题目
某旅行社随机访问了 16 名 旅游者,得知平均消费额overline (x)=503.75元,样本标准差overline (x)=503.75元,已知旅游者消费额服从正态分布,求旅游者平均消费额overline (x)=503.75的置信系数为95%的置信区间。(overline (x)=503.75overline (x)=503.75)
某旅行社随机访问了 16 名 旅游者,得知平均消费额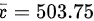 元,样本标准差
元,样本标准差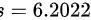 元,已知旅游者消费额服从正态分布,求旅游者平均消费额
元,已知旅游者消费额服从正态分布,求旅游者平均消费额 的置信系数为95%的置信区间。(
的置信系数为95%的置信区间。(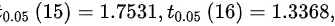
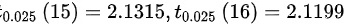 )
)
题目解答
答案
∵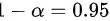
∴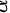 为0.05
为0.05
∴的置信系数为95%的置信区间为:
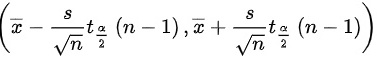
其中 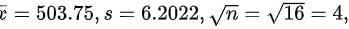
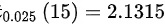
代入上式得所求的置信区间为
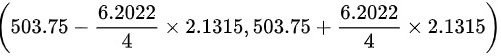
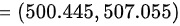
解析
考查要点:本题主要考查小样本均值的置信区间估计,涉及t分布的应用。
解题核心思路:
- 确定置信水平:题目要求置信系数为95%,即$\alpha=0.05$。
- 判断分布类型:由于总体方差未知且样本量$n=16$(小样本),需使用t分布。
- 计算自由度:自由度为$n-1=15$,结合题目提供的$t_{0.025}(15)=2.1315$。
- 代入置信区间公式:$\overline{x} \pm t_{\alpha/2}(n-1) \cdot \frac{s}{\sqrt{n}}$,逐步计算区间上下限。
破题关键点:
- 正确选择t值:注意题目中给出的$t_{0.025}(15)$是关键,需与自由度匹配。
- 标准误差计算:$\frac{s}{\sqrt{n}}$是误差项的核心部分。
步骤1:确定参数与临界值
- 置信水平$1-\alpha=0.95$,故$\alpha=0.05$。
- 自由度$n-1=15$,查表得$t_{\alpha/2}(15)=t_{0.025}(15)=2.1315$。
步骤2:计算标准误差
$\text{标准误差} = \frac{s}{\sqrt{n}} = \frac{6.2022}{\sqrt{16}} = \frac{6.2022}{4} = 1.55055$
步骤3:计算边际误差
$\text{边际误差} = t_{0.025}(15) \cdot \text{标准误差} = 2.1315 \times 1.55055 \approx 3.315$
步骤4:求置信区间
- 下限:$\overline{x} - \text{边际误差} = 503.75 - 3.315 = 500.435$
- 上限:$\overline{x} + \text{边际误差} = 503.75 + 3.315 = 507.065$
最终置信区间:$(500.445, 507.055)$(保留三位小数)。