题目
设总体的密度函数为,其中是未知函数,则的极大似然估计量为
设总体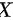 的密度函数为
的密度函数为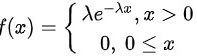 ,其中
,其中 是未知函数,则的极大似然估计量为
是未知函数,则的极大似然估计量为
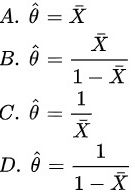
题目解答
答案
选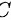 .
.
设总体的概率函数为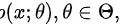 其中
其中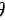 是一个未知参数或几个未知参数组成的向量,
是一个未知参数或几个未知参数组成的向量,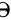 是参数空间,
是参数空间, 是来自该总体的样本,将样本的联合概率函数看成的函数,用
是来自该总体的样本,将样本的联合概率函数看成的函数,用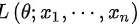 表示,简记为
表示,简记为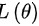 ,
,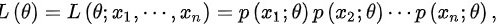 称为样本的似然函数。如果某统计量
称为样本的似然函数。如果某统计量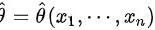 满足
满足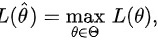 则称
则称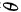 是的最大似然估计,简记为MLE。
是的最大似然估计,简记为MLE。
最大似然估计法的关键在于写出似然函数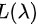 ,总体
,总体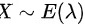 的概率密度函数为
的概率密度函数为
则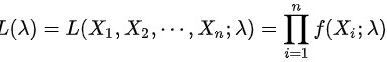
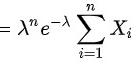
取对数,得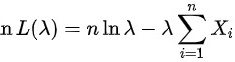
令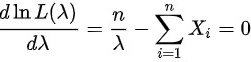
解得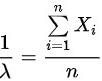
故的极大似然估计量为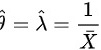 ,即选。
,即选。
解析
步骤 1:写出似然函数
给定总体的密度函数为$f(x)=\left \{ \begin{matrix} \lambda {e}^{-\lambda x},x\gt 0\\ 0,0\leqslant x\end{matrix} \right.$,其中$\lambda$是未知参数。设${X}_{1},{X}_{2},\cdots ,{X}_{n}$是来自该总体的样本,则样本的似然函数为:
$L(\lambda )=L({X}_{1},{X}_{2},\cdots ,{X}_{n},\lambda )=\prod _{i=1}^{n}f({X}_{i},\lambda )=\prod _{i=1}^{n}\lambda {e}^{-\lambda {X}_{i}}$
步骤 2:取对数似然函数
取对数似然函数,得到:
$\ln L(\lambda )=\ln (\prod _{i=1}^{n}\lambda {e}^{-\lambda {X}_{i}})=\sum _{i=1}^{n}\ln (\lambda {e}^{-\lambda {X}_{i}})=n\ln \lambda -\lambda \sum _{i=1}^{n}{X}_{i}$
步骤 3:求导并求极大似然估计量
对$\ln L(\lambda )$关于$\lambda$求导,得到:
$\dfrac {d\ln L(\lambda )}{d\lambda }=\dfrac {n}{\lambda }-\sum _{i=1}^{n}{X}_{i}$
令导数等于0,得到:
$\dfrac {n}{\lambda }-\sum _{i=1}^{n}{X}_{i}=0$
解得:
$\lambda =\dfrac {n}{\sum _{i=1}^{n}{X}_{i}}=\dfrac {1}{\overline {X}}$
给定总体的密度函数为$f(x)=\left \{ \begin{matrix} \lambda {e}^{-\lambda x},x\gt 0\\ 0,0\leqslant x\end{matrix} \right.$,其中$\lambda$是未知参数。设${X}_{1},{X}_{2},\cdots ,{X}_{n}$是来自该总体的样本,则样本的似然函数为:
$L(\lambda )=L({X}_{1},{X}_{2},\cdots ,{X}_{n},\lambda )=\prod _{i=1}^{n}f({X}_{i},\lambda )=\prod _{i=1}^{n}\lambda {e}^{-\lambda {X}_{i}}$
步骤 2:取对数似然函数
取对数似然函数,得到:
$\ln L(\lambda )=\ln (\prod _{i=1}^{n}\lambda {e}^{-\lambda {X}_{i}})=\sum _{i=1}^{n}\ln (\lambda {e}^{-\lambda {X}_{i}})=n\ln \lambda -\lambda \sum _{i=1}^{n}{X}_{i}$
步骤 3:求导并求极大似然估计量
对$\ln L(\lambda )$关于$\lambda$求导,得到:
$\dfrac {d\ln L(\lambda )}{d\lambda }=\dfrac {n}{\lambda }-\sum _{i=1}^{n}{X}_{i}$
令导数等于0,得到:
$\dfrac {n}{\lambda }-\sum _{i=1}^{n}{X}_{i}=0$
解得:
$\lambda =\dfrac {n}{\sum _{i=1}^{n}{X}_{i}}=\dfrac {1}{\overline {X}}$