某研究者从某市随机抽取 17 岁 健康男生 100 人 并测得其血红蛋白 (g/L) 求得均 数 138.5 标 准差 8.30 经正态性检验其服从正态分布 请回答以下问题 ( 1 ) 试分析该资料应属于何种资料类型 ( 2 ) 试估计该市 17 岁 健康男生的血红蛋白量 ( 3 ) 若测得该市一名 17 岁 健康男生的血红蛋白为 126.0g/L 请判断其血红和〕蛋白量是否正常 ( 4 ) 若再次测得该 100 名 17 岁 健康男生的红细胞数均数为 4.72 ( ^12/L) 标准差 2.36 (^12/L ) 试比较此两项血液指标的变异程度
某研究者从某市随机抽取 17 岁 健康男生 100 人 并测得其血红蛋白 (g/L) 求得均 数 138.5 标 准差 8.30 经正态性检验其服从正态分布 请回答以下问题
( 1 ) 试分析该资料应属于何种资料类型
( 2 ) 试估计该市 17 岁 健康男生的血红蛋白量
( 3 ) 若测得该市一名 17 岁 健康男生的血红蛋白为 126.0g/L 请判断其血红和〕蛋白量是否正常
( 4 ) 若再次测得该 100 名 17 岁 健康男生的红细胞数均数为 4.72 ( 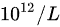 ) 标准差 2.36 ( ) 试比较此两项血液指标的变异程度
) 标准差 2.36 ( ) 试比较此两项血液指标的变异程度
题目解答
答案
(1)该资料属于定量资料,因为血红蛋白的测量值是一个数值变量。
(2)根据样本均数和标准差,可以使用正态分布的性质来估计总体均数的置信区间。由于样本量较大,且经正态性检验服从正态分布,可以使用以下公式:
置信区间 = 均数 ± 1.96×标准差
代入数值可得:
置信区间 = 138.5 ± 1.96×8.30
计算得到置信区间为(121.98,155.02)。
因此,可以估计该市17岁健康男生的血红蛋白量在121.98g/L到155.02g/L之间。
(3)要判断该男生的血红蛋白量是否正常,可以将其与总体均数进行比较。由于总体均数为138.5g/L,而该男生的血红蛋白量为126.0g/L,低于总体均数。
然而,仅根据一个个体的值不能确定其是否正常,因为个体差异是存在的。还需要考虑置信区间。
根据(2)中计算得到的置信区间,该男生的血红蛋白量在置信区间内,因此可以认为他的血红蛋白量在正常范围内。
(4)要比较两项血液指标的变异程度,可以计算它们的变异系数(CV)。
变异系数 = 标准差/均数×100%
对于血红蛋白:
CV =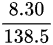 ×100% ≈ 6.0%
×100% ≈ 6.0%
对于红细胞数:
CV = 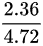 ×100% ≈ 50%
×100% ≈ 50%
比较两者的变异系数,血红蛋白的变异系数为6.0%,红细胞数的变异系数为50%。
因此,红细胞数的变异程度大于血红蛋白的变异程度。
解析
- 资料类型判断:需区分定量资料与分类资料,关键点在于数据是否为数值变量。
- 总体均数估计:利用正态分布特性,通过样本均数和标准差计算置信区间,核心公式为均数±1.96×标准差。
- 个体值判断:需结合总体均数和置信区间,判断个体值是否在正常波动范围内。
- 变异程度比较:因指标单位和均值差异大,必须使用变异系数(CV)消除量纲影响。
第(1)题
定量资料:血红蛋白为连续性数值变量,可无限细分,符合定量资料定义。
第(2)题
确定置信区间公式
总体均数的95%置信区间为:
$\text{置信区间} = \text{均数} \pm 1.96 \times \text{标准差}$
代入数据计算
$138.5 \pm 1.96 \times 8.30 = (121.98, 155.02)$
第(3)题
比较个体值与置信区间
该男生血红蛋白值126.0g/L 在置信区间内,属于正常波动范围。
第(4)题
计算变异系数
$\text{CV(血红蛋白)} = \frac{8.30}{138.5} \times 100\% \approx 6.0\%$
$\text{CV(红细胞数)} = \frac{2.36}{4.72} \times 100\% \approx 50\%$
结论:红细胞数的变异程度显著高于血红蛋白。