题目
资料呈正态分布,过高有临床意义且不能为负,则95%单侧参考值范围为( )A.overline (X)pm 1.960SB.overline (X)pm 1.960SC.overline (X)pm 1.960SD.overline (X)pm 1.960SE . overline (X)pm 1.960S
资料呈正态分布,过高有临床意义且不能为负,则95%单侧参考值范围为( )
A.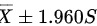
B.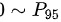
C.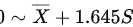
D.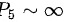
E . 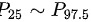
题目解答
答案
根据题目描述,资料呈正态分布,且过高有临床意义且不能为负,因此我们要找到一个单侧的95%参考值范围,即考虑数据的右侧尾部。
正态分布的右侧95%置信区间对应于:
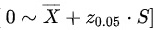
其中,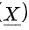 是样本均值,
是样本均值,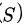 是样本标准差,而
是样本标准差,而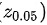 是标准正态分布的95%分位数,即
是标准正态分布的95%分位数,即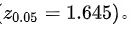
因此,正确的答案是:
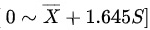
所以,答案选项为 C. 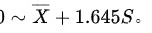
这个范围可以确保涵盖95%的正态分布数据,且符合资料过高有临床意义且不能为负的要求。
解析
考查要点:本题主要考查正态分布下单侧参考值范围的计算方法,需结合单侧置信区间的分位数选择及实际应用场景中的限制条件。
解题核心思路:
- 判断单侧方向:题目明确“过高有临床意义且不能为负”,说明需设定上限作为单侧参考范围的临界值。
- 选择分位数:单侧95%参考范围对应标准正态分布的1.645分位数(右侧尾部概率为5%)。
- 排除干扰项:正态分布的参考范围应基于均值和标准差计算,而非直接百分位数。
破题关键点:
- 单侧与双侧分位数的区别:双侧95%用1.96,单侧95%用1.645。
- 实际意义约束:数据不能为负,下限隐式为0,只需计算上限。
步骤1:确定单侧方向
题目要求“过高有临床意义”,说明需关注数据的右侧尾部,即计算上限作为单侧参考值范围。
步骤2:选择分位数
单侧95%参考范围对应标准正态分布的右侧分位数,查表得:
$Z_{0.05} = 1.645$
步骤3:构建参考范围
正态分布的单侧95%参考范围公式为:
$0 \sim \overline{X} + 1.645S$
其中:
- $\overline{X}$为样本均值
- $S$为样本标准差
步骤4:排除错误选项
- 选项A:双侧范围($\pm 1.96S$),不符合单侧要求。
- 选项B、D:未明确统计量含义,且未体现正态分布的参数计算。
- 选项E:百分位数表述不规范,正态分布应直接用均值和标准差。