题目
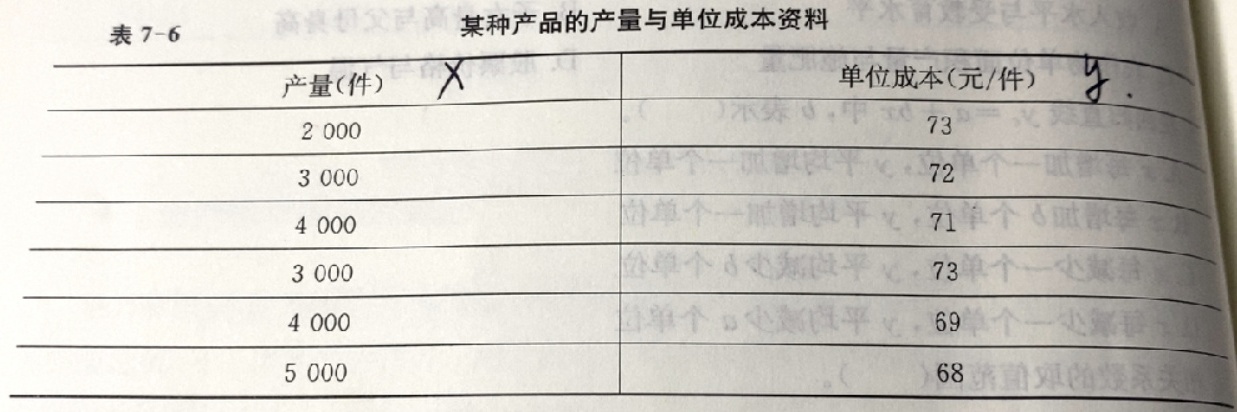
某种产品的产量与单位成本的资料如表 7 - 6 所示.表 7-6 某种产品的产量与单位成本资料-|||-产量(件) 单位成本(元/件)-|||-2000 73-|||-3000 72-|||-4000 71-|||-3000 73-|||-4000 单个 69-|||-5000 68要求: ( 1 ) 计算两个变量之间的线性相关系数 判断其相关方向和程度 .( 2 ) 建立直线回归方程,并解释回归系数的实际经济意义. ( 3 ) 如果 产量 7000 件,预测单位成本.
某种产品的产量与单位成本的资料如表 7 - 6 所示.
要求:
( 1 ) 计算两个变量之间的线性相关系数 判断其相关方向和程度 .
( 2 ) 建立直线回归方程,并解释回归系数的实际经济意义.
( 3 ) 如果 产量 7000 件,预测单位成本.
题目解答
答案
(1)
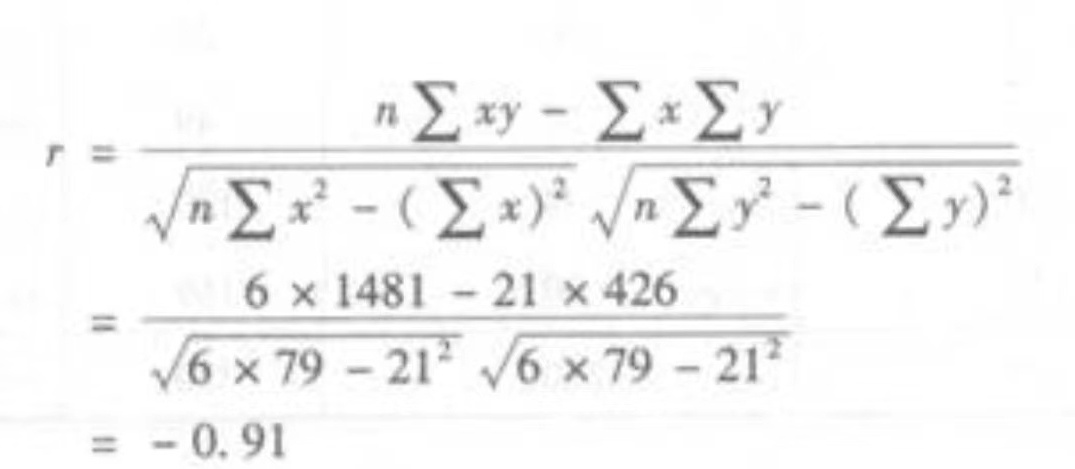
表明产量与单位成本高度负相关。
(2)

直线回归方程为y=77.37-1.82,x斜率即回归系数b=-1.82的经济意义,该产品的产量每增加1千件,则该产品的生产成本将平均降低1.82元。
(3)将7000代入回归线方程,算得y=77.37-1.82 7=64.63(元)
7=64.63(元)
等到产量达到7000件,产品的生产成本会降低到64.63元。
解析
步骤 1:计算相关系数
首先,我们需要计算产量(x)和单位成本(y)之间的线性相关系数(r)。相关系数的计算公式为:
\[ r = \frac{n\sum xy - \sum x \sum y}{\sqrt{(n\sum x^2 - (\sum x)^2)(n\sum y^2 - (\sum y)^2)}} \]
其中,n是样本数量,\(\sum xy\)是产量和单位成本乘积的总和,\(\sum x\)是产量的总和,\(\sum y\)是单位成本的总和,\(\sum x^2\)是产量平方的总和,\(\sum y^2\)是单位成本平方的总和。
步骤 2:计算回归方程
接下来,我们需要建立产量(x)和单位成本(y)之间的直线回归方程。回归方程的计算公式为:
\[ y = a + bx \]
其中,a是截距,b是斜率。斜率b的计算公式为:
\[ b = \frac{n\sum xy - \sum x \sum y}{n\sum x^2 - (\sum x)^2} \]
截距a的计算公式为:
\[ a = \overline{y} - b\overline{x} \]
其中,\(\overline{x}\)是产量的平均值,\(\overline{y}\)是单位成本的平均值。
步骤 3:预测单位成本
最后,我们需要根据回归方程预测产量为7000件时的单位成本。将x=7000代入回归方程,计算出y的值。
首先,我们需要计算产量(x)和单位成本(y)之间的线性相关系数(r)。相关系数的计算公式为:
\[ r = \frac{n\sum xy - \sum x \sum y}{\sqrt{(n\sum x^2 - (\sum x)^2)(n\sum y^2 - (\sum y)^2)}} \]
其中,n是样本数量,\(\sum xy\)是产量和单位成本乘积的总和,\(\sum x\)是产量的总和,\(\sum y\)是单位成本的总和,\(\sum x^2\)是产量平方的总和,\(\sum y^2\)是单位成本平方的总和。
步骤 2:计算回归方程
接下来,我们需要建立产量(x)和单位成本(y)之间的直线回归方程。回归方程的计算公式为:
\[ y = a + bx \]
其中,a是截距,b是斜率。斜率b的计算公式为:
\[ b = \frac{n\sum xy - \sum x \sum y}{n\sum x^2 - (\sum x)^2} \]
截距a的计算公式为:
\[ a = \overline{y} - b\overline{x} \]
其中,\(\overline{x}\)是产量的平均值,\(\overline{y}\)是单位成本的平均值。
步骤 3:预测单位成本
最后,我们需要根据回归方程预测产量为7000件时的单位成本。将x=7000代入回归方程,计算出y的值。