题目
某个计算机系统有120个终端,在某一指定时间内每个终端有5%的时间在使用,假定各个终端用与否是相互独立的,试求这一指定时间内使用的终端个数X在10个到20个之间的概率.
某个计算机系统有120个终端,在某一指定时间内每个终端有5%的时间在使用,假定各个终端用与否是相互独立的,试求这一指定时间内使用的终端个数X在10个到20个之间的概率.
题目解答
答案
由题知各个终端用与否相互独立,符合二项分布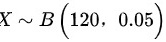 ,np=120
,np=120 0.05=6,np(1-p)=5.7
0.05=6,np(1-p)=5.7
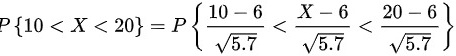
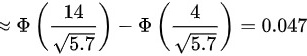
解析
考查要点:本题主要考查二项分布的正态近似应用,以及如何利用连续性修正进行概率计算。
解题核心思路:
- 识别分布类型:题目中每个终端独立使用,符合二项分布$X \sim B(n=120, p=0.05)$。
- 正态近似条件:当$n$较大且$p$不极端时,可用均值$\mu = np$、方差$\sigma^2 = np(1-p)$的正态分布近似。
- 连续性修正:因二项分布是离散的,用连续正态分布近似时需对边界值进行调整(如$10$调整为$10.5$,$20$调整为$19.5$)。
- 标准化与查表:将原始值转化为标准正态变量$Z$,通过查标准正态分布表计算概率。
破题关键点:
- 正确应用连续性修正是提高近似精度的关键步骤。
- 准确计算均值与标准差,并正确标准化。
步骤1:确定分布参数
- 二项分布参数:$n=120$,$p=0.05$,故$\mu = np = 6$,$\sigma^2 = np(1-p) = 5.7$,$\sigma = \sqrt{5.7} \approx 2.387$。
步骤2:应用连续性修正
原问题$P(10 < X < 20)$对应离散取值$X=11,12,\dots,19$,修正后区间为$10.5 < X < 19.5$。
步骤3:标准化为标准正态变量
计算修正后的上下限对应的$Z$值:
- 下限:$Z_1 = \dfrac{10.5 - 6}{\sqrt{5.7}} \approx \dfrac{4.5}{2.387} \approx 1.885$
- 上限:$Z_2 = \dfrac{19.5 - 6}{\sqrt{5.7}} \approx \dfrac{13.5}{2.387} \approx 5.656$
步骤4:查标准正态分布表
- $P(Z < 5.656) \approx 1$(因$Z$值极大)
- $P(Z < 1.885) \approx 0.9693$(查表得$Z=1.88$对应$0.9693$,$Z=1.89$对应$0.9696$,取中间值)
步骤5:计算概率差
$P(10 < X < 20) \approx 1 - 0.9693 = 0.0307$