数的p-值都超过了10%,所以没有系数是显着不为零的。但由此去掉所有解释变量,则会得到非常奇怪的结果。其实正如我们所知道的,多元回去归中在省略变量时一定要谨慎,要有所选择。本例中,value、income、popchang的p-值仅比稍大一点,在略掉unemp、localtax、statetax的模型C中,这些变量的系数都是显着的。(2)针对联合假设H: =0(i=1,5,6,7)的备择假设为H1: =0(i=1,5,6,7) 中至少有一个不为零。检验假设H0,实际上就是参数的约束性检验,非约束模型为模型A,约束模型为模型D,检验统计值为显然,在H0假设下,上述统计量满足F分布,在10%的显着性水平下,自由度为(4,32)的F分布的临界值位于和之间。显然,计算的F值小于临界值,我们不能拒绝H0,所以βi(i=1,5,6,7)是联合不显着的。(3)模型D中的3个解释变量全部通过显着性检验。尽管R2与残差平方和较大,但相对来说其AIC值最低,所以我们选择该模型为最优的模型。(4)随着收入的增加,我们预期住房需要会随之增加。所以可以预期β3>0,事实上其估计值确是大于零的。同样地,随着人口的增加,住房需求也会随之增加,所以我们预期β4>0,事实其估计值也是如此。随着房屋价格的上升,我们预期对住房的需求人数减少,即我们预期β3估计值的符号为负,回归结果与直觉相符。出乎预料的是,地方税与州税为不显着的。由于税收的增加将使可支配收入降低,所以我们预期住房的需求将下降。虽然模型A是这种情况,但它们的影响却非常微弱。3-17.假设要求你建立一个计量经济模型来说明在学校跑道上慢跑一英里或一英里以上的人数,以便决定是否修建第二条跑道以满足所有的锻炼者。你通过整个学年收集数据,得到两个可能的解释性方程:方程A: 方程B: 其中:——某天慢跑者的人数——该天降雨的英寸数——该天日照的小时数——该天的最高温度(按华氏温度)——第二天需交学期论文的班级数请回答下列问题:(1)这两个方程你认为哪个更合理些,为什么(2)为什么用相同的数据去估计相同变量的系数得到不同的符号答:方程B更合理些。原因是:方程B中的参数估计值的符号与现实更接近些,如与日照的小时数同向变化,天长则慢跑的人会多些;与第二天需交学期论文的班级数成反向变化,这一点在学校的跑道模型中是一个合理的解释变量。解释变量的系数表明该变量的单位变化在方程中其他解释变量不变的条件下对被解释变量的影响,在方程A和方程B中由于选择了不同的解释变量,如方程A选择的是“该天的最高温度”而方程B选择的是“第二天需交学期论文的班级数”,由此造成与这两个变量之间的关系不同,所以用相同的数据估计相同的变量得到不同的符号。3-19.假定以校园内食堂每天卖出的盒饭数量作为被解释变量,盒饭价格、气温、附近餐厅的盒饭价格、学校当日的学生数量(单位:千人)作为解释变量,进行回归分析;假设不管是否有假期,食堂都营业。不幸的是,食堂内的计算机被一次病毒侵犯,所有的存储丢失,无法恢复,你不能说出独立变量分别代表着哪一项!下面是回归结果(括号内为标准差):() 要求:(1)试判定每项结果对应着哪一个变量(2)对你的判定结论做出说明。答:答案并不唯一,猜测为:为学生数量,为附近餐厅的盒饭价格,为气温,为校园内食堂的盒饭价格;理由是被解释变量应与学生数量成正比,并且应该影响显着;与本食堂盒饭价格成反比,这与需求理论相吻合;与附近餐厅的盒饭价格成正比,因为彼此是替代品;与气温的变化关系不是十分显着,因为大多数学生不会因为气温升高不吃饭。3-28.考虑以下预测的回归方程: 其中:——第t年的玉米产量(蒲式耳/亩)——第t年的施肥强度(磅/亩)——第t年的降雨量(英寸)要求回答下列问题:(1)从和对的影响方面,说出本方程中系数和的含义;(2)常数项是否意味着玉米的负产量可能存在(3)假定的真实值为,则估计值是否有偏为什么(4)假定该方程并不满足所有的古典模型假设,即并不是最佳线性无偏估计值,则是否意味着的真实值绝对不等于为什么
第三章、多元线性回归模型[1]例
1.某地区通过一个样本容量[2]为722的调查数据得到劳动力受教育的一个回归方程为R=式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。问(1)sibs是否具有预期的影响为什么若medu与fedu保持不变,为了使预测[3]的受教育水平减少一年,需要sibs增加多少(2)请对medu的系数给予适当的解释。(3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数为12年,另一个的父母受教育的年数为16年,则两人受教育的年数预期相差多少解答:(1)预期sibs对劳动者受教育的年数有影响。因此在收入及支出预算约束一定的条件下,子女越多的家庭,每个孩子接受教育的时间会越短。根据多元回归模型偏回归系数的含义,sibs前的参数估计值表明,在其他条件不变的情况下,每增加1个兄弟姐妹,受教育年数会减少年,因此,要减少1年受教育的时间,兄弟姐妹需增加1/=个。(2)medu的系数表示当兄弟姐妹数与父亲受教育的年数保持不变时,母亲每增加1年受教育的机会,其子女作为劳动者就会预期增加年的教育机会。(3)首先计算两人受教育的年数分别为+12+12=+16+16=因此,两人的受教育年限的差别为例
2.以企业研发支出(RD)占销售额的比重为被解释变量[4](Y),以企业销售额(X1)与利润占销售额的比重(X2)为解释变量,一个有32容量的样本企业的估计结果如下:其中括号中为系数估计值的标准差[5]。(1)解释log(X1)的系数。如果X1增加10%,估计Y会变化多少个百分点这在经济上是一个很大的影响吗(2)针对RD强度随销售额的增加而提高这一备择假设[6],检验它不虽X1而变化的假设。分别在5%和10%的显着性水平上进行这个检验。(3)利润占销售额的比重X2对RD强度Y是否在统计上有显着的影响解答:(1)log(x1)的系数表明在其他条件不变时,log(x1)变化1个单位,Y变化的单位数,即Y=log(X1)(X1/X1)=100%,换言之,当企业销售X1增长100%时,企业研发支出占销售额的比重Y会增加个百分点。由此,如果X1增加10%,Y会增加个百分点。这在经济上不是一个较大的影响。(2)针对备择假设H1:,检验原假设H0:。易知计算的t统计量的值为t==。在5%的显着性水平下,自由度[7]为32-3=29的t 分布的临界值为(单侧),计算的t值小于该临界值,所以不拒绝原假设。意味着RD强度不随销售额的增加而变化。在10%的显着性水平下,t分布的临界值为,计算的t 值小于该值,拒绝原假设,意味着RD强度随销售额的增加而增加。(3)对X2,参数估计值的t统计值为=,它比在10%的显着性水平下的临界值还小,因此可以认为它对Y在统计上没有显着的影响。例
3.下表为有关经批准的私人住房单位及其决定因素的4个模型的估计量和相关统计值(括号内为p-值)(如果某项为空,则意味着模型中没有此变量)。数据为美国40个城市的数据。模型如下:式中housing——实际颁发的建筑许可证数量,density——每平方英里的人口密度,value——自由房屋的均值(单位:百美元),income——平均家庭的收入(单位:千美元),popchang——1980~1992年的人口增长百分比,unemp——失业率,localtax——人均交纳的地方税,statetax——人均缴纳的州税(1)检验模型A中的每一个回归系数在10%水平下是否为零(括号中的值为双边备择p-值)。根据检验结果,你认为应该把变量保留在模型中还是去掉(2)在模型A中,在10%水平下检验联合假设H: =0(i=1,5,6,7)。说明被择假设,计算检验统计值,说明其在零假设[8]条件下的分布,拒绝或接受零假设的标准。说明你的结论。(3)哪个模型是“最优的”解释你的选择标准。(4)说明最优模型中有哪些系数的符号是“错误的”。说明你的预期符号并解释原因。确认其是否为正确符号。解答:(1)直接给出了P-值,所以没有必要计算t-统计值以及查t分布表。根据题意,如果p-值<,则我们拒绝参数为零的原假设。由于表中所有参数的p-值都超过了10%,所以没有系数是显着不为零的。但由此去掉所有解释变量,则会得到非常奇怪的结果。其实正如我们所知道的,多元回去归中在省略变量时一定要谨慎,要有所选择。本例中,value、income、popchang的p-值仅比稍大一点,在略掉unemp、localtax、statetax的模型C中,这些变量的系数都是显着的。(2)针对联合假设H: =0(i=1,5,6,7)的备择假设为H1: =0(i=1,5,6,7) 中至少有一个不为零。检验假设H0,实际上就是参数的约束性检验,非约束模型为模型A,约束模型为模型D,检验统计值为显然,在H0假设下,上述统计量满足F分布,在10%的显着性水平下,自由度为(4,32)的F分布的临界值位于和之间。显然,计算的F值小于临界值,我们不能拒绝H0,所以βi(i=1,5,6,7)是联合不显着的。(3)模型D中的3个解释变量全部通过显着性检验。尽管R2与残差平方和较大,但相对来说其AIC值最低,所以我们选择该模型为最优的模型。(4)随着收入的增加,我们预期住房需要会随之增加。所以可以预期β3>0,事实上其估计值确是大于零的。同样地,随着人口的增加,住房需求也会随之增加,所以我们预期β4>0,事实其估计值也是如此。随着房屋价格的上升,我们预期对住房的需求人数减少,即我们预期β3估计值的符号为负,回归结果与直觉相符。出乎预料的是,地方税与州税为不显着的。由于税收的增加将使可支配收入降低,所以我们预期住房的需求将下降。虽然模型A是这种情况,但它们的影响却非常微弱。3-1
7.假设要求你建立一个计量经济模型来说明在学校跑道上慢跑一英里或一英里以上的人数,以便决定是否修建第二条跑道以满足所有的锻炼者。你通过整个学年收集数据,得到两个可能的解释性方程:方程A: 方程B: 其中:——某天慢跑者的人数——该天降雨的英寸数——该天日照的小时数——该天的最高温度(按华氏温度)——第二天需交学期论文的班级数请回答下列问题:(1)这两个方程你认为哪个更合理些,为什么(2)为什么用相同的数据去估计相同变量的系数得到不同的符号答:方程B更合理些。原因是:方程B中的参数估计值的符号与现实更接近些,如与日照的小时数同向变化,天长则慢跑的人会多些;与第二天需交学期论文的班级数成反向变化,这一点在学校的跑道模型中是一个合理的解释变量。解释变量的系数表明该变量的单位变化在方程中其他解释变量不变的条件下对被解释变量的影响,在方程A和方程B中由于选择了不同的解释变量,如方程A选择的是“该天的最高温度”而方程B选择的是“第二天需交学期论文的班级数”,由此造成与这两个变量之间的关系不同,所以用相同的数据估计相同的变量得到不同的符号。3-1
9.假定以校园内食堂每天卖出的盒饭数量作为被解释变量,盒饭价格、气温、附近餐厅的盒饭价格、学校当日的学生数量(单位:千人)作为解释变量,进行回归分析;假设不管是否有假期,食堂都营业。不幸的是,食堂内的计算机被一次病毒侵犯,所有的存储丢失,无法恢复,你不能说出独立变量分别代表着哪一项!下面是回归结果(括号内为标准差):() 要求:(1)试判定每项结果对应着哪一个变量(2)对你的判定结论做出说明。答:答案并不唯一,猜测为:为学生数量,为附近餐厅的盒饭价格,为气温,为校园内食堂的盒饭价格;理由是被解释变量应与学生数量成正比,并且应该影响显着;与本食堂盒饭价格成反比,这与需求理论相吻合;与附近餐厅的盒饭价格成正比,因为彼此是替代品;与气温的变化关系不是十分显着,因为大多数学生不会因为气温升高不吃饭。3-2
8.考虑以下预测的回归方程: 其中:——第t年的玉米产量(蒲式耳/亩)——第t年的施肥强度(磅/亩)——第t年的降雨量(英寸)要求回答下列问题:(1)从和对的影响方面,说出本方程中系数和的含义;(2)常数项是否意味着玉米的负产量可能存在(3)假定的真实值为,则估计值是否有偏为什么(4)假定该方程并不满足所有的古典模型假设,即并不是最佳线性无偏估计值,则是否意味着的真实值绝对不等于为什么
1.某地区通过一个样本容量[2]为722的调查数据得到劳动力受教育的一个回归方程为R=式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。问(1)sibs是否具有预期的影响为什么若medu与fedu保持不变,为了使预测[3]的受教育水平减少一年,需要sibs增加多少(2)请对medu的系数给予适当的解释。(3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数为12年,另一个的父母受教育的年数为16年,则两人受教育的年数预期相差多少解答:(1)预期sibs对劳动者受教育的年数有影响。因此在收入及支出预算约束一定的条件下,子女越多的家庭,每个孩子接受教育的时间会越短。根据多元回归模型偏回归系数的含义,sibs前的参数估计值表明,在其他条件不变的情况下,每增加1个兄弟姐妹,受教育年数会减少年,因此,要减少1年受教育的时间,兄弟姐妹需增加1/=个。(2)medu的系数表示当兄弟姐妹数与父亲受教育的年数保持不变时,母亲每增加1年受教育的机会,其子女作为劳动者就会预期增加年的教育机会。(3)首先计算两人受教育的年数分别为+12+12=+16+16=因此,两人的受教育年限的差别为例
2.以企业研发支出(RD)占销售额的比重为被解释变量[4](Y),以企业销售额(X1)与利润占销售额的比重(X2)为解释变量,一个有32容量的样本企业的估计结果如下:其中括号中为系数估计值的标准差[5]。(1)解释log(X1)的系数。如果X1增加10%,估计Y会变化多少个百分点这在经济上是一个很大的影响吗(2)针对RD强度随销售额的增加而提高这一备择假设[6],检验它不虽X1而变化的假设。分别在5%和10%的显着性水平上进行这个检验。(3)利润占销售额的比重X2对RD强度Y是否在统计上有显着的影响解答:(1)log(x1)的系数表明在其他条件不变时,log(x1)变化1个单位,Y变化的单位数,即Y=log(X1)(X1/X1)=100%,换言之,当企业销售X1增长100%时,企业研发支出占销售额的比重Y会增加个百分点。由此,如果X1增加10%,Y会增加个百分点。这在经济上不是一个较大的影响。(2)针对备择假设H1:,检验原假设H0:。易知计算的t统计量的值为t==。在5%的显着性水平下,自由度[7]为32-3=29的t 分布的临界值为(单侧),计算的t值小于该临界值,所以不拒绝原假设。意味着RD强度不随销售额的增加而变化。在10%的显着性水平下,t分布的临界值为,计算的t 值小于该值,拒绝原假设,意味着RD强度随销售额的增加而增加。(3)对X2,参数估计值的t统计值为=,它比在10%的显着性水平下的临界值还小,因此可以认为它对Y在统计上没有显着的影响。例
3.下表为有关经批准的私人住房单位及其决定因素的4个模型的估计量和相关统计值(括号内为p-值)(如果某项为空,则意味着模型中没有此变量)。数据为美国40个城市的数据。模型如下:式中housing——实际颁发的建筑许可证数量,density——每平方英里的人口密度,value——自由房屋的均值(单位:百美元),income——平均家庭的收入(单位:千美元),popchang——1980~1992年的人口增长百分比,unemp——失业率,localtax——人均交纳的地方税,statetax——人均缴纳的州税(1)检验模型A中的每一个回归系数在10%水平下是否为零(括号中的值为双边备择p-值)。根据检验结果,你认为应该把变量保留在模型中还是去掉(2)在模型A中,在10%水平下检验联合假设H: =0(i=1,5,6,7)。说明被择假设,计算检验统计值,说明其在零假设[8]条件下的分布,拒绝或接受零假设的标准。说明你的结论。(3)哪个模型是“最优的”解释你的选择标准。(4)说明最优模型中有哪些系数的符号是“错误的”。说明你的预期符号并解释原因。确认其是否为正确符号。解答:(1)直接给出了P-值,所以没有必要计算t-统计值以及查t分布表。根据题意,如果p-值<,则我们拒绝参数为零的原假设。由于表中所有参数的p-值都超过了10%,所以没有系数是显着不为零的。但由此去掉所有解释变量,则会得到非常奇怪的结果。其实正如我们所知道的,多元回去归中在省略变量时一定要谨慎,要有所选择。本例中,value、income、popchang的p-值仅比稍大一点,在略掉unemp、localtax、statetax的模型C中,这些变量的系数都是显着的。(2)针对联合假设H: =0(i=1,5,6,7)的备择假设为H1: =0(i=1,5,6,7) 中至少有一个不为零。检验假设H0,实际上就是参数的约束性检验,非约束模型为模型A,约束模型为模型D,检验统计值为显然,在H0假设下,上述统计量满足F分布,在10%的显着性水平下,自由度为(4,32)的F分布的临界值位于和之间。显然,计算的F值小于临界值,我们不能拒绝H0,所以βi(i=1,5,6,7)是联合不显着的。(3)模型D中的3个解释变量全部通过显着性检验。尽管R2与残差平方和较大,但相对来说其AIC值最低,所以我们选择该模型为最优的模型。(4)随着收入的增加,我们预期住房需要会随之增加。所以可以预期β3>0,事实上其估计值确是大于零的。同样地,随着人口的增加,住房需求也会随之增加,所以我们预期β4>0,事实其估计值也是如此。随着房屋价格的上升,我们预期对住房的需求人数减少,即我们预期β3估计值的符号为负,回归结果与直觉相符。出乎预料的是,地方税与州税为不显着的。由于税收的增加将使可支配收入降低,所以我们预期住房的需求将下降。虽然模型A是这种情况,但它们的影响却非常微弱。3-1
7.假设要求你建立一个计量经济模型来说明在学校跑道上慢跑一英里或一英里以上的人数,以便决定是否修建第二条跑道以满足所有的锻炼者。你通过整个学年收集数据,得到两个可能的解释性方程:方程A: 方程B: 其中:——某天慢跑者的人数——该天降雨的英寸数——该天日照的小时数——该天的最高温度(按华氏温度)——第二天需交学期论文的班级数请回答下列问题:(1)这两个方程你认为哪个更合理些,为什么(2)为什么用相同的数据去估计相同变量的系数得到不同的符号答:方程B更合理些。原因是:方程B中的参数估计值的符号与现实更接近些,如与日照的小时数同向变化,天长则慢跑的人会多些;与第二天需交学期论文的班级数成反向变化,这一点在学校的跑道模型中是一个合理的解释变量。解释变量的系数表明该变量的单位变化在方程中其他解释变量不变的条件下对被解释变量的影响,在方程A和方程B中由于选择了不同的解释变量,如方程A选择的是“该天的最高温度”而方程B选择的是“第二天需交学期论文的班级数”,由此造成与这两个变量之间的关系不同,所以用相同的数据估计相同的变量得到不同的符号。3-1
9.假定以校园内食堂每天卖出的盒饭数量作为被解释变量,盒饭价格、气温、附近餐厅的盒饭价格、学校当日的学生数量(单位:千人)作为解释变量,进行回归分析;假设不管是否有假期,食堂都营业。不幸的是,食堂内的计算机被一次病毒侵犯,所有的存储丢失,无法恢复,你不能说出独立变量分别代表着哪一项!下面是回归结果(括号内为标准差):() 要求:(1)试判定每项结果对应着哪一个变量(2)对你的判定结论做出说明。答:答案并不唯一,猜测为:为学生数量,为附近餐厅的盒饭价格,为气温,为校园内食堂的盒饭价格;理由是被解释变量应与学生数量成正比,并且应该影响显着;与本食堂盒饭价格成反比,这与需求理论相吻合;与附近餐厅的盒饭价格成正比,因为彼此是替代品;与气温的变化关系不是十分显着,因为大多数学生不会因为气温升高不吃饭。3-2
8.考虑以下预测的回归方程: 其中:——第t年的玉米产量(蒲式耳/亩)——第t年的施肥强度(磅/亩)——第t年的降雨量(英寸)要求回答下列问题:(1)从和对的影响方面,说出本方程中系数和的含义;(2)常数项是否意味着玉米的负产量可能存在(3)假定的真实值为,则估计值是否有偏为什么(4)假定该方程并不满足所有的古典模型假设,即并不是最佳线性无偏估计值,则是否意味着的真实值绝对不等于为什么
题目解答
答案
解: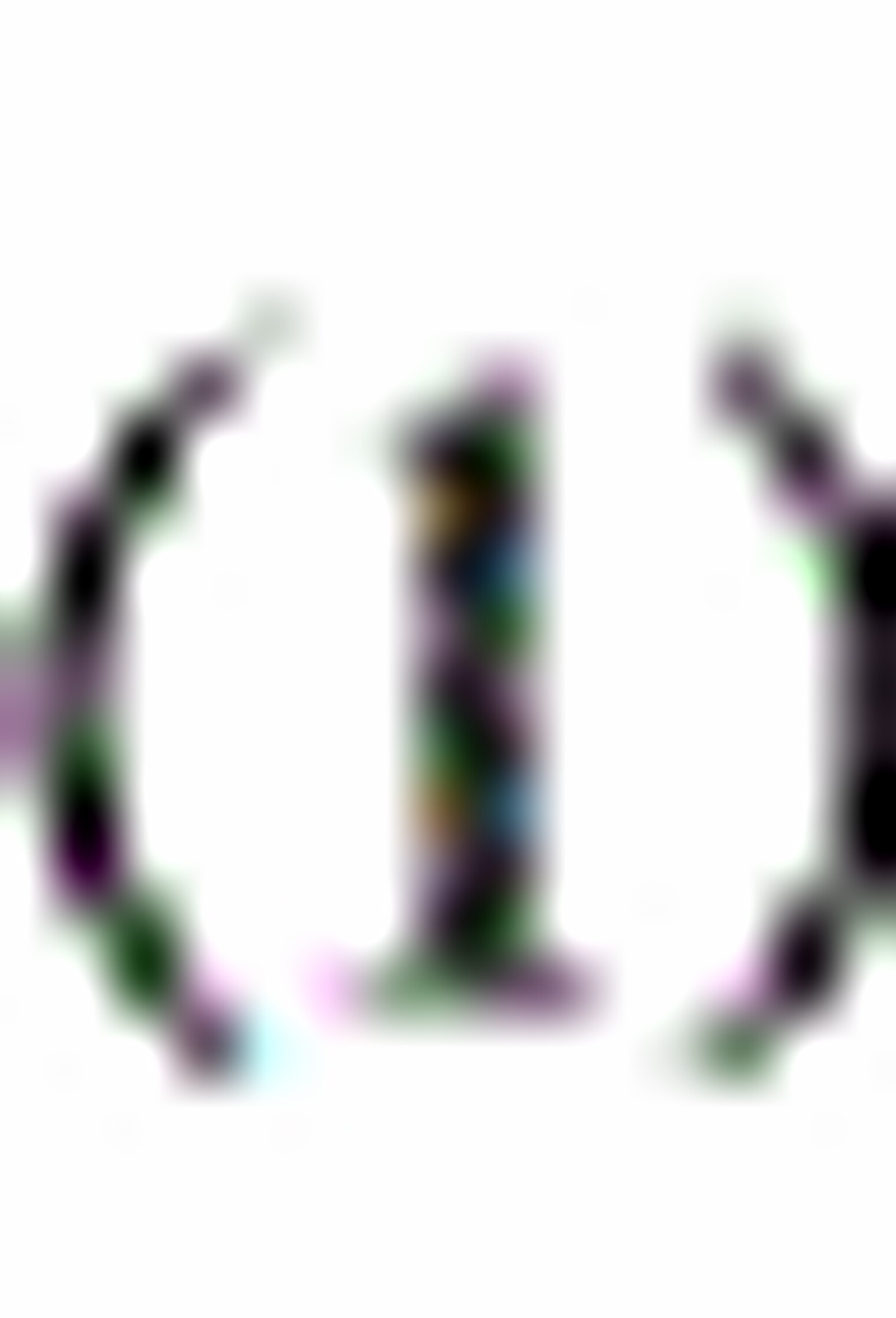 在降雨量不变时,每亩增加一磅肥料将使第
在降雨量不变时,每亩增加一磅肥料将使第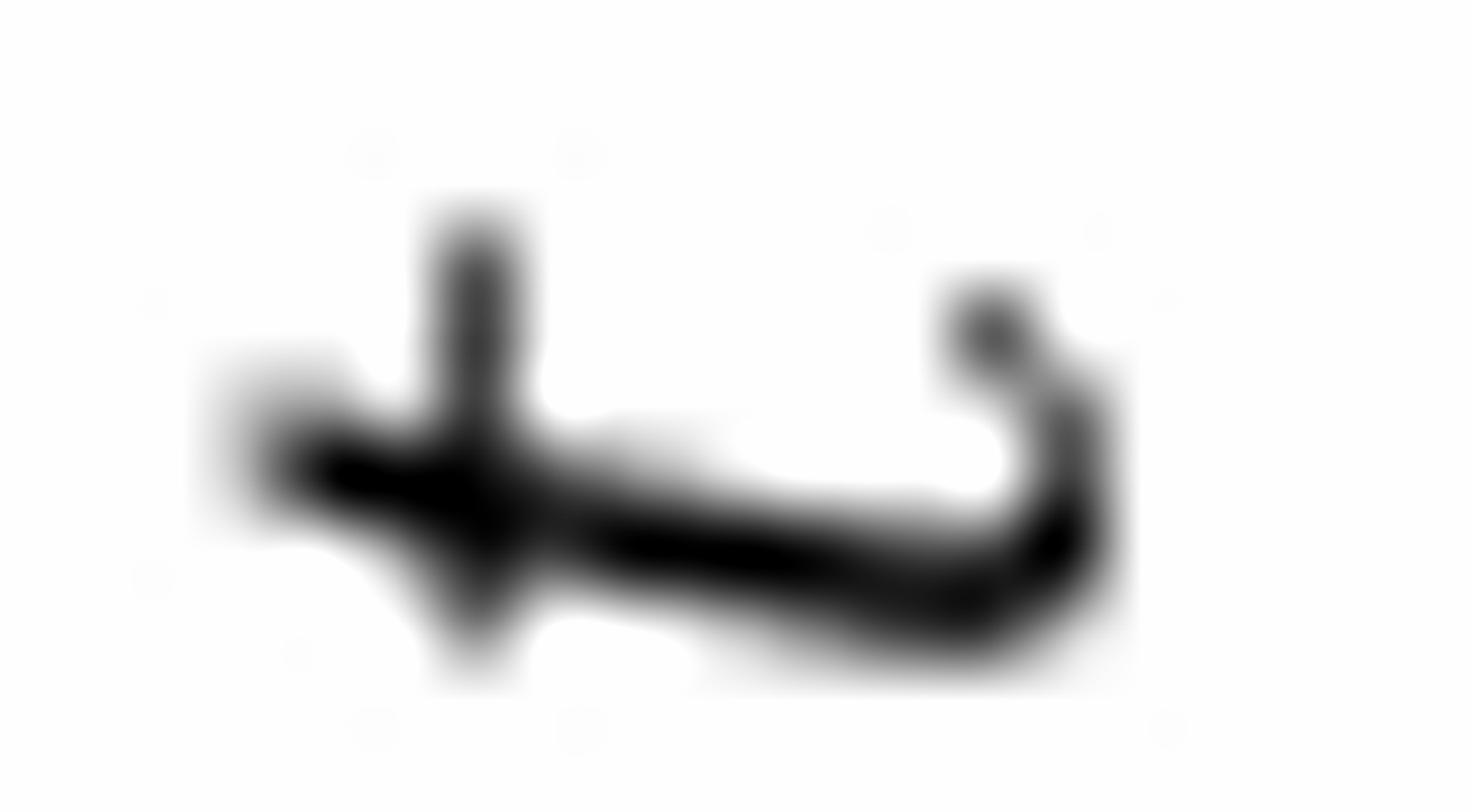 年的玉米产量增加蒲式耳/亩;在每亩施肥量不变的情况下,每增加一英寸的降雨量将使第年的玉米产量增加蒲式耳/亩;
年的玉米产量增加蒲式耳/亩;在每亩施肥量不变的情况下,每增加一英寸的降雨量将使第年的玉米产量增加蒲式耳/亩;
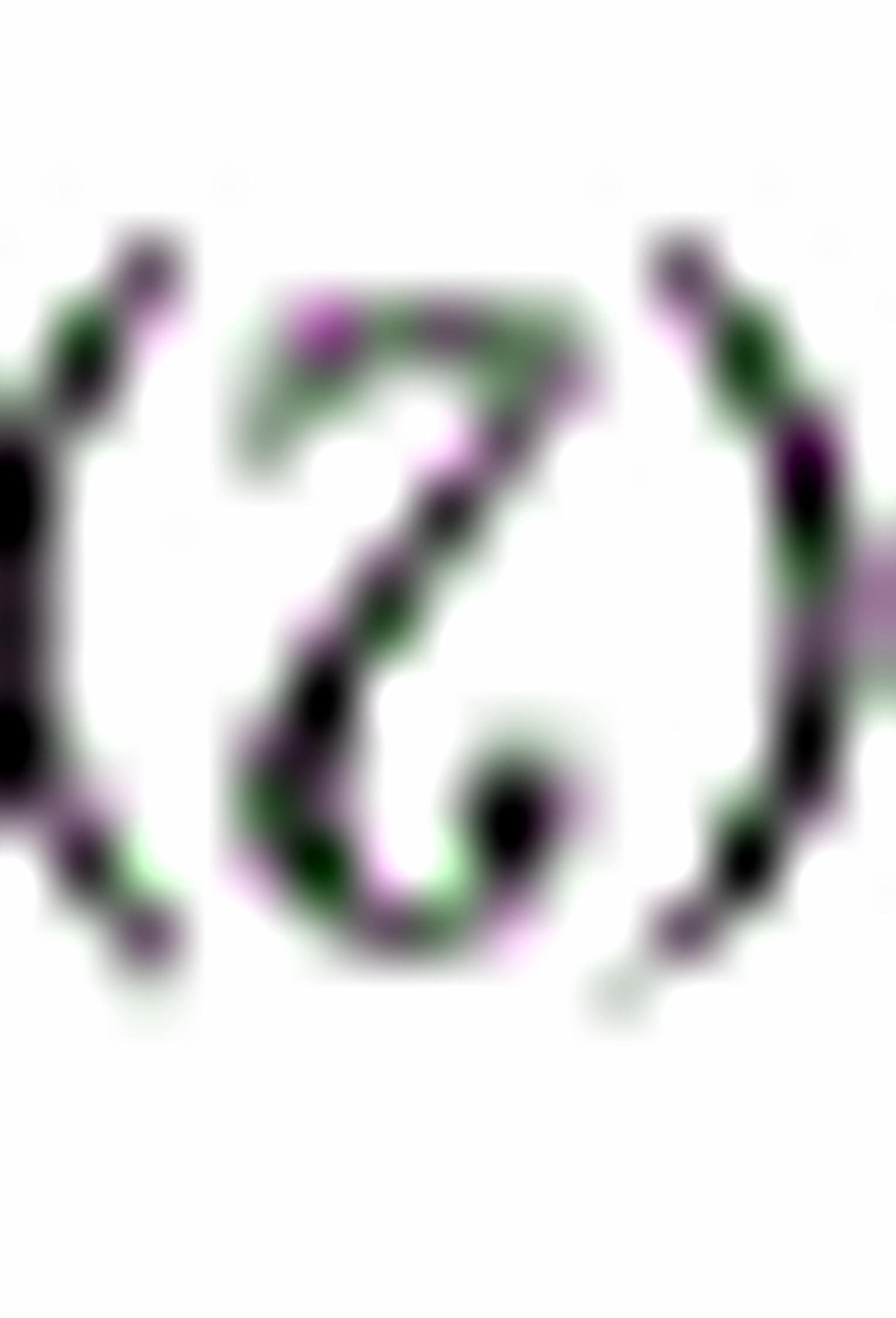 在种地的一年中不施肥、也不下雨的现象同时发生的可能性极小,所以玉米的负产量不可能存在;
在种地的一年中不施肥、也不下雨的现象同时发生的可能性极小,所以玉米的负产量不可能存在;
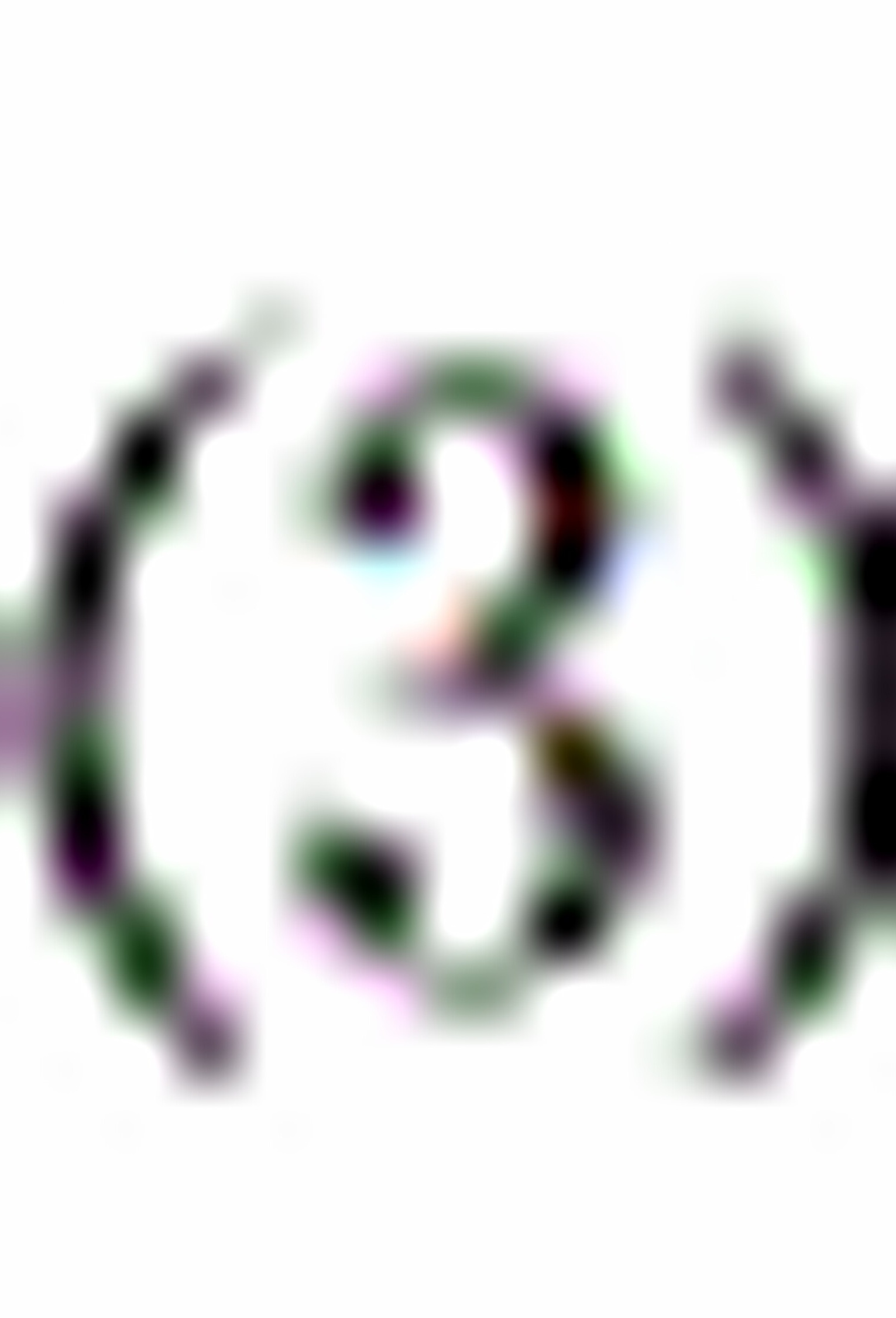 如果
如果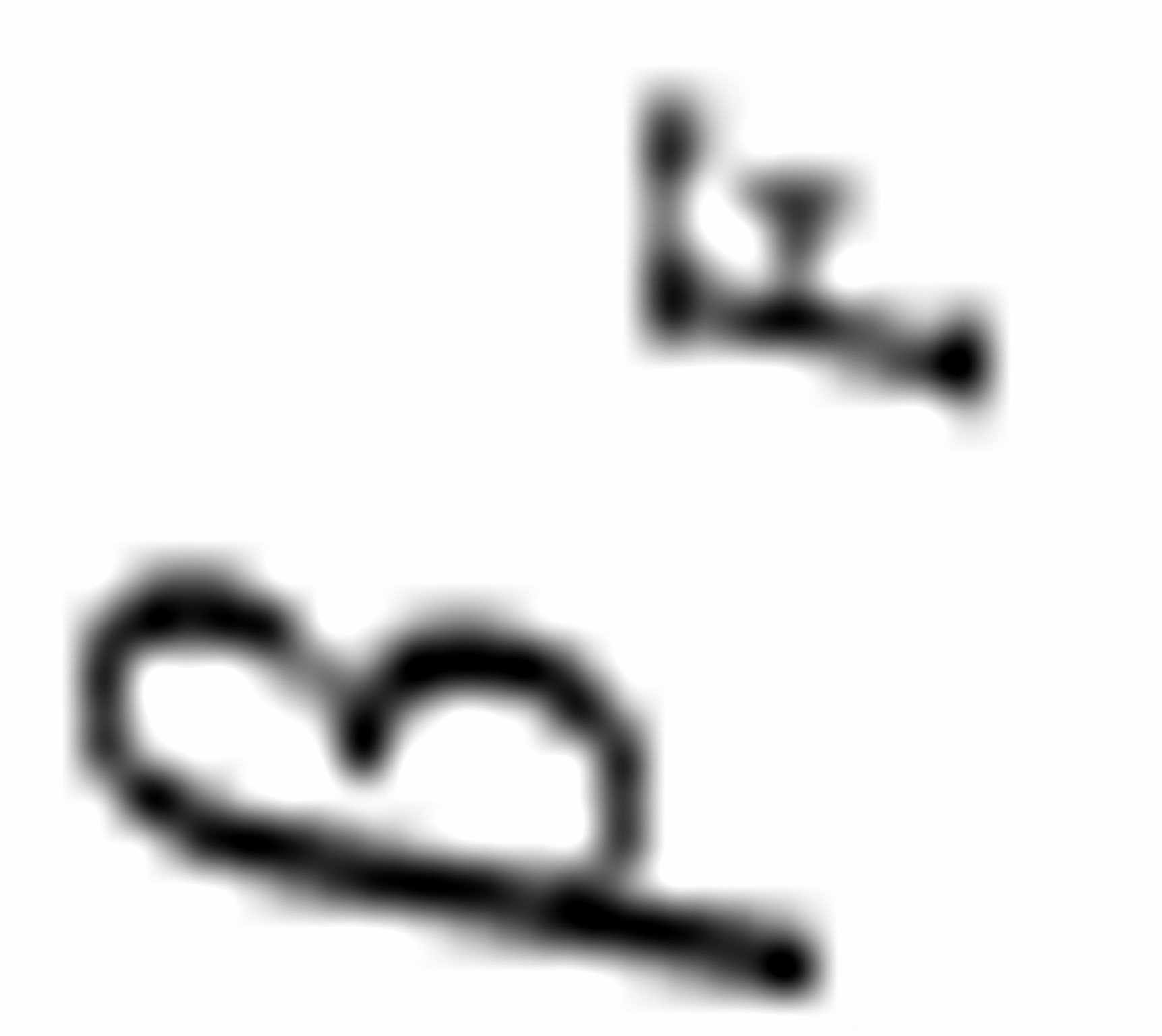 的真实值为,并不能说明是有偏的估计,理由是是本题估计的参数,而是从总体得到的系数的均值。
的真实值为,并不能说明是有偏的估计,理由是是本题估计的参数,而是从总体得到的系数的均值。
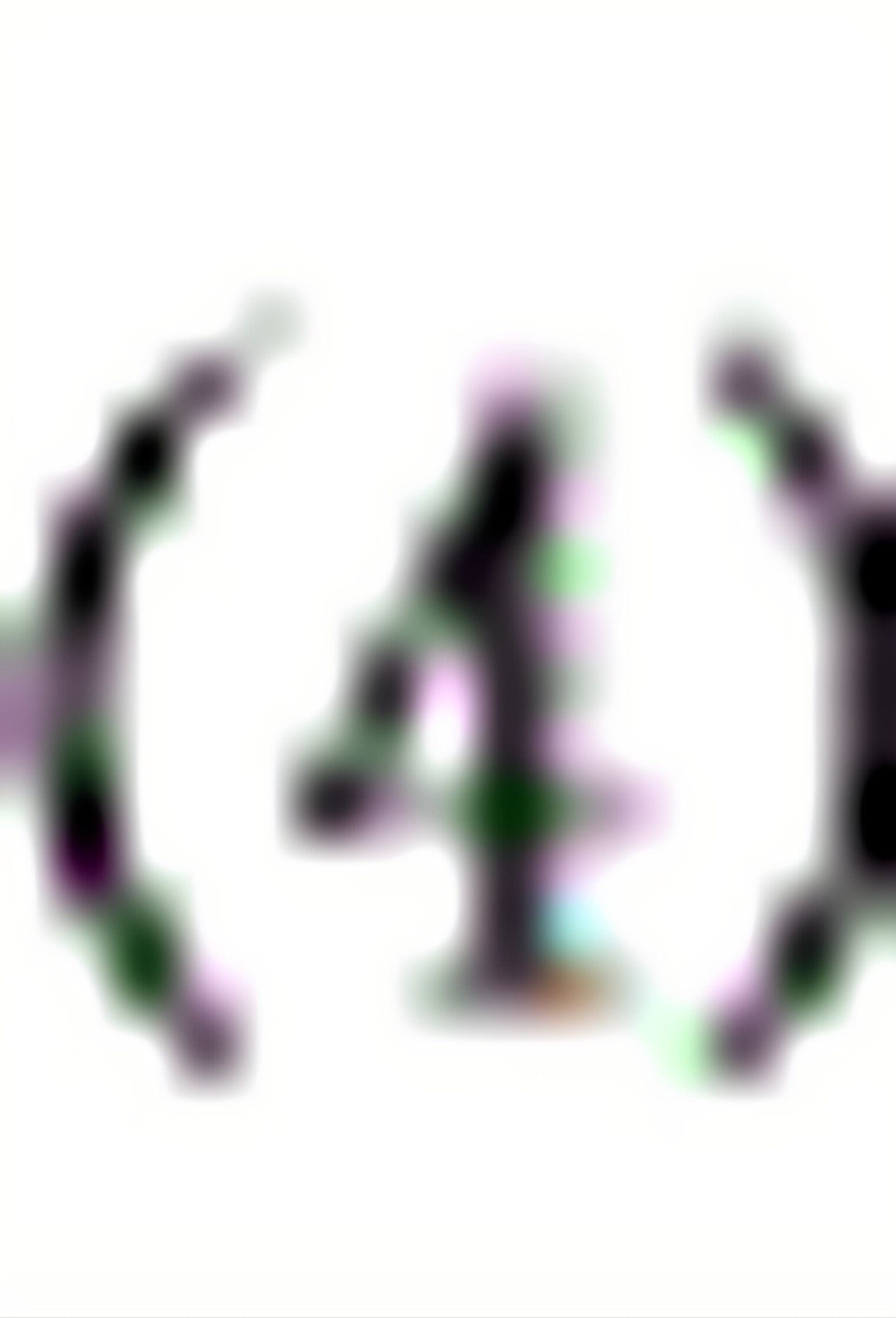 不一定。即便该方程并不满足所有的古典模型假设、不是最佳线性无偏估计值,也有可能得出的估计系数等于。
不一定。即便该方程并不满足所有的古典模型假设、不是最佳线性无偏估计值,也有可能得出的估计系数等于。