题目
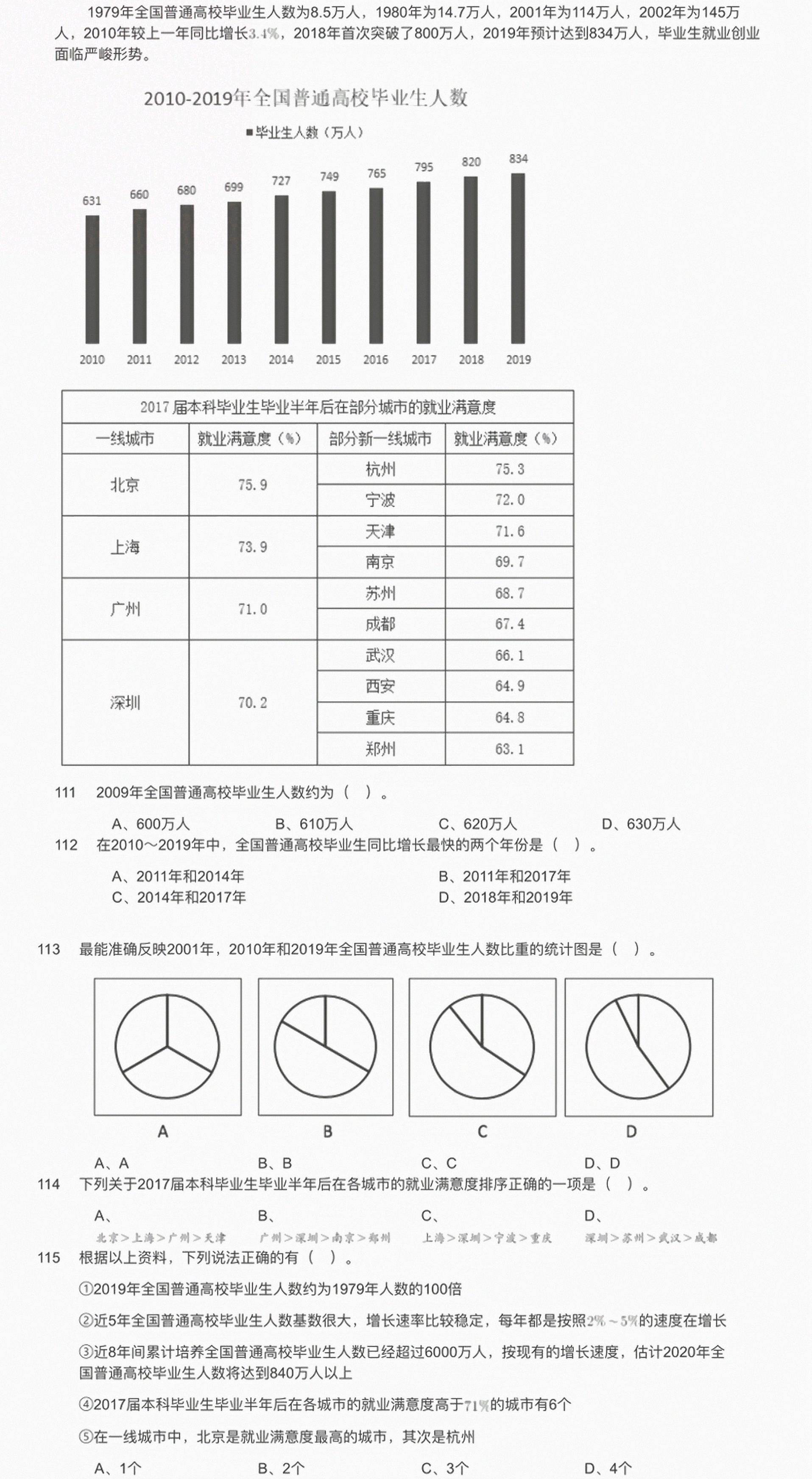
631 660 680 699 727 749 765 795 820 834-|||-2010 2011 2012 2013 2014 2015 2016 2017 2018 2019-|||-2017届本科毕业生毕业半年后在部分城市的就业满意度-|||-一线城市 就业满意度(%) 部分新一线城市 就业满意度(%)-|||-杭州 75.3-|||-北京 75.9-|||-宁波 72.0-|||-天津 71.6-|||-上海 73.9-|||-南京 69.7-|||-苏州 68.7-|||-广州 71.0-|||-成都 67.4-|||-武汉 66.1-|||-西安 64.9-|||-深圳 70.2-|||-重庆 64.8-|||-郑州 63.1-|||-111 2009年全国普通高校毕业生人数约为( )。-|||-A、600万人 B、610万人 C、620万人 D、630万人-|||-112 在 sim 2019 年中,全国普通高校毕业生同比增长最快的两个年份是 () 。-|||-A、2011年和2014年 B、2011年和2017年-|||-C、2014年和2017年 D、2018年和2019年-|||-113 最能准确反映200年,2010年和2019年全国普通高校毕业生人数比重的统计图是( )。-|||-A B C D-|||-A、A B、B C、C D、D-|||-114 下列关于2017届本科毕业生毕业半年后在各城市的就业满意度排序正确的一项是( )。-|||-A、 B、 C、 D、-|||-北京>上海>广州>天津 广州>深圳>南京>郑州 上海>深圳>宁波>重庆 深圳>苏州>武汉>成都-|||-115 根据以上资料,下列说法正确的有( )。-|||-①2019年全国普通高校毕业生人数约为1979年人数的100倍-|||-②近5年全国普通高校毕业生人数基数很大,增长速率比较稳定,每年都是按照 % sim 5% 的速度在增长-|||-③近8年间累计培养全国普通高校毕业生人数已经超过6000万人,按现有的增长速度,估计2020年全-|||-国普通高校毕业生人数将达到840万人以上-|||-④2017届本科毕业生毕业半年后在各城市的就业满意度高于71%的城市有6个-|||-⑤在一线城市中,北京是就业满意度最高的城市,其次是杭州-|||-A、1个 B、2个 C、3个 D、4个
题目解答
答案
