题目
某车间有甲、乙两个生产小组,甲组平均每个工人的日产量为22件,标准差为3.5件;乙组工人日产量资料:日产量(件)工人数(人)f组中值xxf(x-)(x-)2(x-)2 f10-121011110-63636013-152014280-3918016-18301751019-21402080039360合计------------试比较甲、乙两生产小组哪个组的日产量更有代表性?
某车间有甲、乙两个生产小组,甲组平均每个工人的日产量为22件,标准差为3.5件;
乙组工人日产量资料:
日产量(件)
工人数(人)f
组中值x
xf
(x-)
(x-)2
(x-)2 f
10-12
10
11
110
-6
36
360
13-15
20
14
280
-3
9
180
16-18
30
17
510
19-21
40
20
800
3
9
360
合计
----
----
----
试比较甲、乙两生产小组哪个组的日产量更有代表性?
题目解答
答案
解: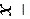 乙=
乙=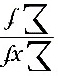 =
=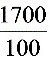 =17(件)
=17(件)  =
=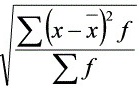 =
=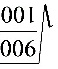 =3(件)
=3(件)
v 乙=
乙=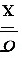 ×%=
×%=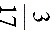 ×%=17.65% v甲=×%=
×%=17.65% v甲=×%=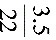 ×%=15.91%
×%=15.91%
∵v乙>v甲
答:甲小组日产量更有代表性。
解析
步骤 1:计算乙组的平均日产量
根据题目给出的乙组工人日产量资料,计算乙组的平均日产量。平均日产量的计算公式为:
$$
\overline{x} = \frac{\sum xf}{\sum f}
$$
其中,$\sum xf$ 是各组中值与工人数的乘积之和,$\sum f$ 是工人数的总和。
步骤 2:计算乙组的标准差
根据题目给出的乙组工人日产量资料,计算乙组的标准差。标准差的计算公式为:
$$
\sigma = \sqrt{\frac{\sum (x - \overline{x})^2 f}{\sum f}}
$$
其中,$\sum (x - \overline{x})^2 f$ 是各组中值与平均日产量之差的平方与工人数的乘积之和,$\sum f$ 是工人数的总和。
步骤 3:计算甲、乙两组的变异系数
变异系数的计算公式为:
$$
v = \frac{\sigma}{\overline{x}} \times 100\%
$$
其中,$\sigma$ 是标准差,$\overline{x}$ 是平均日产量。
步骤 4:比较甲、乙两组的变异系数
比较甲、乙两组的变异系数,变异系数越小,表示日产量的代表性越强。
根据题目给出的乙组工人日产量资料,计算乙组的平均日产量。平均日产量的计算公式为:
$$
\overline{x} = \frac{\sum xf}{\sum f}
$$
其中,$\sum xf$ 是各组中值与工人数的乘积之和,$\sum f$ 是工人数的总和。
步骤 2:计算乙组的标准差
根据题目给出的乙组工人日产量资料,计算乙组的标准差。标准差的计算公式为:
$$
\sigma = \sqrt{\frac{\sum (x - \overline{x})^2 f}{\sum f}}
$$
其中,$\sum (x - \overline{x})^2 f$ 是各组中值与平均日产量之差的平方与工人数的乘积之和,$\sum f$ 是工人数的总和。
步骤 3:计算甲、乙两组的变异系数
变异系数的计算公式为:
$$
v = \frac{\sigma}{\overline{x}} \times 100\%
$$
其中,$\sigma$ 是标准差,$\overline{x}$ 是平均日产量。
步骤 4:比较甲、乙两组的变异系数
比较甲、乙两组的变异系数,变异系数越小,表示日产量的代表性越强。