常用的三类样本数据是________、________和________。⒉D-W检验的零假设[1]是(为随机项的一阶自相关系数)【B】A DW=0 B=0 CDW=1 D=1⒊DW的取值范围是【D】A-1DW0 B-1DW1C-2DW2 D 0DW4⒋当DW=4是时,说明【D】A不存在序列相关[2]B不能判断是否存在一阶自相关C存在完全的正的一阶自相关D存在完全的负的一阶自相关⒌根据20个观测值估计的结果,一元线性回归模型的DW=2.3。在样本容量[3]n=20,解释变量[4]k=1,显著性水平[5]=0.05时,查得dL=1,dL=1.41,则可以判断【A】A不存在一阶自相关B存在正的一阶自相关C存在负的一阶自相关D无法确定⒍当模型存在序列相关现象时,适宜的参数估计方法是【C】A加权最小二乘法B间接最小二乘法C广义差分法D工具变量法⒎采用一阶差分模型克服一阶线性自相关问题使用于下列哪种情况【B】A0 B1 C-1<<0 D 0<<1⒏假定某企业的生产决策是由模型dL描述的(其中dL为产量,dL为价格),又知:如果该企业在t-1期生产过剩,经济人员会削减t期的产量。由此判断上述模型存在【B】A异方差问题B序列相关问题C多重共线性问题D随机解释变量问题⒐根据一个n=30的样本估计dL后计算得DW=1.4,已知在5%得的置信度下,dL=1.35,dL=1.49,则认为原模型【B】A不存在一阶序列自相关B不能判断是否存在一阶自相关C存在完全的正的一阶自相关D存在完全的负的一阶自相关⒑对于模型dL,以表示dL与dL之间的线性相关系数(t=1,2,,n),则下面明显错误的是【B】A=0.8,DW=0.4 B=-0.8,DW=-0.4C=0,DW=2 D=1,DW=0⒒已知DW统计量的值接近于2,则样本回归模型残差的一阶自相关系数近似等于【A】A 0 B-1 C1 D 0.5⒓已知样本回归模型残差的一阶自相关系数接近于-1,则DW统计量近似等于【D】A 0 B 1 C 2 D 4⒔戈德菲尔德—夸特检验法可用于检验【A】A异方差性B多重共线性 C序列相关D设定误差⒕在给定的显著性水平之下,若DW统计量的下和上临界值分别为dL和du,则当dL<DW<du时,可认为随机误差项【D】A存在一阶正自相关 B存在一阶负相关C不存在序列相关 D存在序列相关与否不能断定
常用的三类样本数据是________、________和________。
⒉D-W检验的零假设[1]是(为随机项的一阶自相关系数)【B】
A DW=0 B=0 CDW=1 D=1
⒊DW的取值范围是【D】
A-1DW0 B-1DW1
C-2DW2 D 0DW4
⒋当DW=4是时,说明【D】
A不存在序列相关[2]B不能判断是否存在一阶自相关
C存在完全的正的一阶自相关D存在完全的负的一阶自相关
⒌根据20个观测值估计的结果,一元线性回归模型的DW=2.3。在样本容量[3]n=20,解释变量[4]k=1,显著性水平[5]=0.05时,查得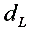 =1,
=1,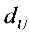 =1.41,则可以判断【A】
=1.41,则可以判断【A】
A不存在一阶自相关B存在正的一阶自相关
C存在负的一阶自相关D无法确定
⒍当模型存在序列相关现象时,适宜的参数估计方法是【C】
A加权最小二乘法B间接最小二乘法
C广义差分法D工具变量法
⒎采用一阶差分模型克服一阶线性自相关问题使用于下列哪种情况【B】
A0 B1 C-1<<0 D 0<<1
⒏假定某企业的生产决策是由模型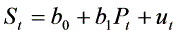 描述的(其中
描述的(其中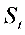 为产量,
为产量,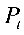 为价格),又知:如果该企业在t-1期生产过剩,经济人员会削减t期的产量。由此判断上述模型存在【B】
为价格),又知:如果该企业在t-1期生产过剩,经济人员会削减t期的产量。由此判断上述模型存在【B】
A异方差问题B序列相关问题
C多重共线性问题D随机解释变量问题
⒐根据一个n=30的样本估计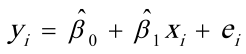 后计算得DW=1.4,已知在5%得的置信度下,
后计算得DW=1.4,已知在5%得的置信度下, =1.35,=1.49,则认为原模型【B】
=1.35,=1.49,则认为原模型【B】
A不存在一阶序列自相关B不能判断是否存在一阶自相关
C存在完全的正的一阶自相关D存在完全的负的一阶自相关
⒑对于模型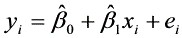 ,以表示
,以表示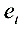 与
与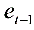 之间的线性相关系数(t=1,2,,n),则下面明显错误的是【B】
之间的线性相关系数(t=1,2,,n),则下面明显错误的是【B】
A=0.8,DW=0.4 B=-0.8,DW=-0.4
C=0,DW=2 D=1,DW=0
⒒已知DW统计量的值接近于2,则样本回归模型残差的一阶自相关系数近似等于【A】
A 0 B-1 C1 D 0.5
⒓已知样本回归模型残差的一阶自相关系数接近于-1,则DW统计量近似等于【D】
A 0 B 1 C 2 D 4
⒔戈德菲尔德—夸特检验法可用于检验【A】
A异方差性B多重共线性
C序列相关D设定误差
⒕在给定的显著性水平之下,若DW统计量的下和上临界值分别为dL和du,则当dL<DW<du时,可认为随机误差项【D】
A存在一阶正自相关 B存在一阶负相关
C不存在序列相关 D存在序列相关与否不能断定
题目解答
答案
截面数据 时间序列数据 面板数据
解析
本题考查样本数据的分类,需要掌握三种常用数据类型的定义和特点。截面数据是同一时间点不同个体的数据;时间序列数据是同一变量在不同时间点的数据;面板数据是两者的结合,即多个个体在多个时间点的数据。理解三者的区别是解题关键。
- 截面数据:指在同一时间点收集的不同个体(如不同家庭、企业)的观测数据。例如,2023年全国各省的GDP数据。
- 时间序列数据:指对同一变量在不同时间点连续观测的数据。例如,某城市2010至2023年的月度气温记录。
- 面板数据:同时包含截面数据和时间序列数据,即多个个体在多个时间点的观测数据。例如,10家企业在5年内的季度销售额数据。