题目
频率-|||-组距-|||-0.020-|||-0.015-|||-0.010-|||-0.005-|||-o 20 40 60 80 100 时间2021年五一节期间,我国高速公路继续执行“节假日高速公路免费政策”.某路桥公司为掌握五一节期间车辆出行的高峰情况,在某高速公路收费站点记录了3日上午9:20~10:40这一时间段内通过的车辆数,统计发现这一时间段内共有600辆车通过该收费站点,它们通过该收费站点的时刻的频率分布直方图如图所示,其中时间段9:20~9:40记作[20,40),9:40~10:00记作[40,60),10:00~10:20记作[60,80),10:20~10:40记作[80,100),例如:9:46,记作时刻46.(1)估计这600辆车在9:20~10:40时间内通过该收费站点的时刻的平均值(同一组中的数据用该组区间的中点值代替);(2)为了对数据进行分析,现采用分层抽样的方法从这600辆车中抽取10辆,再从这10辆车中随机抽取4辆,设抽到的4辆车中,在9:20~10:00之间通过的车辆数为X,求X的分布列;(3)根据大数据分析,车辆在每天通过该收费站点的时刻T服从正态分布N~(μ,σ2),其中μ可用3日数据中的600辆车在9:20~10:40之间通过该收费站点的时刻的平均值近似代替,σ2用样本的方差近似代替(同一组中的数据用该组区间的中点值代替).假如4日上午9:20~10:40这一时间段内共有1000辆车通过该收费站点,估计在9:46~10:40之间通过的车辆数(结果保留到整数).附:若随机变量T服从正态分布N(μ,σ2),则P(μ-σ<T≤μ+σ)=0.6827,P(μ-2σ<T≤μ+2σ)=0.9545,P(μ-3σ<T≤μ+3σ)=0.9973.
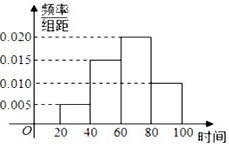 2021年五一节期间,我国高速公路继续执行“节假日高速公路免费政策”.某路桥公司为掌握五一节期间车辆出行的高峰情况,在某高速公路收费站点记录了3日上午9:20~10:40这一时间段内通过的车辆数,统计发现这一时间段内共有600辆车通过该收费站点,它们通过该收费站点的时刻的频率分布直方图如图所示,其中时间段9:20~9:40记作[20,40),9:40~10:00记作[40,60),10:00~10:20记作[60,80),10:20~10:40记作[80,100),例如:9:46,记作时刻46.
2021年五一节期间,我国高速公路继续执行“节假日高速公路免费政策”.某路桥公司为掌握五一节期间车辆出行的高峰情况,在某高速公路收费站点记录了3日上午9:20~10:40这一时间段内通过的车辆数,统计发现这一时间段内共有600辆车通过该收费站点,它们通过该收费站点的时刻的频率分布直方图如图所示,其中时间段9:20~9:40记作[20,40),9:40~10:00记作[40,60),10:00~10:20记作[60,80),10:20~10:40记作[80,100),例如:9:46,记作时刻46.(1)估计这600辆车在9:20~10:40时间内通过该收费站点的时刻的平均值(同一组中的数据用该组区间的中点值代替);
(2)为了对数据进行分析,现采用分层抽样的方法从这600辆车中抽取10辆,再从这10辆车中随机抽取4辆,
设抽到的4辆车中,在9:20~10:00之间通过的车辆数为X,求X的分布列;
(3)根据大数据分析,车辆在每天通过该收费站点的时刻T服从正态分布N~(μ,σ2),其中μ可用3日数据中的600辆车在9:20~10:40之间通过该收费站点的时刻的平均值近似代替,σ2用样本的方差近似代替(同一组中的数据用该组区间的中点值代替).假如4日上午9:20~10:40这一时间段内共有1000辆车通过该收费站点,估计在9:46~10:40之间通过的车辆数(结果保留到整数).
附:若随机变量T服从正态分布N(μ,σ2),则P(μ-σ<T≤μ+σ)=0.6827,P(μ-2σ<T≤μ+2σ)=0.9545,P(μ-3σ<T≤μ+3σ)=0.9973.
题目解答
答案
解:(1)这600辆车在9:20~10:40时间段内通过该收费点的时刻的平均值为:
(30×0.005+50×0.015+70×0.020+90×0.010)×20=64.
(2)由频率分布直方图和分层抽样的方法可知,抽取的10辆车中,
在10:00前通过的车辆数就是位于时间分组[20,60]这一区间内的车辆数,
即(0.005+0.015)×20×10=4,所以X的可能的取值为0,1,2,3,4.
所以$P(X=0)=\frac{{C_6^4}}{{C_{10}^4}}=\frac{1}{{14}}$,
$P(X=1)=\frac{{C_6^3C_4^1}}{{C_{10}^4}}=\frac{8}{{21}}$,
$P(X=2)=\frac{{C_6^2C_4^2}}{{C_{10}^4}}=\frac{3}{7}$,
$P(X=3)=\frac{{C_6^1C_4^3}}{{C_{10}^4}}=\frac{4}{{35}}$,
$P(X=4)=\frac{{C_4^4}}{{C_{10}^4}}=\frac{1}{{210}}$.
所以X的分布列为:
(3)由(1)得μ=64,$σ_{车辆}^2={(30-64)^2}×0.1+{(50-64)^2}×0.3+{(70-64)^2}×0.4+{(90-64)^2}×0.2=324$.
所以σ=18,估计在9:46~10:40之间通过的车辆数也就是在[46,100)通过的车辆数,
由T~N(64,182),得:
$P(64-18≤T≤64+2×18)=\frac{{P(μ-σ<T≤μ+σ)}}{2}+\frac{{P(μ-2σ<T≤μ+2σ)}}{2}=0.8186$,
所以估计在在9:46~10:40之间通过的车辆数为1000×0.8186≈819.
(30×0.005+50×0.015+70×0.020+90×0.010)×20=64.
(2)由频率分布直方图和分层抽样的方法可知,抽取的10辆车中,
在10:00前通过的车辆数就是位于时间分组[20,60]这一区间内的车辆数,
即(0.005+0.015)×20×10=4,所以X的可能的取值为0,1,2,3,4.
所以$P(X=0)=\frac{{C_6^4}}{{C_{10}^4}}=\frac{1}{{14}}$,
$P(X=1)=\frac{{C_6^3C_4^1}}{{C_{10}^4}}=\frac{8}{{21}}$,
$P(X=2)=\frac{{C_6^2C_4^2}}{{C_{10}^4}}=\frac{3}{7}$,
$P(X=3)=\frac{{C_6^1C_4^3}}{{C_{10}^4}}=\frac{4}{{35}}$,
$P(X=4)=\frac{{C_4^4}}{{C_{10}^4}}=\frac{1}{{210}}$.
所以X的分布列为:
| X | 0 | 1 | 2 | 3 | 4 |
| P | $\frac{1}{{14}}$ | $\frac{8}{{21}}$ | $\frac{3}{7}$ | $\frac{4}{{35}}$ | $\frac{1}{{210}}$ |
所以σ=18,估计在9:46~10:40之间通过的车辆数也就是在[46,100)通过的车辆数,
由T~N(64,182),得:
$P(64-18≤T≤64+2×18)=\frac{{P(μ-σ<T≤μ+σ)}}{2}+\frac{{P(μ-2σ<T≤μ+2σ)}}{2}=0.8186$,
所以估计在在9:46~10:40之间通过的车辆数为1000×0.8186≈819.
解析
- 平均值计算:利用频率分布直方图,通过各组中点值与对应频率的加权平均计算总体平均值,需注意组距对概率的影响。
- 分层抽样与超几何分布:分层抽样按比例确定各层样本数,再用超几何分布描述无放回抽样中特定类别数量的分布。
- 正态分布应用:用样本均值和方差估计正态参数,通过已知概率区间计算特定区间的概率,结合总车辆数估计数量。
第(1)题
确定各组中点值与权重
- 时间段中点值:30([20,40))、50([40,60))、70([60,80))、90([80,100))。
- 频率对应概率:每组概率为频率×组距(20),即:
- [20,40): $0.005 \times 20 = 0.1$
- [40,60): $0.015 \times 20 = 0.3$
- [60,80): $0.020 \times 20 = 0.4$
- [80,100): $0.010 \times 20 = 0.2$
计算加权平均
平均值 $\bar{x} = 30 \times 0.1 + 50 \times 0.3 + 70 \times 0.4 + 90 \times 0.2 = 64$。
第(2)题
确定分层抽样比例
- [20,60)时间段车辆数占比:$(0.005 + 0.015) \times 20 = 0.4$,抽取 $10 \times 0.4 = 4$ 辆。
- 其余时间段抽取 $10 - 4 = 6$ 辆。
超几何分布建模
- 总体中“成功”数 $K=4$,抽取 $n=4$,总样本 $N=10$。
- 概率公式:$P(X=k) = \frac{\binom{4}{k} \binom{6}{4-k}}{\binom{10}{4}}$,计算各 $k$ 的概率。
第(3)题
计算样本方差
- 方差公式:$\sigma^2 = \sum (\text{中点值} - \mu)^2 \times \text{概率}$,计算得 $\sigma^2 = 324$,即 $\sigma = 18$。
确定区间概率
- 时刻46对应 $\mu - \sigma = 64 - 18 = 46$,时刻100对应 $\mu + 2\sigma = 64 + 36 = 100$。
- 概率计算:$P(46 \leq T < 100) = P(\mu - \sigma \leq T \leq \mu + 2\sigma) = \frac{0.6827}{2} + \frac{0.9545 - 0.6827}{2} = 0.8186$。
估计车辆数
- 结果:$1000 \times 0.8186 \approx 819$。