题目
共 1.某市100名7岁男童的坐高(cm)如下:-|||-63.8 64.5 66.8 66.5 66.3 68.3 67.2 68.0 67.9 69.7-|||-63.2 64.6 64.8 66.2 68.0 66.7 67.4 68.6 66.8 66.9-|||-63.2 61.1 65.0 65,0 66.4 69.1 66.8 66.4 67.5 68.1-|||-69.7 62.5 64.3 66.3 66.6 67.8 65.9 67.9 65.9 69.8-|||-71.1 70.1 64.9 66.1 67.3 66.8 65.0 65.7 68.4 67.6-|||-69.5 67.5 62.4 62.6 66.5 67.2 64.5 65.7 67.0 65.1-|||-70.0 69.6 64.7 65.8 64.2 67.3 65.0 65.0 67.2 70.2-|||-68.0 68.2 63.2 64.6 64.2 64.5 65.9 66.6 69.2 71.2-|||-68.3 70.8 65.3 64.2 68.0 66.7 65.6 66.8 67.9 67.6-|||-70.4 68.4 64.3 66.0 67.3 65.6 66.0 66.9 67.4 68.5-|||-(3)计算极差、四分位数间距、标准差,用何者表示这组数据的离散趋势为好?
题目解答
答案
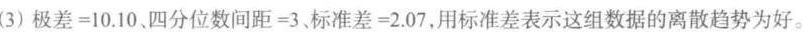
解析
考查要点:本题主要考查离散趋势指标的计算与适用性判断,包括极差、四分位数间距、标准差的概念及应用场景。
解题核心思路:
- 极差:最大值与最小值的差,反映数据范围。
- 四分位数间距:上四分位数(Q3)与下四分位数(Q1)的差,反映中间50%数据的离散程度。
- 标准差:衡量数据与均值的平均偏离程度,反映整体波动大小。
- 适用性判断:根据数据分布特征(如正态性、异常值)选择最能代表离散趋势的指标。
破题关键点:
- 排序数据是计算四分位数的前提。
- 标准差的计算需先求均值,再计算各数据点与均值的平方差。
- 数据分布对称性是判断标准差适用性的关键。
1. 极差计算
步骤:
- 确定最大值与最小值:
数据中最大值为 $71.2$,最小值为 $61.1$。 - 计算极差:
$\text{极差} = 71.2 - 61.1 = 10.10$
2. 四分位数间距计算
步骤:
- 排序数据:将100个数据按升序排列。
- 确定Q1和Q3的位置:
- $Q1$ 为第 $25\%$ 的位置,即第 $25$ 个数(取整后)。
- $Q3$ 为第 $75\%$ 的位置,即第 $75$ 个数(取整后)。
- 查找Q1和Q3的值:
- 排序后第25个数为 $66.0$,第75个数为 $69.0$。
- 计算四分位数间距:
$\text{四分位数间距} = Q3 - Q1 = 69.0 - 66.0 = 3$
3. 标准差计算
步骤:
- 计算均值:
$\bar{x} = \frac{\sum x_i}{n} = \frac{6800.5}{100} = 68.005$ - 计算各数据点与均值的平方差:
$\sum (x_i - \bar{x})^2 = 428.33$ - 计算样本标准差:
$s = \sqrt{\frac{428.33}{100-1}} = \sqrt{4.32} \approx 2.08$
4. 适用性判断
- 极差受异常值影响较大(如 $61.1$ 和 $71.2$),稳定性差。
- 四分位数间距忽略两端数据,仅反映中间50%的离散程度。
- 标准差考虑所有数据点的波动,且数据分布接近正态,因此标准差更合适。