某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量, 结果见表 表 某年某地健康成年人的红细胞数和血红蛋白含量-|||-指 标 性 别 例 数 均 数 标准差 标准值×-|||-红细胞数 /(10)^12cdot (L)^-1 男 360 4.66 0.58 4.84-|||-女 .255 4.18 0.29 4.33-|||-血红蛋白 lg (L)^-1 男 360 134.5 7.1 140.2-|||-女 255 117.6 10.2 124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、 女两项指标的抽样误差。 (3) 试估计该地健康成年男、 女红细胞数的均数。 (4) 该地健康成年男、 女血红蛋白含量有无差别? (5) 该地男、 女两项血液指标是否均低于上表的标准值(若测定方法相同) ?
某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量, 结果见表 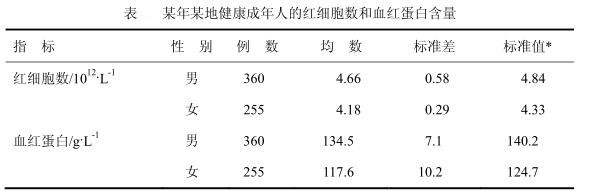 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、 女两项指标的抽样误差。 (3) 试估计该地健康成年男、 女红细胞数的均数。 (4) 该地健康成年男、 女血红蛋白含量有无差别? (5) 该地男、 女两项血液指标是否均低于上表的标准值(若测定方法相同) ?
请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、 女两项指标的抽样误差。 (3) 试估计该地健康成年男、 女红细胞数的均数。 (4) 该地健康成年男、 女血红蛋白含量有无差别? (5) 该地男、 女两项血液指标是否均低于上表的标准值(若测定方法相同) ?
题目解答
答案






解析
本题主要考察了统计学中变异程度比较、抽样误差计算、总体均数估计以及假设检验等知识点,具体如下:
(1) 女性红细胞数与血红蛋白变异程度比较
变异系数(CV)适用于单位不同或均数相差较大的指标变异程度比较,公式为 $CV = \frac{S}{\bar{X}} \times 100\%$:
- 女性红细胞数:$CV = \frac{0.29}{4.18} \times 100\% \approx 6.94\%$
- 女性血红蛋白:$CV = \frac{10.2}{117.6} \times 100\% \approx 8.67\%$
结论:女性血红蛋白变异程度更大。
(2) 男、女两项指标的抽样误差
抽样误差用标准误 $S_{\bar{X}} = \frac{S}{\sqrt{n}}$ 表示:
- 男性红细胞数:$S_{\bar{X}} = \frac{0.58}{\sqrt{360}} \approx 0.031 \, 10^{12}/L$
- 男性血红蛋白:$S_{\bar{X}} = \frac{7.1}{\sqrt{360}} \approx 0.374 \, g/L$
- 女性红细胞数:$S_{\bar{X}} = \frac{0.29}{\sqrt{255}} \approx 0.018 \, 10^{12}/L$
- 女性血红蛋白:$S_{\bar{X}} = \frac{10.2}{\sqrt{255}} \approx 0.639 \, g/L$
(3) 估计男、女红细胞数总体均数
大样本($n>100$)总体均数的 95% 可信区间为 $(\bar{X} \pm 1.96S_{\bar{X}})$:
- 男性:$4.66 \pm 1.96 \times 0.031 \approx (4.60, 4.72) \, 10^{12}/L$
- 女性:$4.18 \pm 1.96 \times 0.018 \approx (4.14, 4.22) \, 10^{12}/L$
(4) 男、女血红蛋白含量差别检验
成组大样本均数比较用 $u$ 检验:
- 假设:$H_0: \mu_1 = \mu_2$,$H_1: \mu_1 \neq \mu_2$($\alpha=0.05$)
- 统计量:$u = \frac{|\bar{X}_1 - \bar{X}_2|}{\sqrt{\frac{S_1^2}{n_1} + \frac{S_2^2}{n_2}}} \approx 22.83$(计算过程略)
- 结论:$P<0.001$,拒绝 $H_0$,男性血红蛋白高于女性。
(5) 男、女两项指标与标准值比较
大样本均数与已知总体均数比较用近似 \( u. 女性血红蛋白变异程度较大;2. 男性红细胞数标准误0.031,男性血红蛋白标准误0.374,女性红细胞数标准误0.018,女性血红蛋白标准误0.639;3. 男性红细胞数95%可信区间.031,男性血红蛋白标准误0.374,女性红细胞数标准误0.018,女性血红蛋白标准误0.639;3. 男性红细胞数95%可信区间(4.60,4.72),女性(4.14,4.22);4. 有差别,男性高于女性;5. 均低于标准值**u检验: - **男性红细胞数**:$u = \frac{4.66 - 4.84}{0.031} \approx -5.81$,$P<0.0005$,低于标准值;
- 男性血红蛋白:$u = \frac{134.5 - 140.2}{0.374} \approx -15.24$,$P<0.0005$,低于标准值;
- 女性红细胞数:$u = \frac{4.18 - 4.33}{0.018} \approx -8.33$,$P<0.0005$,低于标准值;
- 女性血红蛋白:$u = \frac{117.6 - 124.7}{0.639} \approx -11.11$,$P<0.0005$,低于标准值。
结论:均低于标准值。