题目
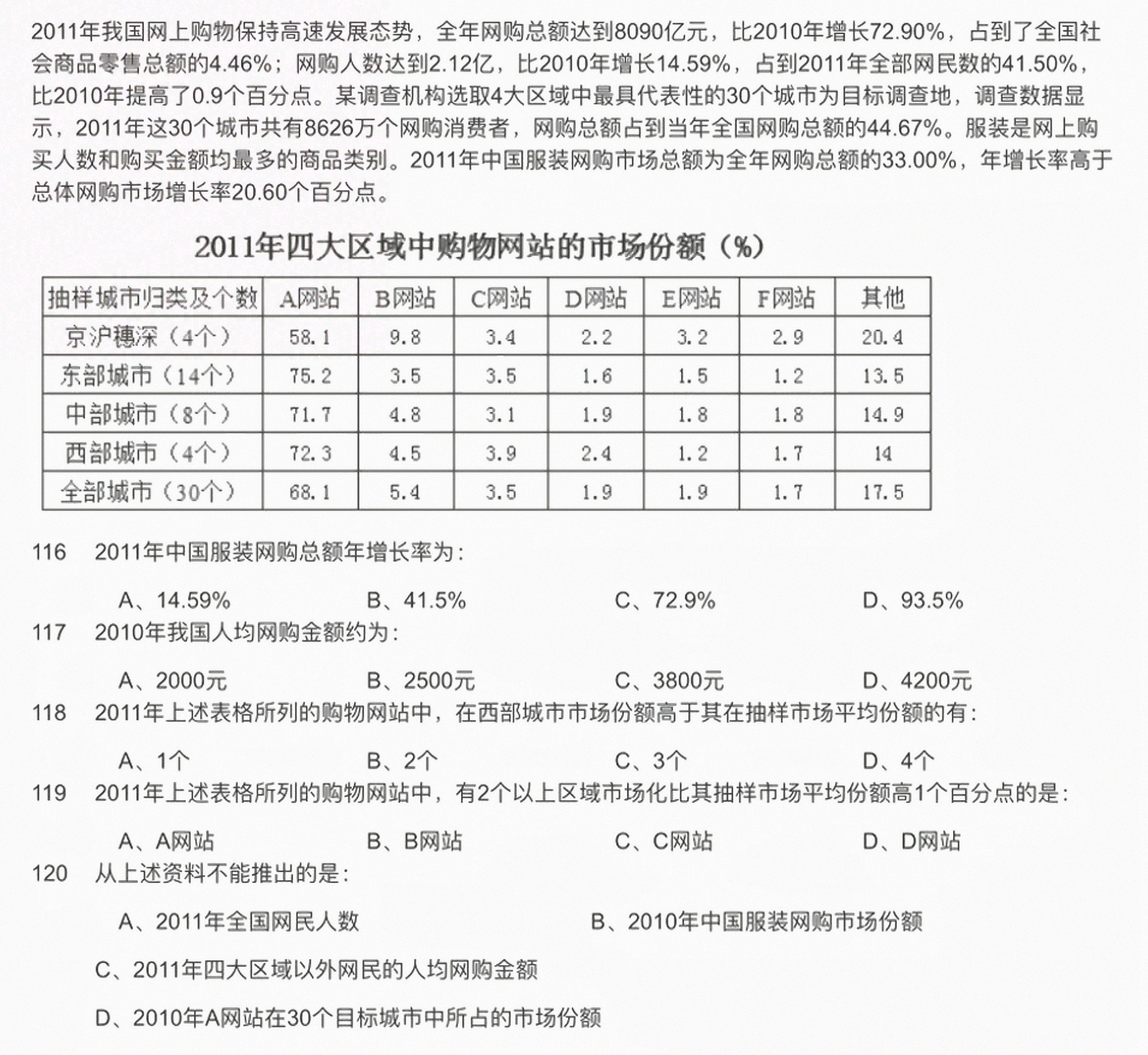
2011年我国网上购物保持高速发展态势,全年网购总额达到8090亿元,比2010年增长72.90 %,占到了全国社-|||-会商品零售总额的4.46%;网购人数达到2.12亿,比2010年增长14.59 %,占到2011年全部网民数的41.50%,-|||-比2010年提高了0.9个百分点。某调查机构选取4大区域中最具代表性的30个城市为目标调查地,调查数据显-|||-示,2011年这30个城市共有8626万个网购消费者,网购总额占到当年全国网购总额的44.67%。服装是网上购-|||-买人数和购买金额均最多的商品类别。2011年中国服装网购市场总额为全年网购总额的33.00%,年增长率高于-|||-总体网购市场增长率20.60个百分点。-|||-2011年四大区域中购物网站的市场份额(%)-|||-抽样城市归类及个数 A.网站 B网站 C网站 D网站 E网站 F网站 其他-|||-京沪藕深(4个) 58.1 9.8 3.4 2.2 3.2 2.9 20.4-|||-东部城市(14个) 75.2 3.5 3.5 1.6 1.5 1.2 13.5-|||-中部城市(8个) 71.7 4.8 3.1 1.9 1.8 1.8 14.9-|||-西部城市(4个) 72.3 4.5 3.9 2.4 1.2 1.7 14-|||-全部城市(30个) 68.1 5.4 3.5 1.9 1.9 1.7 17.5-|||-116 2011年中国服装网购总额年增长率为:-|||-A、14.59% B、41.5% C、72.9% D、93.5%-|||-117 2010年我国人均网购金额约为:-|||-A、2000元 B、2500元 C、3800元 D、4200元-|||-118 2011年上述表格所列的购物网站中,在西部城市市场份额高于其在抽样市场平均份额的有:-|||-A、1个 B、2个 C、3个 D、4个-|||-119 2011年上述表格所列的购物网站中,有2个以上区域市场化比其抽样市场平均份额高1个百分点的是:-|||-A、A网站 B、B网站 C、C网站 D、D网站-|||-120 从上述资料不能推出的是:-|||-A、2011年全国网民人数 B、2010年中国服装网购市场份额-|||-C、2011年四大区域以外网民的人均网购金额-|||-D、2010年A网站在30个目标城市中所占的市场份额
题目解答
答案
