题目
一种产品需要人工组装,现有三种可供选择的组装方法。为检验哪种方法更好,随机抽取15个工人,让他们分别用三种方法组装。下面是15个工人分别用三种方法在相同的时间组装的产品数量(单位:个):方法A方法B方法C164129125167130126168129126165130127170131126165130128164129127168127126164128127162128127163127125166128126167128116166125126165132125(1)你准备采用什么方法来评价组装方法的优劣?(2)如果让你选择一种方法,你会作出怎样的选择?试说明理由。
一种产品需要人工组装,现有三种可供选择的组装方法。为检验哪种方法更好,随机抽取15个工人,让他们分别用三种方法组装。下面是15个工人分别用三种方法在相同的时间组装的产品数量(单位:个):
方法A
方法B
方法C
164
129
125
167
130
126
168
129
126
165
130
127
170
131
126
165
130
128
164
129
127
168
127
126
164
128
127
162
128
127
163
127
125
166
128
126
167
128
116
166
125
126
165
132
125
(1)你准备采用什么方法来评价组装方法的优劣?
(2)如果让你选择一种方法,你会作出怎样的选择?试说明理由。
题目解答
答案
解:(1)下表给计算出这三种组装方法的一些主要描述统计量:
方法A | 方法B | 方法C | |||
平均 | 165.6 | 平均 | 128.73 | 平均 | 125.53 |
中位数 | 165 | 中位数 | 129 | 中位数 | 126 |
众数 | 164 | 众数 | 128 | 众数 | 126 |
标准偏差 | 2.13 | 标准偏差 | 1.75 | 标准偏差 | 2.77 |
极差 | 8 | 极差 | 7 | 极差 | 12 |
最小值 | 162 | 最小值 | 125 | 最小值 | 116 |
最大值 | 170 | 最大值 | 132 | 最大值 | 128 |
评价优劣应根据离散系数,据上得:
方法A的离散系数VA=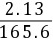 =0.0129,
=0.0129,
方法B的离散系数VB=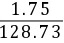 =0.0136,
=0.0136,
方法C的离散系数VC=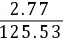 =0.0221;
=0.0221;
对比可见,方法A的离散系数最低,说明方法A最优。
(2)我会选择方法A,因为方法A的平均产量最高而离散系数最低,说明方法A的产量高且稳定,有推广意义。
解析
步骤 1:计算描述统计量
首先,我们需要计算每种组装方法的描述统计量,包括平均值、中位数、众数、标准偏差、极差、最小值和最大值。这些统计量可以帮助我们了解每种方法的中心趋势和离散程度。
步骤 2:计算离散系数
离散系数是标准偏差与平均值的比值,它可以帮助我们比较不同方法的离散程度。离散系数越小,说明该方法的产量越稳定。
步骤 3:选择最优方法
根据离散系数和平均产量,选择最优的组装方法。最优方法应具有较高的平均产量和较低的离散系数,以确保产量高且稳定。
首先,我们需要计算每种组装方法的描述统计量,包括平均值、中位数、众数、标准偏差、极差、最小值和最大值。这些统计量可以帮助我们了解每种方法的中心趋势和离散程度。
步骤 2:计算离散系数
离散系数是标准偏差与平均值的比值,它可以帮助我们比较不同方法的离散程度。离散系数越小,说明该方法的产量越稳定。
步骤 3:选择最优方法
根据离散系数和平均产量,选择最优的组装方法。最优方法应具有较高的平均产量和较低的离散系数,以确保产量高且稳定。