题目
(2-20)假定有如下的回归结果:_(t)=2.6911-0.4795(X)_(t),,其中,Y表示美国的咖啡的消费量(每天每人消费的杯数),X表示咖啡的零售价格(美元/杯),t表示时间。要求:(1)这是一个时间序列回归还是横截面序列回归?做出回归线;(2)如何解释截距的意义,它有经济含义吗?如何解释斜率?(3)能否求出真实的总体回归函数?(4)根据需求的价格弹性定义:弹性=斜率×(X/Y),依据上述回归结果,你能求出对咖啡需求的价格弹性吗?如果不能,计算此弹性还需要其他什么信息?
(2-20)假定有如下的回归结果: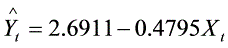 ,其中,Y表示美国的咖啡的消费量(每天每人消费的杯数),X表示咖啡的零售价格(美元/杯),t表示时间。
,其中,Y表示美国的咖啡的消费量(每天每人消费的杯数),X表示咖啡的零售价格(美元/杯),t表示时间。
要求:(1)这是一个时间序列回归还是横截面序列回归?做出回归线;
(2)如何解释截距的意义,它有经济含义吗?如何解释斜率?
(3)能否求出真实的总体回归函数?
(4)根据需求的价格弹性定义:弹性=斜率×(X/Y),依据上述回归结果,你能求出对咖啡需求的价格弹性吗?如果不能,计算此弹性还需要其他什么信息?
题目解答
答案
解:(1)这是一个横截面序列回归。
(2)截距2.6911表示咖啡零售价为每磅0美元时,每天每人平均消费量为2.6911杯,这个数字没有经济意义;斜率-0.4795表示咖啡零售价与消费量负相关,价格上升1美元/磅,则平均每天每人消费量减少0.4795杯;
(3)不能;
(4)不能;在同一条需求曲线上不同点的价格弹性不同,若要求出,须给出具体的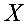 值及与之对应的
值及与之对应的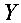 值。
值。
解析
步骤 1:判断回归类型
根据题目中给出的变量和回归方程,可以看出Y和X是两个不同的变量,且t表示时间,因此这是一个时间序列回归。
步骤 2:解释截距和斜率
截距2.6911表示当咖啡零售价格为0美元/杯时,每天每人平均消费量为2.6911杯,这个数字没有经济意义;斜率-0.4795表示咖啡零售价格与消费量负相关,价格上升1美元/杯,则平均每天每人消费量减少0.4795杯。
步骤 3:求出真实的总体回归函数
由于回归分析是基于样本数据进行的,因此不能求出真实的总体回归函数。
步骤 4:计算需求的价格弹性
根据需求的价格弹性定义:弹性=斜率×(X/Y),依据上述回归结果,不能求出对咖啡需求的价格弹性,因为需要知道具体的X和Y值才能计算出弹性。
根据题目中给出的变量和回归方程,可以看出Y和X是两个不同的变量,且t表示时间,因此这是一个时间序列回归。
步骤 2:解释截距和斜率
截距2.6911表示当咖啡零售价格为0美元/杯时,每天每人平均消费量为2.6911杯,这个数字没有经济意义;斜率-0.4795表示咖啡零售价格与消费量负相关,价格上升1美元/杯,则平均每天每人消费量减少0.4795杯。
步骤 3:求出真实的总体回归函数
由于回归分析是基于样本数据进行的,因此不能求出真实的总体回归函数。
步骤 4:计算需求的价格弹性
根据需求的价格弹性定义:弹性=斜率×(X/Y),依据上述回归结果,不能求出对咖啡需求的价格弹性,因为需要知道具体的X和Y值才能计算出弹性。