题目
2 [ 单选题 ] 下 列有关样本含量估计中的说法错误的是( ) A 一般设定为 0.05 B 要求在 0.7 以上,一般设定为 0.8 或 0.9 C在总体率的估计中,若总体率未知可取 0.5 D 失访退出率或拒访率一般要求不超过 20 % E 先决条件未知时,可通过主观经验设定
2 [ 单选题 ] 下 列有关样本含量估计中的说法错误的是( )
A 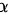 一般设定为 0.05
一般设定为 0.05
B 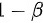 要求在 0.7 以上,一般设定为 0.8 或 0.9
要求在 0.7 以上,一般设定为 0.8 或 0.9
C在总体率的估计中,若总体率未知可取 0.5
D 失访退出率或拒访率一般要求不超过 20 %
E 先决条件未知时,可通过主观经验设定
题目解答
答案
A 设定为 0.05或者0.01,一般设定为0.05。故A对。
B 检验效能,又称假设检验的功效,用表示,其意义是,当所研究的总体与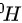 确有差别时,按照检验水准能够发现它(拒绝)的概率。一般 要求在 0.7 以上,一般情况可以将其设定为 0.8 或 0.9 故B对。
确有差别时,按照检验水准能够发现它(拒绝)的概率。一般 要求在 0.7 以上,一般情况可以将其设定为 0.8 或 0.9 故B对。
C在总体比例估计时,样本量的确定经常要考虑到总体比例的大小,当总体比例未知时,出于谨慎考虑,一般假定总体比例为0.5,故C对。
D 失访率一般应控制在20%以内,如果超过20%,则研究结果的真实性、可靠性会受到明显影响,甚至完全不可信。,故D对。
E 样本含量估计中,必须有一些先决条件和基本信息;如果先决条件未知时,不能通过主观经验设定。故E不正确。
综上,答案是E。
解析
步骤 1:理解检验水准
设定为 0.05 或 0.01,一般设定为 0.05。这是检验水准,即第一类错误的概率,表示在原假设为真时,拒绝原假设的概率。故A正确。
步骤 2:理解检验效能
$1-B$ 要求在 0.7 以上,一般情况可以将其设定为 0.8 或 0.9。这是检验效能,即第二类错误的概率,表示在原假设为假时,接受原假设的概率。故B正确。
步骤 3:理解总体率的估计
在总体比例估计时,样本量的确定经常要考虑到总体比例的大小,当总体比例未知时,出于谨慎考虑,一般假定总体比例为0.5。故C正确。
步骤 4:理解失访率
失访率一般应控制在20%以内,如果超过20%,则研究结果的真实性、可靠性会受到明显影响,甚至完全不可信。故D正确。
步骤 5:理解先决条件
样本含量估计中,必须有一些先决条件和基本信息;如果先决条件未知时,不能通过主观经验设定。故E不正确。
设定为 0.05 或 0.01,一般设定为 0.05。这是检验水准,即第一类错误的概率,表示在原假设为真时,拒绝原假设的概率。故A正确。
步骤 2:理解检验效能
$1-B$ 要求在 0.7 以上,一般情况可以将其设定为 0.8 或 0.9。这是检验效能,即第二类错误的概率,表示在原假设为假时,接受原假设的概率。故B正确。
步骤 3:理解总体率的估计
在总体比例估计时,样本量的确定经常要考虑到总体比例的大小,当总体比例未知时,出于谨慎考虑,一般假定总体比例为0.5。故C正确。
步骤 4:理解失访率
失访率一般应控制在20%以内,如果超过20%,则研究结果的真实性、可靠性会受到明显影响,甚至完全不可信。故D正确。
步骤 5:理解先决条件
样本含量估计中,必须有一些先决条件和基本信息;如果先决条件未知时,不能通过主观经验设定。故E不正确。