题目
2.(2018,Ⅲ)设X1,X2,···, _(n)(ngeqslant 2) 为来自总体 (mu ,(sigma )^2)(sigma gt 0) 的-|||-简单随机样本,令 overline (X)=dfrac (1)(n)sum _(i=1)^n(X)_(1) =sqrt (dfrac {1)(n-1)sum _(i=1)^n(({X)_(i)-overline (X))}^2} ,-|||-'=sqrt (dfrac {1)(n)sum _(i=1)^n(({X)_(i)-mu )}^2} ,则( ).-|||-(A) dfrac (sqrt {n)(overline (X)-mu )}(S)sim t(n) (B) dfrac (sqrt {n)(overline (X)-mu )}(S)sim t(n-1)-|||-(C) dfrac (sqrt {n)(overline (X)-mu )}(S)sim t(n) (D) dfrac (sqrt {n)(overline (X)-mu )}(S)sim t(n-1)
题目解答
答案
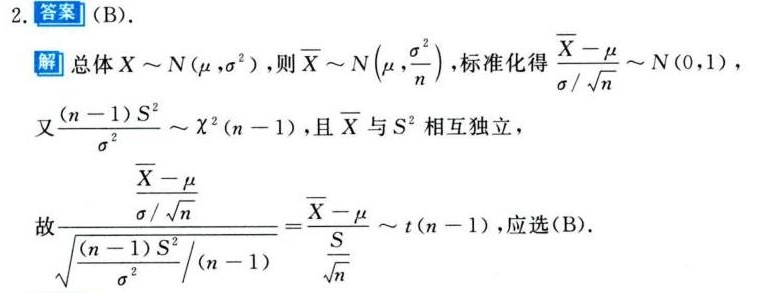
解析
考查要点:本题主要考查t分布的构造条件及样本均值与样本方差的独立性。
解题核心思路:
- 标准化样本均值:由正态总体性质,样本均值$\overline{X}$服从正态分布,标准化后服从标准正态分布。
- 样本方差的卡方分布:$(n-1)S^2/\sigma^2$服从自由度为$n-1$的卡方分布。
- 独立性:样本均值$\overline{X}$与样本方差$S^2$相互独立。
- 构造t分布:将标准化后的正态变量与卡方变量组合,得到自由度为$n-1$的t分布。
破题关键点:
- 分子标准化:$\sqrt{n}(\overline{X}-\mu)/\sigma \sim N(0,1)$。
- 分母构造:$S$是样本标准差,其平方与卡方分布相关,需体现自由度$n-1$。
- 自由度匹配:t分布的自由度由分母的卡方分布自由度决定,即$n-1$。
步骤1:标准化样本均值
由正态总体性质,$\overline{X} \sim N\left(\mu, \dfrac{\sigma^2}{n}\right)$,标准化得:
$\frac{\sqrt{n}(\overline{X}-\mu)}{\sigma} \sim N(0,1).$
步骤2:分析样本方差的分布
样本方差$S^2$的定义为:
$S^2 = \frac{1}{n-1}\sum_{i=1}^{n}(X_i - \overline{X})^2,$
因此:
$\frac{(n-1)S^2}{\sigma^2} \sim \chi^2(n-1).$
步骤3:构造t分布
将标准化后的正态变量与卡方变量组合:
$\frac{\sqrt{n}(\overline{X}-\mu)}{S} = \frac{\frac{\sqrt{n}(\overline{X}-\mu)}{\sigma}}{\sqrt{\frac{(n-1)S^2}{\sigma^2} \cdot \frac{1}{n-1}}} \sim t(n-1).$
其中,分子服从$N(0,1)$,分母为$\sqrt{\chi^2(n-1)/(n-1)}$,符合t分布的定义。
步骤4:排除干扰项
- 选项A、C的自由度为$n$,错误。
- 选项D的表达式与B相同,但需确认题目选项是否区分其他差异(本题中B为正确选项)。