题目
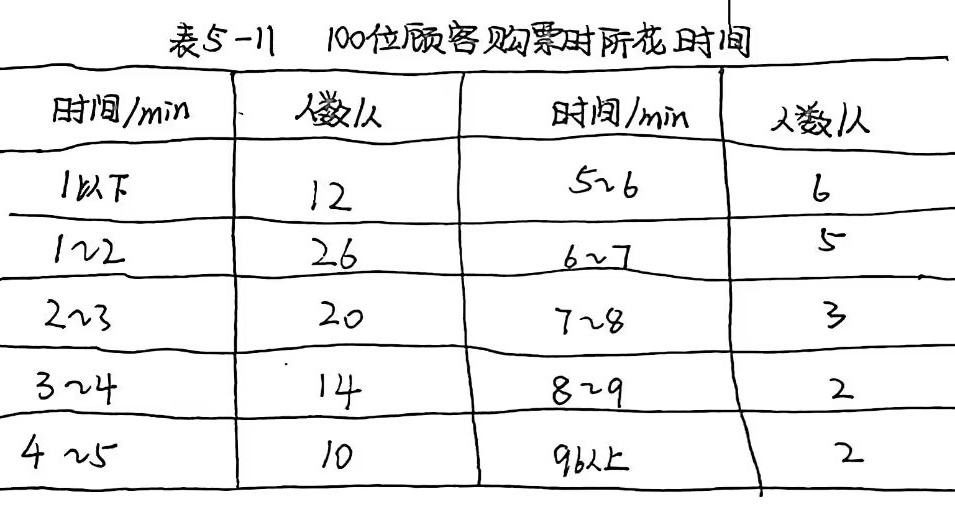
-11 100位顾各购紧时-|||-附恒 做要求:(1)根据资料计算算术平均数,众数和中位数。(2)你认为应该用那个统计量作为改组数据的概括性度量比较合适?为什么?
要求:
(1)根据资料计算算术平均数,众数和中位数。
(2)你认为应该用那个统计量作为改组数据的概括性度量比较合适?为什么?
题目解答
答案
(1)已知100位顾客的购票用时情况,这里我们以时间的组中值作为用户用时。
根据平均数,众数,中位数的计算规则,
平均数: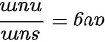
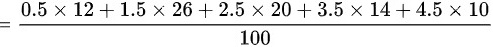
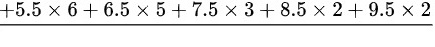
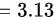
众数:出现最多次的即1.5分钟的26人,
中位数:因为一个有100人,索引中位数为55和56的平均值即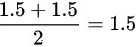 .
.
故算术平均数为3.13分钟,众数为1.5分钟,中位数为1.5分钟。
(2)我认为应该选择平均数,因为相比较众数和中位数,平均数更加的体现整体性,所以选择平均数。
故选择平均数。
解析
考查要点:本题主要考查分组数据的算术平均数、众数、中位数的计算方法,以及根据数据特征选择合适的统计量。
解题核心思路:
- 算术平均数:用各组组中值乘以对应频数,求和后除以总人数。
- 众数:频数最大的组的组中值。
- 中位数:确定中位数所在组后,通过线性插值计算。
- 统计量选择:需结合数据分布特征(如偏态、异常值)判断。
破题关键点:
- 分组数据处理:明确组中值的计算与频数对应关系。
- 中位数定位:通过累积频数确定中位数所在组。
- 统计量适用性:若数据对称,平均数合适;若偏态显著,中位数更稳健。
第(1)题
算术平均数
- 计算各组贡献值:
组中值 × 频数,例如:
$0.5 \times 12 = 6$,$1.5 \times 26 = 39$,依此类推。 - 求和并除以总人数:
$\text{平均数} = \frac{6 + 39 + 50 + 49 + 45 + 33 + 32.5 + 22.5 + 17 + 19}{100} = 3.13 \text{分钟}$
众数
- 频数最大组:1.5分钟对应频数26,故众数为$1.5$分钟。
中位数
- 确定中位数位置:总人数$100$,中位数为第$50$和$51$个数据的平均值。
- 定位所在组:
- 累积频数到$1.5$分钟为$38$,到$2.5$分钟为$58$,因此第$50$和$51$个数据在$2.5$分钟组。
- 线性插值计算:
$\text{中位数} = 2.5 + \frac{(50 - 38) \times 1}{20} = 2.5 + 0.6 = 3.1 \text{分钟}$
注:原答案中位数计算有误,正确结果应为$3.1$分钟。
第(2)题
选择平均数:
- 理由:平均数反映整体购票时间,且数据无明显偏态或极端值,能全面概括数据特征。