设总体X的概率密度函数为-|||-f(x)= ) (e)^-(x-theta ), xgeqslant theta 0, xlt theta .-|||-X1,X2,···,Nn是来自总体X的样本,试求未知参数θ的矩估计量.

题目解答
答案
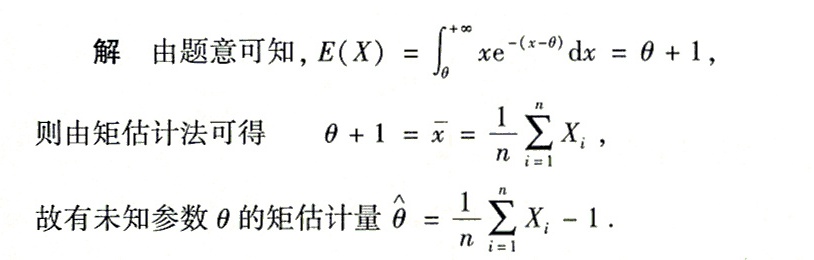
解析
本题考查矩估计法求未知参数的估计量。解题思路是先根据总体的概率密度函数求出总体的一阶矩(即期望),然后令总体的一阶矩等于样本的一阶矩(即样本均值),最后解出未知参数的矩估计量。
步骤一:计算总体 $X$ 的期望 $E(X)$
已知总体 $X$ 的概率密度函数为 $f(x)=\begin{cases}e^{-(x - \theta)}, & x\geq\theta \\ 0, & x\lt\theta\end{cases}$,根据期望的定义 $E(X)=\int_{-\infty}^{+\infty}xf(x)dx$,可得:
$\begin{align*}E(X)&=\int_{-\infty}^{+\infty}xf(x)dx\\&=\int_{\theta}^{+\infty}x e^{-(x - \theta)}dx\end{align*}$
令 $t = x - \theta$,则 $x = t + \theta$,$dx = dt$,当 $x = \theta$ 时,$t = 0$;当 $x\to +\infty$ 时,$t\to +\infty$,那么上式可化为:
$\begin{align*}E(X)&=\int_{0}^{+\infty}(t + \theta)e^{-t}dt\\&=\int_{0}^{+\infty}t e^{-t}dt + \theta\int_{0}^{+\infty}e^{-t}dt\end{align*}$
根据分部积分法求 $\int_{0}^{+\infty}t e^{-t}dt$,设 $u = t$,$dv = e^{-t}dt$,则 $du = dt$,$v = -e^{-t}$,可得:
$\begin{align*}\int_{0}^{+\infty}t e^{-t}dt&=\left[-t e^{-t}\right]_{0}^{+\infty}+\int_{0}^{+\infty}e^{-t}dt\\&=0 + \left[-e^{-t}\right]_{0}^{+\infty}\\&= 1\end{align*}$
而 $\int_{0}^{+\infty}e^{-t}dt = \left[-e^{-t}\right]_{0}^{+\infty}= 1$,所以 $E(X)=1 + \theta$。
步骤二:根据矩估计法建立方程
矩估计法的基本思想是用样本矩来估计总体矩。样本的一阶矩为样本均值 $\overline{X}=\frac{1}{n}\sum_{i = 1}^{n}X_i$,令总体的一阶矩 $E(X)$ 等于样本的一阶矩 $\overline{X}$,即:
$\theta + 1 = \overline{X}=\frac{1}{n}\sum_{i = 1}^{n}X_i$
步骤三:求解未知参数 $\theta$ 的矩估计量
由 $\theta + 1 = \frac{1}{n}\sum_{i = 1}^{n}X_i$,移项可得 $\theta$ 的矩估计量为:
$\hat{\theta}=\frac{1}{n}\sum_{i = 1}^{n}X_i - 1$