题目
聚类分析以及因子分析100个学生数学、物理、化学、语文、历史、英语成绩如下表(部分),请你用科学的方法解释为什么我们会将数学、物理、化学归并为理科,其他的归并为文科。数学物理化学语文历史英语100100100597367991009953636087841007481769185100706576879887687864859195637666799583898979这是一个有趣(yǒuqù)的案例,你可以客观的观测到每一科目(kēmù)的成绩,但你如何可以直接看到理科、文科的情况呢?答:SPSS操作步骤:1)在定义变量(biànliàng)窗口,定义变量数学、物理、化学、语文、历史、英语几个变量2)在录入数据窗口(chuāngkǒu),对数据进行录入。3)依次(yīcì)点击Analyze-----Classify-----Hierarchical Cluster Analysis4)在对话框中,将变量依次放进变量中,然后点击对变量做聚类。结果如下:Case Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance usedCase Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance usedCase Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance usedCase Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance used从上图聚类的结果(jiē guǒ),我们可以看出数学、物理、化学为一类。历史、英语、语文为一类。因子分析的结果(jiē guǒ):Case Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance usedCase Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance usedCase Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance usedCase Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance usedCase Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance usedCase Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance usedCase Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance used6个科目的成绩是我们观测到的外在表现,隐藏在其中的公共因子(yīnzǐ)是什么?SPSS分析(fēnxī)过程因子分析:6科目(kēmù)成绩作为6个原始变量,利用SPSS进行(jìnxíng)因子分析。Case Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance used经过SPSS降维,由公因子(yīnzǐ)方差表看出,默认提取两个公因子,能够解释差异的81%,似乎暗合文科和理科。Case Processing Summary^3-|||-Cases-|||-Valid Missing Total-|||-N Percent N Percent N Percent-|||-7 16.7% 35 83.3% 42 100.0%-|||-a.Squared Euclidean Distance used通过旋转后进行因子的命名与解释,由旋转矩阵可以看出,因子1与语文、历史、英语三科最相关,均在0.8相关度以上,因子2与数学、物理、化学相关,也基本达到0.8以上,这正好与我们经常说的文科和理科不谋而合,因此,将语文、历史、英语三科命名为文科因子;将数学、物理、化学三科命名为理科因子。因子得分排序:综合评价为公共因子合理命名之后,因子分析并没有结束,一般可以(kěyǐ)将因子得分作为变量,用于后续分析步骤。 本例100名学生按照文科和理科因子得分进行排序,可以(kěyǐ)用(语文+历时+英语)及(数学+物理+化学)平均值验证因子得分排序是否合理,同时,也可以观测因子得分为负值时是否影响排序。2.。。。。。聚类分析:下表给出对该产品(chǎnpǐn)8种需求情况,根据该表,请运用聚类分析法,找出哪些地区在该产品需求上有共同特征。(题没看懂) x1 x2 x3 x4 x5 x6 x7 x8 辽宁 7.9 39.77 8.49 12.94 19.27 11.05 2.04 13.29 浙江(zhè jiānɡ) 7.68 50.37 11.35 13.3 19.25 14.59 2.75 14.87 河南(hé nán) 9.42 27.93 8.2 8.14 16.17 9.42 1.55 9.76 甘肃 9.16 27.98 9.01 9.32 15.99 9.1 1.82 11.35 青海 10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.82
聚类分析以及因子分析
100个学生数学、物理、化学、语文、历史、英语成绩如下表(部分),请你用科学的方法解释为什么我们会将数学、物理、化学归并为理科,其他的归并为文科。
数学 | 物理 | 化学 | 语文 | 历史 | 英语 |
100 | 100 | 100 | 59 | 73 | 67 |
99 | 100 | 99 | 53 | 63 | 60 |
87 | 84 | 100 | 74 | 81 | 76 |
91 | 85 | 100 | 70 | 65 | 76 |
87 | 98 | 87 | 68 | 78 | 64 |
85 | 91 | 95 | 63 | 76 | 66 |
79 | 95 | 83 | 89 | 89 | 79 |
这是一个有趣(yǒuqù)的案例,你可以客观的观测到每一科目(kēmù)的成绩,但你如何可以直接看到理科、文科的情况呢?
答:
SPSS操作步骤:
1)在定义变量(biànliàng)窗口,定义变量数学、物理、化学、语文、历史、英语几个变量
2)在录入数据窗口(chuāngkǒu),对数据进行录入。
3)依次(yīcì)点击Analyze-----Classify-----Hierarchical Cluster Analysis
4)在对话框中,将变量依次放进变量中,然后点击对变量做聚类。结果如下:
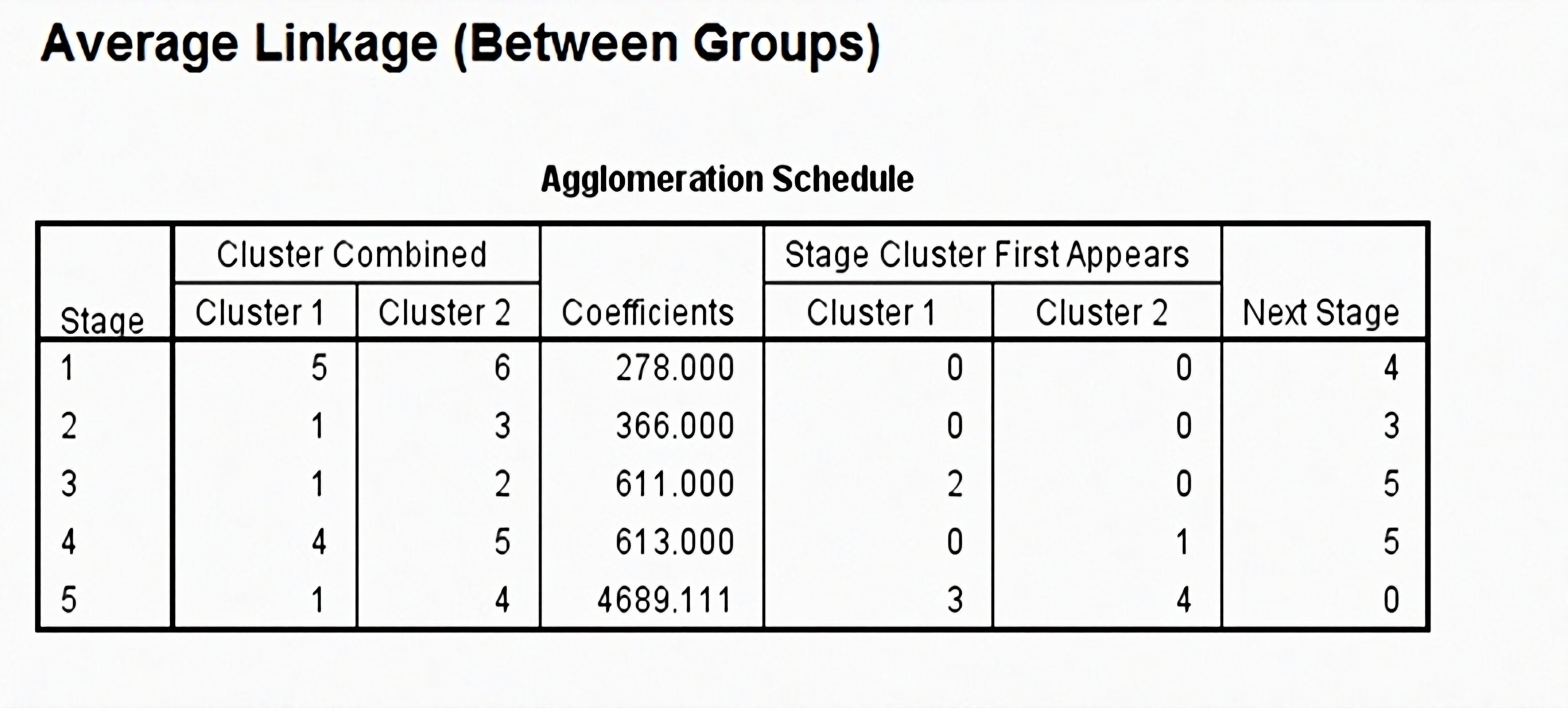
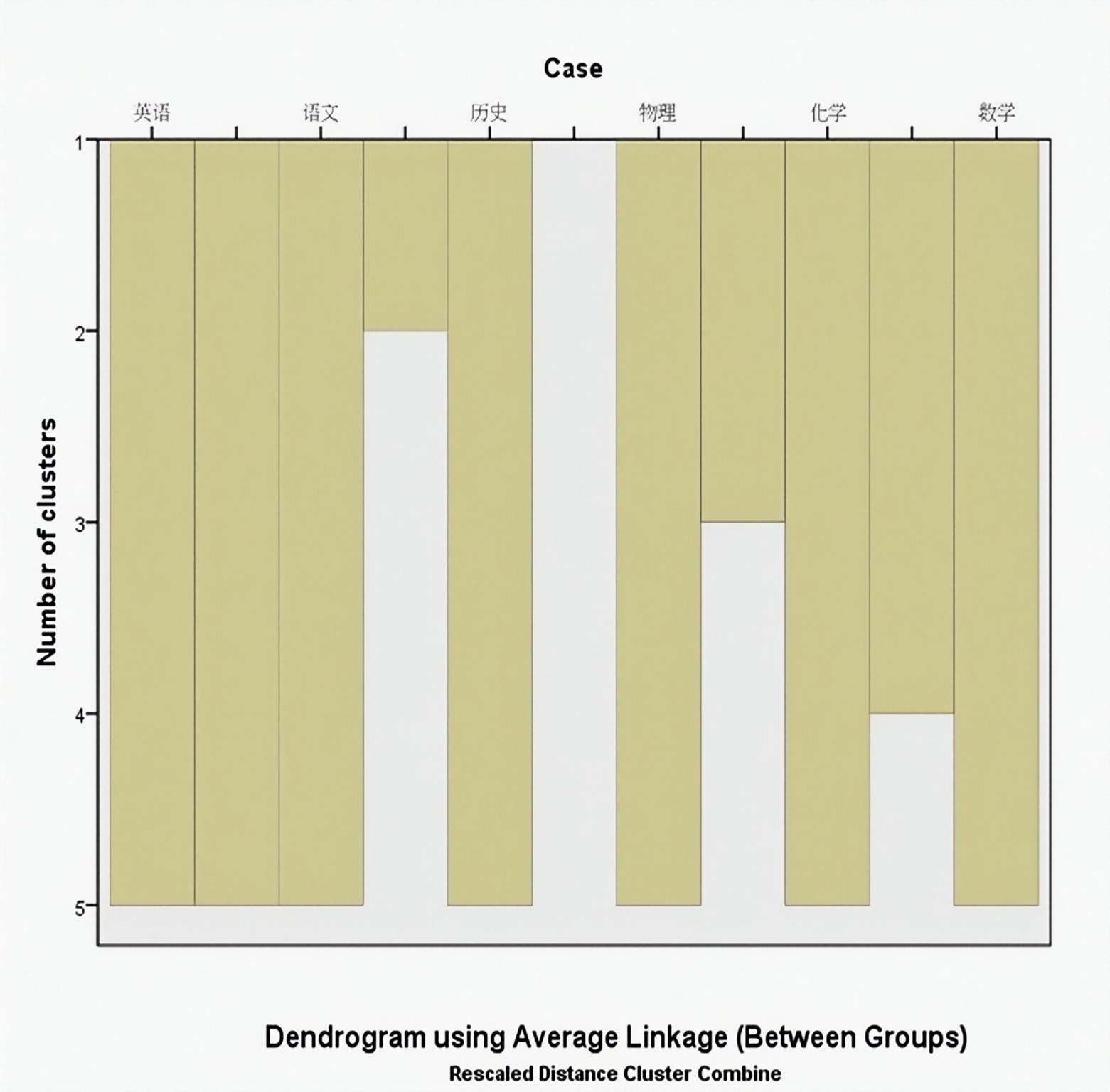
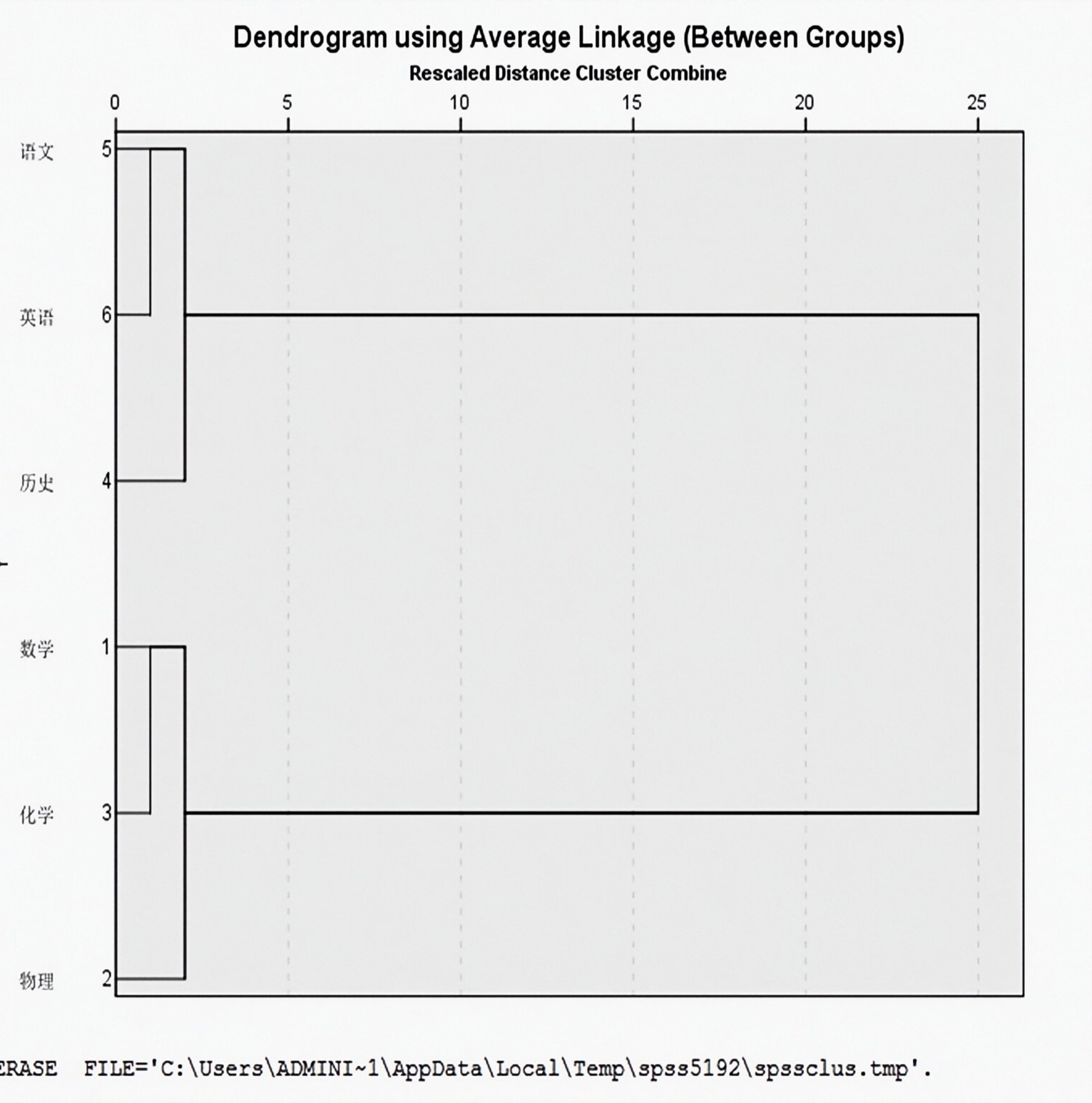
从上图聚类的结果(jiē guǒ),我们可以看出数学、物理、化学为一类。历史、英语、语文为一类。
因子分析的结果(jiē guǒ):
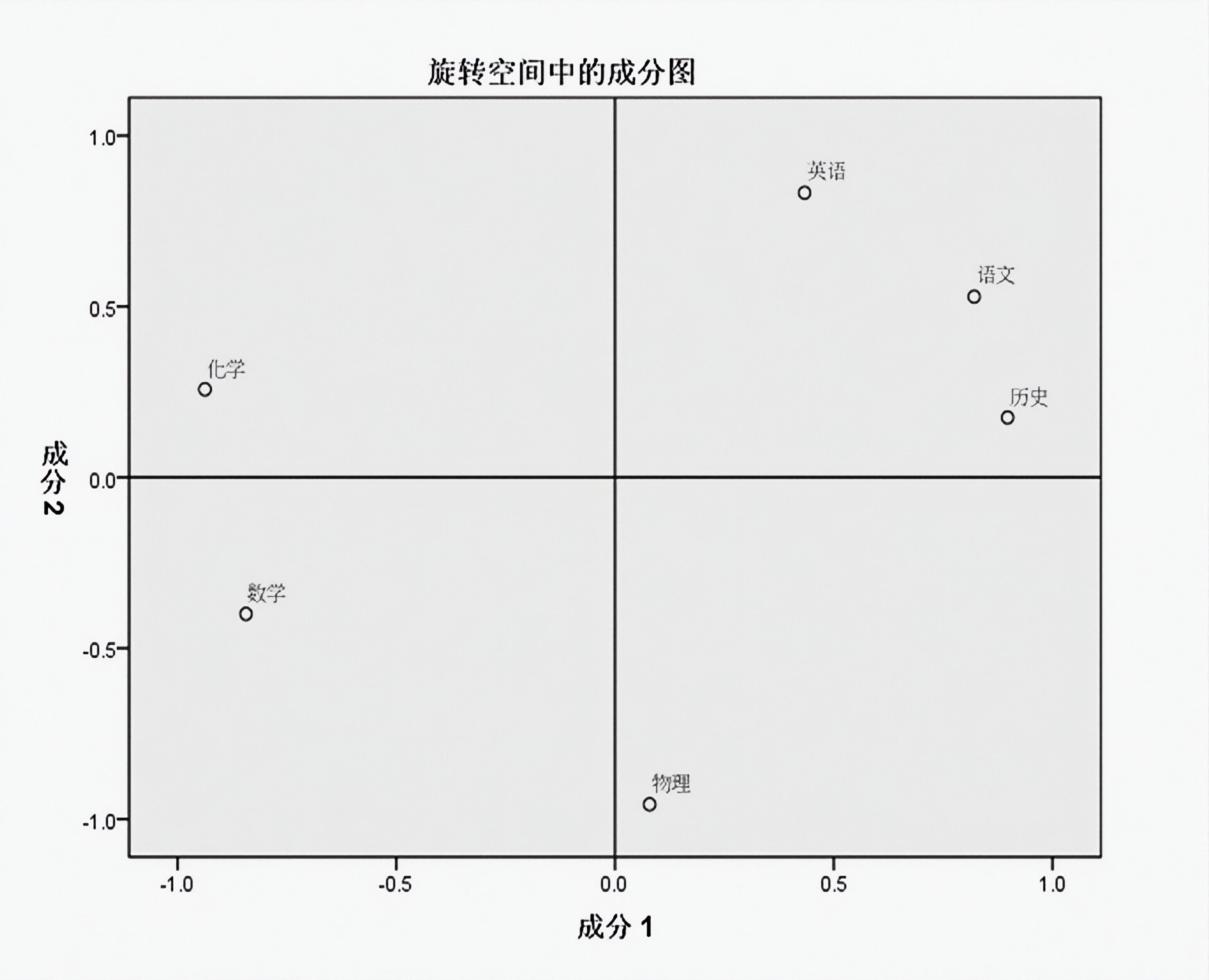
6个科目的成绩是我们观测到的外在表现,隐藏在其中的公共因子(yīnzǐ)是什么?SPSS分析(fēnxī)过程
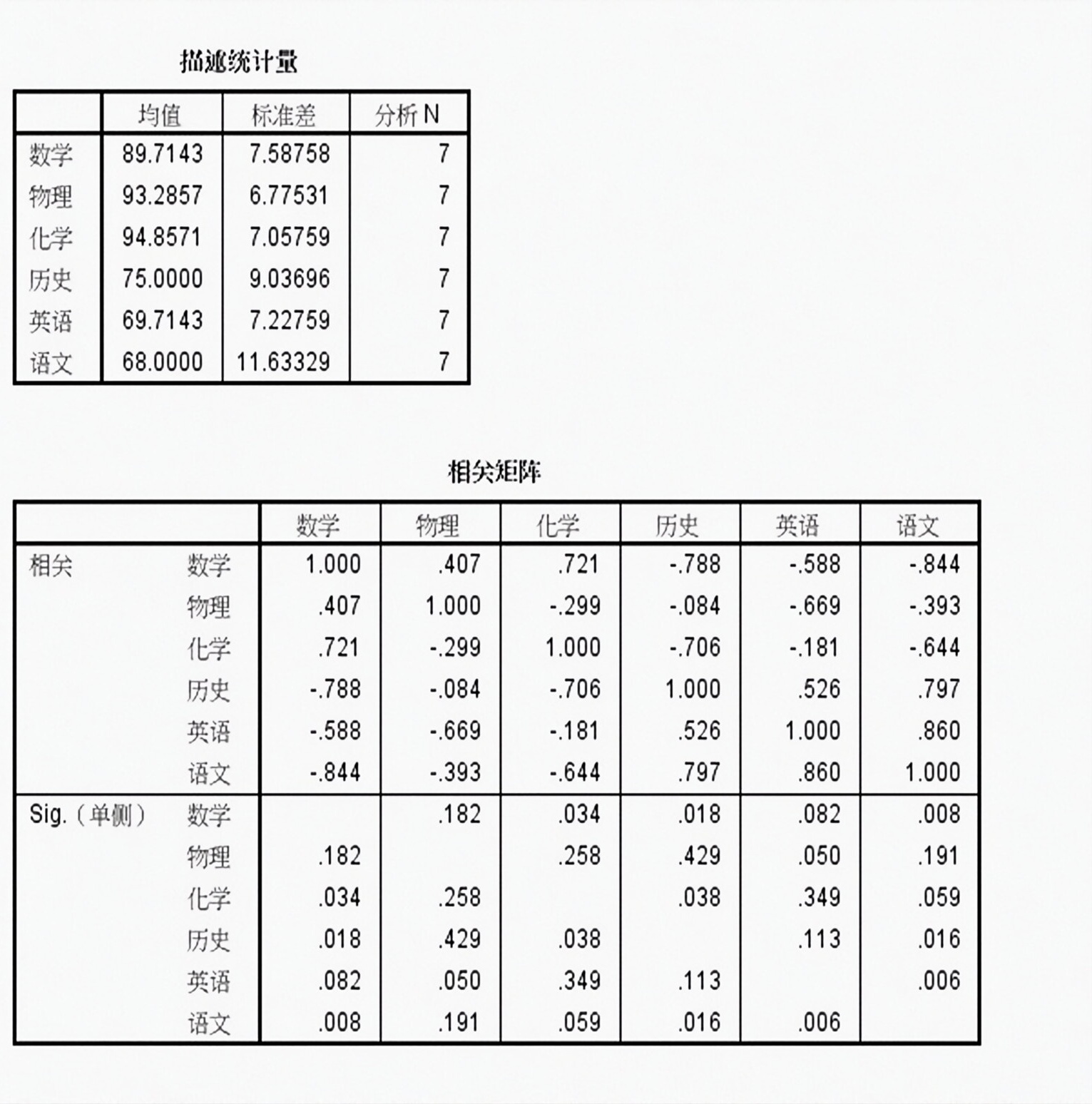
因子分析:6科目(kēmù)成绩作为6个原始变量,利用SPSS进行(jìnxíng)因子分析。
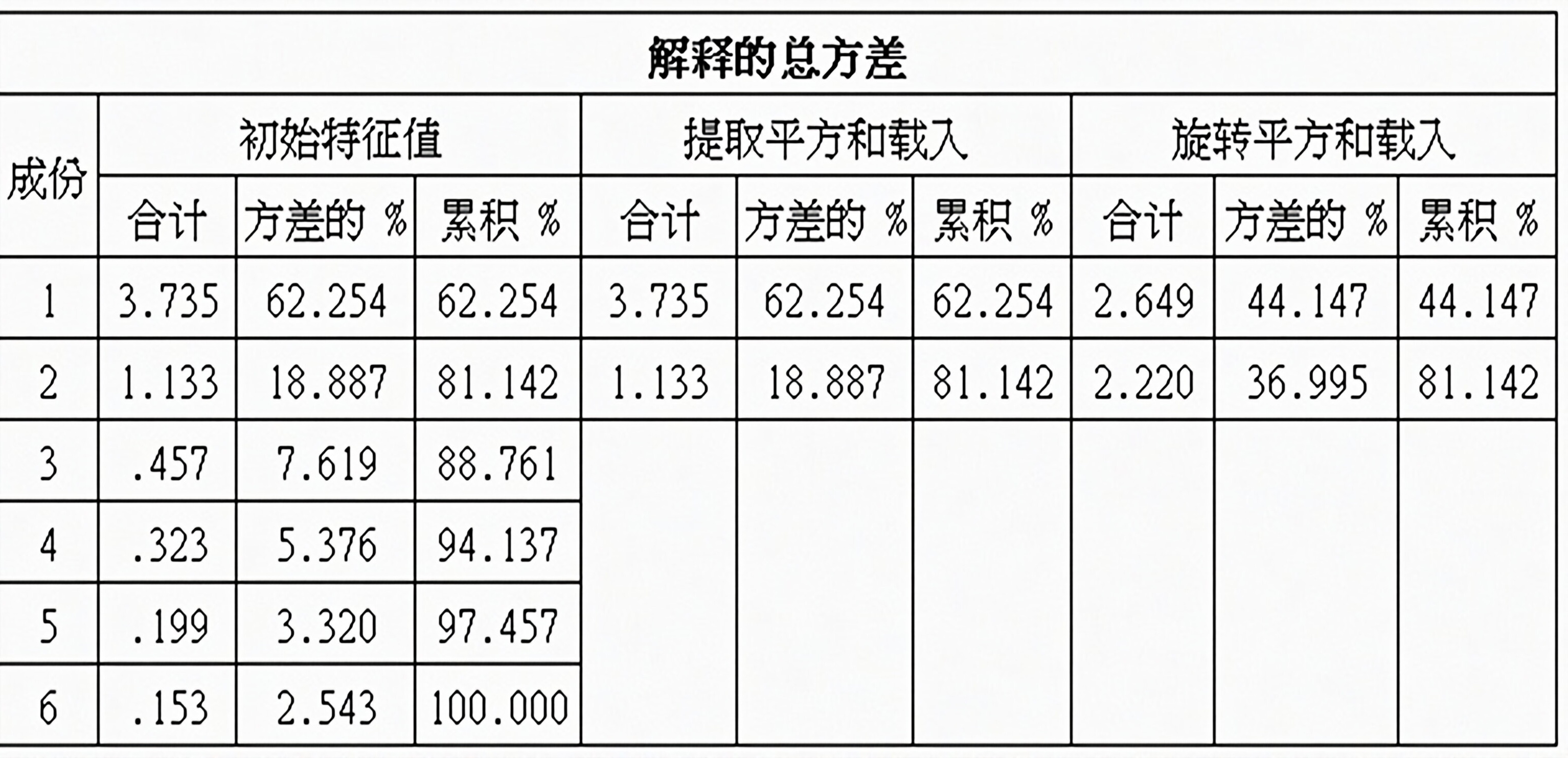
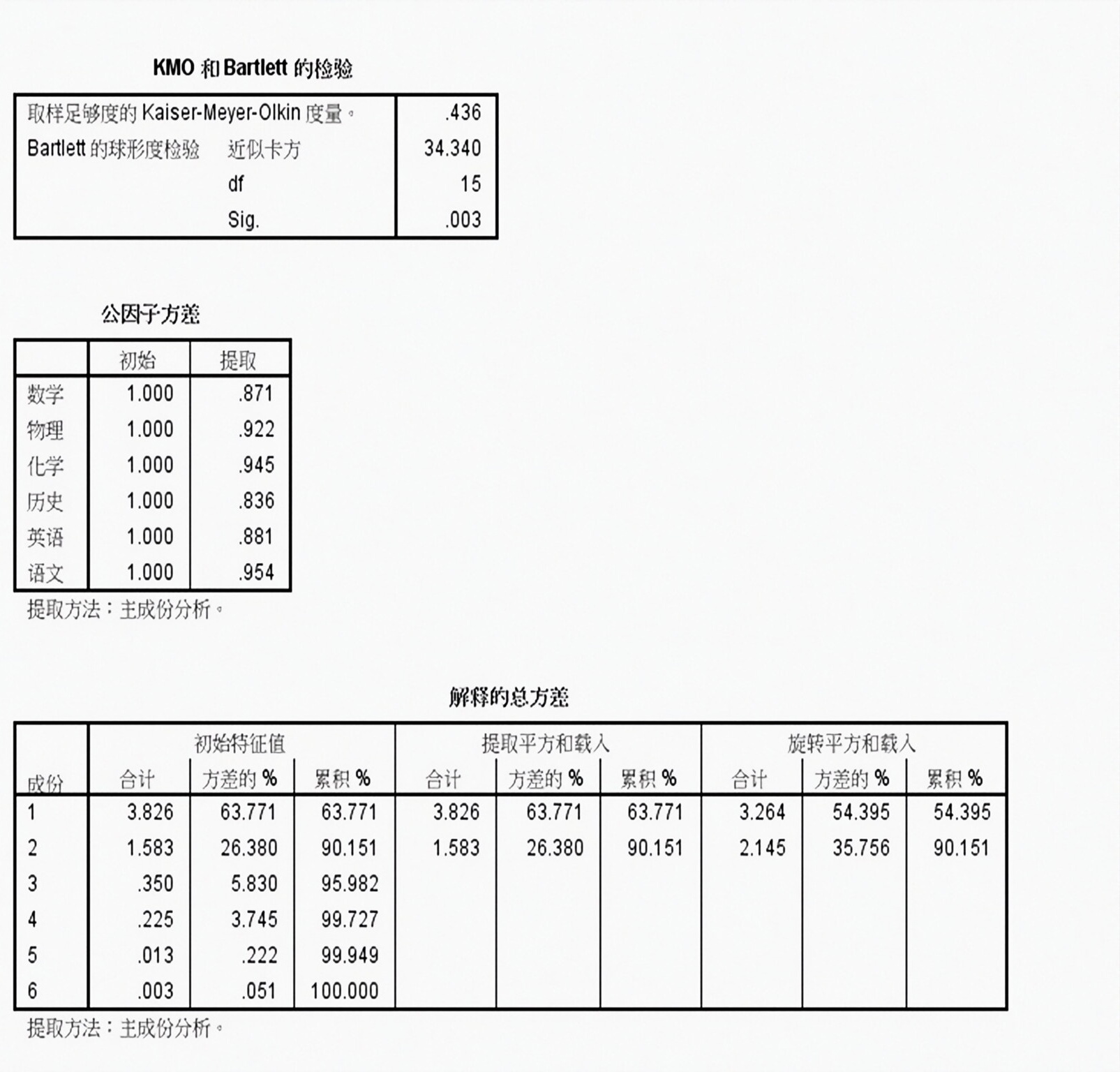
经过SPSS降维,由公因子(yīnzǐ)方差表看出,默认提取两个公因子,能够解释差异的81%,似乎暗合文科和理科。
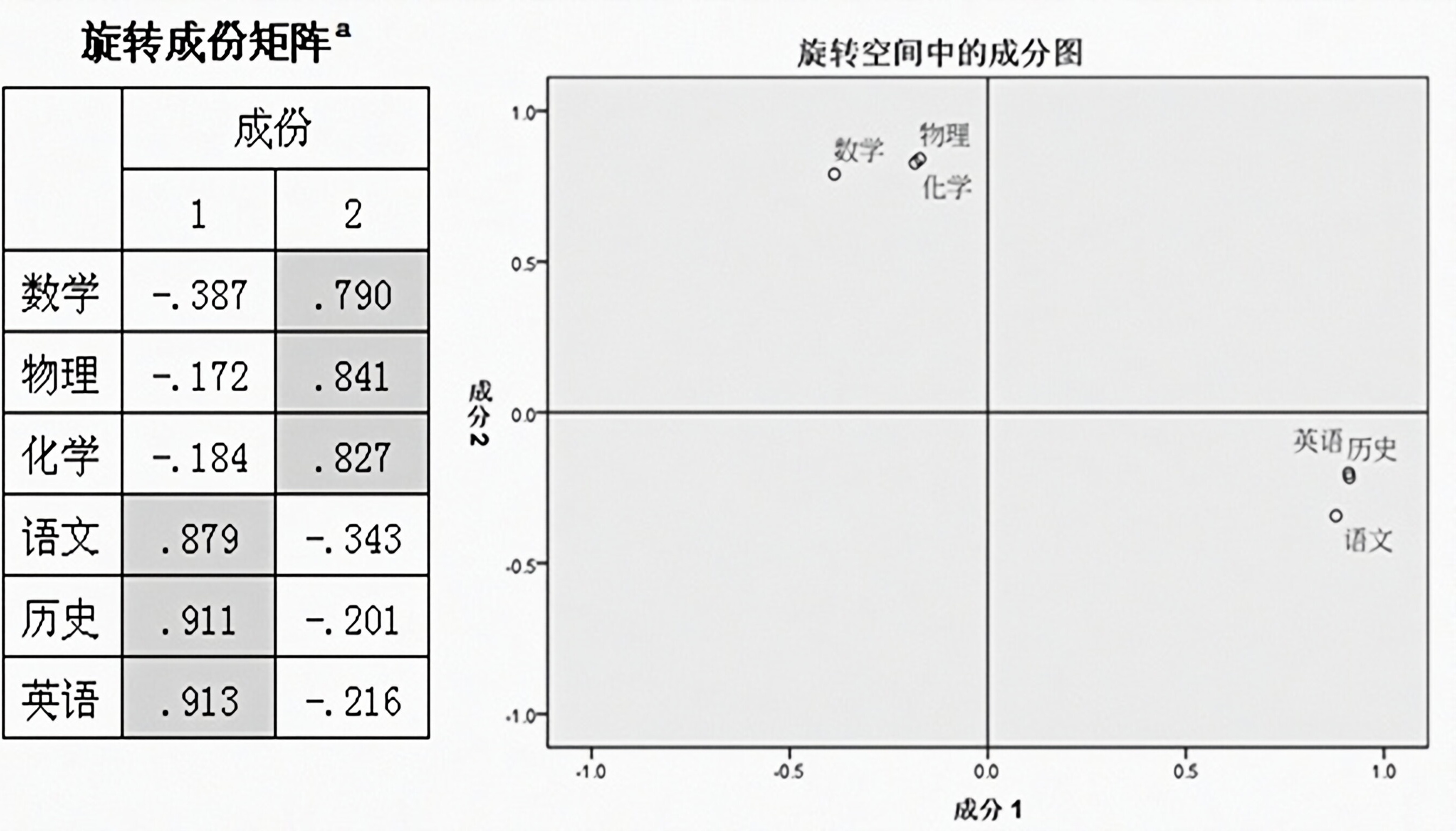
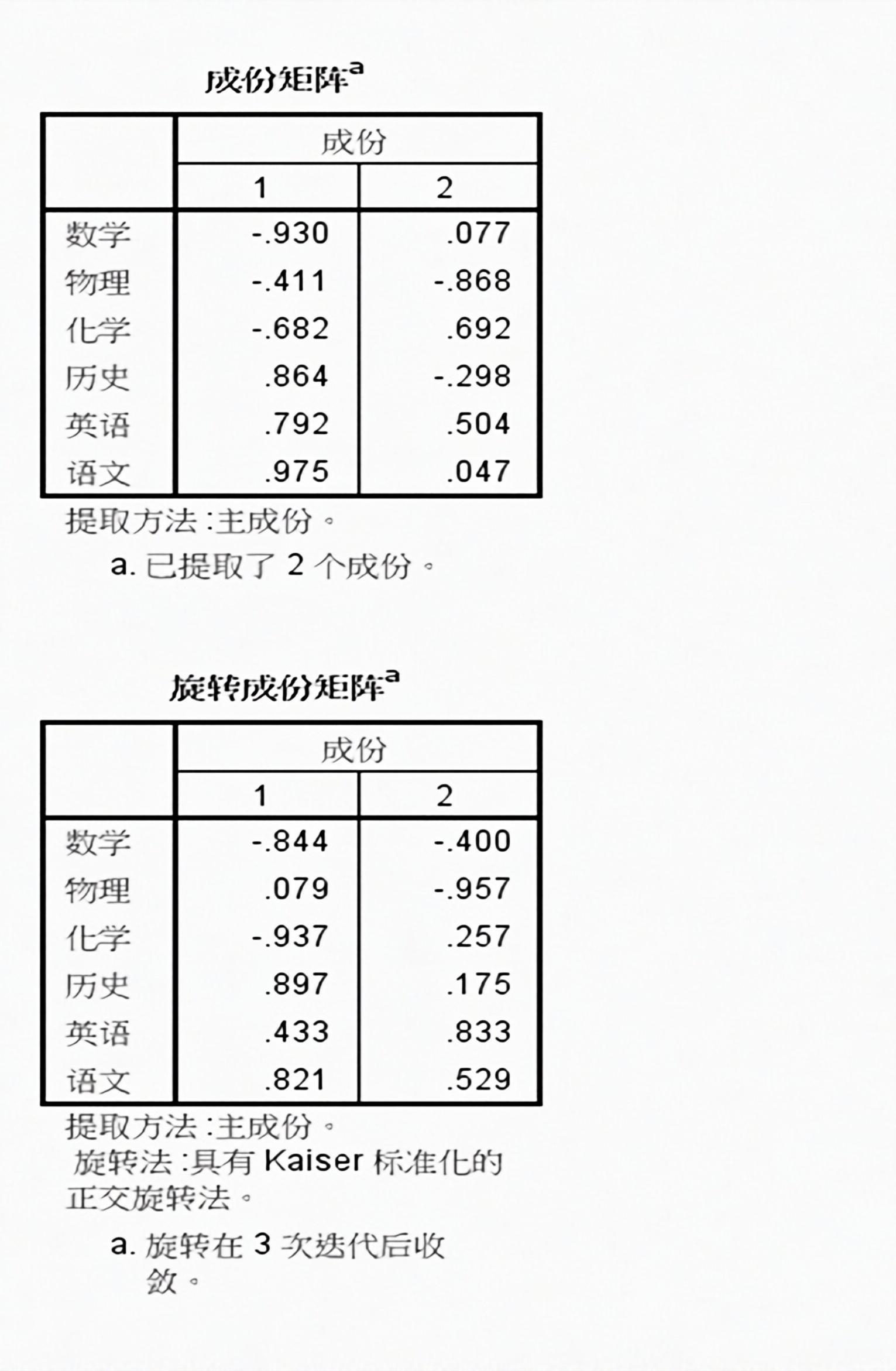
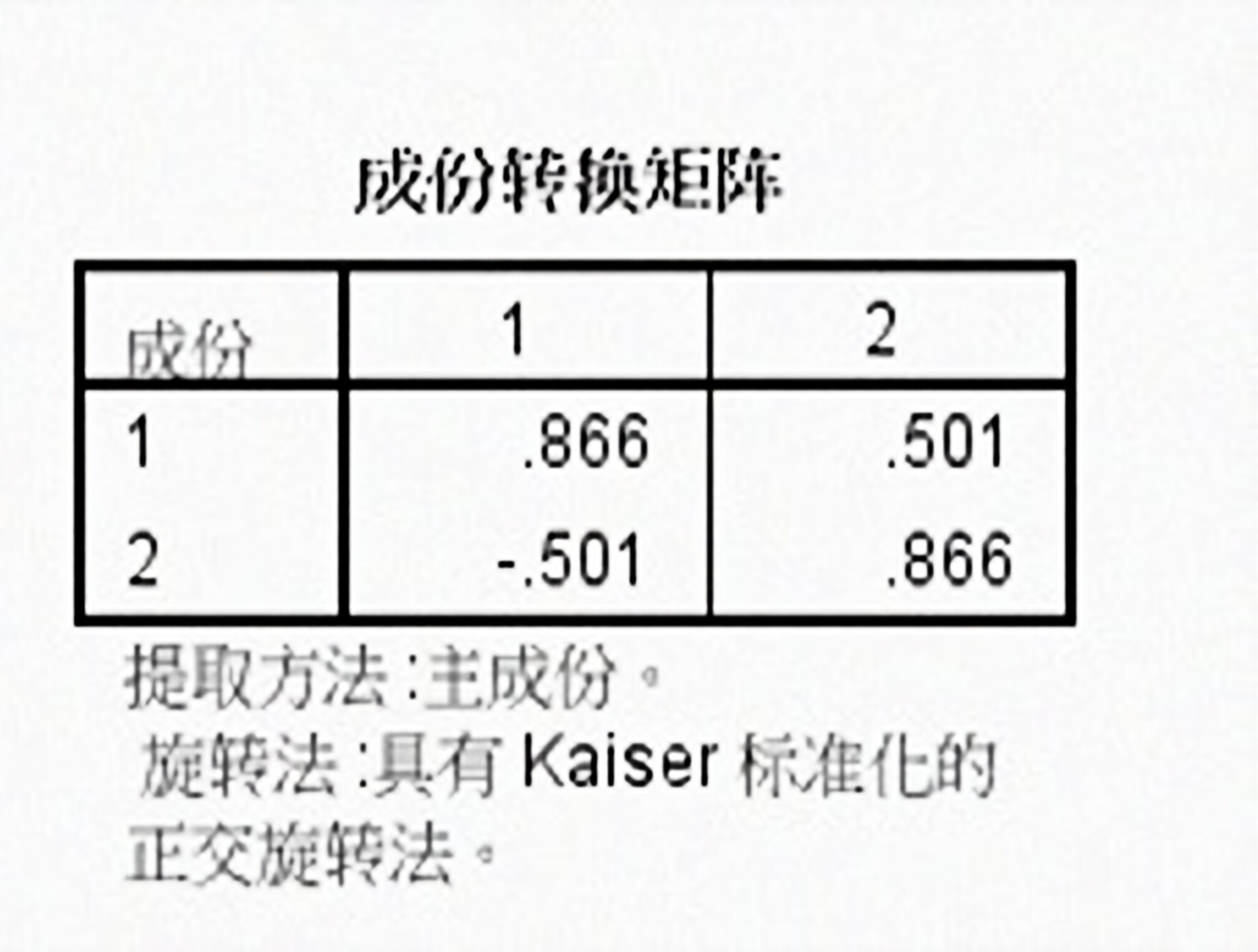
通过旋转后进行因子的命名与解释,由旋转矩阵可以看出,因子1与语文、历史、英语三科最相关,均在0.8相关度以上,因子2与数学、物理、化学相关,也基本达到0.8以上,这正好与我们经常说的文科和理科不谋而合,因此,将语文、历史、英语三科命名为文科因子;将数学、物理、化学三科命名为理科因子。
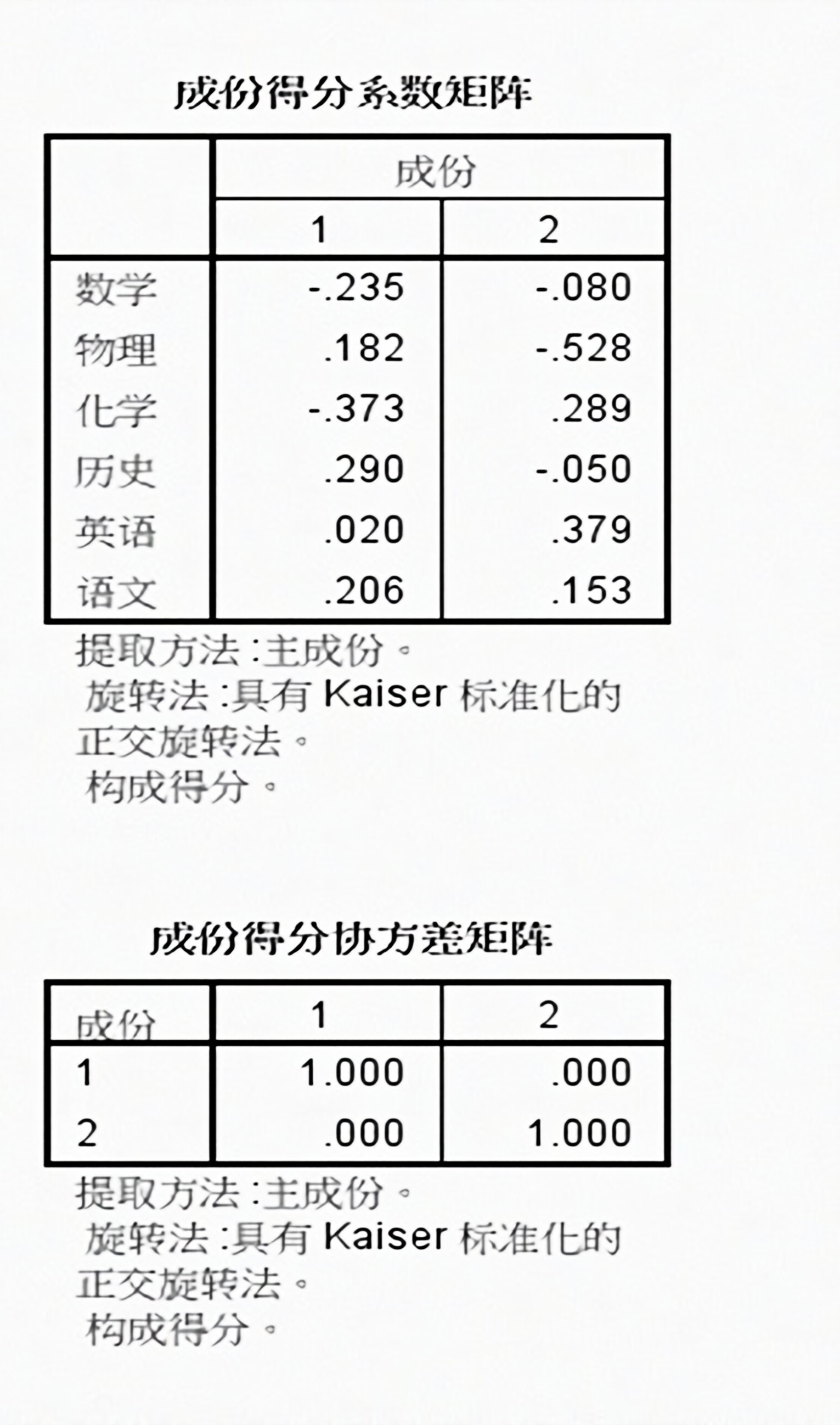
因子得分排序:综合评价
为公共因子合理命名之后,因子分析并没有结束,一般可以(kěyǐ)将因子得分作为变量,用于后续分析步骤。 本例100名学生按照文科和理科因子得分进行排序,可以(kěyǐ)用(语文+历时+英语)及(数学+物理+化学)平均值验证因子得分排序是否合理,同时,也可以观测因子得分为负值时是否影响排序。
2.。。。。。聚类分析:下表给出对该产品(chǎnpǐn)8种需求情况,根据该表,请运用聚类分析法,找出哪些地区在该产品需求上有共同特征。(题没看懂) x1 x2 x3 x4 x5 x6 x7 x8 辽宁 7.9 39.77 8.49 12.94 19.27 11.05 2.04 13.29 浙江(zhè jiānɡ) 7.68 50.37 11.35 13.3 19.25 14.59 2.75 14.87 河南(hé nán) 9.42 27.93 8.2 8.14 16.17 9.42 1.55 9.76 甘肃 9.16 27.98 9.01 9.32 15.99 9.1 1.82 11.35 青海 10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.82
题目解答
答案
答案:辽宁 x1 x6 浙江 x8河南 x5 x2 甘肃 x3 x4 青海 x7
3.。。。。。相关分析:对某地的12个乡镇的饮水氟含量及中老年人群的骨关节炎患病情况作了调查,数据如下表10-12,初步发现不同乡镇的骨关节炎的患病率高低与本地区饮水的氟含量有关。于是把氟含量视为变量X,把骨关节炎患病率视为Y,计算出Pearson积矩相关系数,得r=0.827,经检验P<0.01,据此认为骨关节炎的患病率与饮水的氟含量之间有正相关关系。(R=0.827,显著相关P=0.001)
表10-12 某地12个乡镇饮水氟含量与骨关节炎患病率
序号 | 氟含量(mg/L) | 患病率(%) |
1 | 1.2 | 7.5 |
2 | 0.35 | 8.9 |
3 | 2.5 | 9.0 |
4 | 3.18 | 12.6 |
5 | 0.75 | 8.2 |
6 | 5.92 | 15.4 |
7 | 7.97 | 20.3 |
8 | 2.06 | 10.1 |
9 | 7.05 | 30.3 |
10 | 5.3 | 24.2 |
11 | 3.52 | 7.5 |
12 | 1.5 | 10.3 |
讨论:
(1)作者以上结论是否正确?原因是什么?正确
(2)线性相关分析的适用条件是什么?如何验证其适用条件?相关分析的使用条件是符合线性关系,也就是所谓的在一条直线上。利用散点图,能够在一条直线上。
(3)应如何进行分析?本分析方法的适用条件是什么?
内容总结
(1)1.时间序列---劳动生产率
各个月的劳动生产率
(2)这是一个有趣的案例,你可以客观的观测到每一科目的成绩,但你如何可以直接看到理科、文科的情况呢
(3)相关分析:对某地的12个乡镇的饮水氟含量及中老年人群的骨关节炎患病情况作了调查,数据如下表10-12,初步发现不同乡镇的骨关节炎的患病率高低与本地区饮水的氟含量有关