拟合优度和统计检验拟合优度的度量:由表中可以看出本题中可决系数为0。977058,说明所建模型整体上对样本数据拟合度较好,即解释变量“本市生产总值”对被解释变量“地方预算内财政收入”的绝大部分差异做出了解释。对回归系数的t检验:针对:和:,由表中还可以看出,估计的回归系数的标准误差和t值分别为:SE()=9。867440,t()=2.073593;的标准误差和t值分别为:SE()=0。003255,t()=26.10376。取ɑ=0.05,查t分布表得自由度为n—2=18—2=16的临界值。因为t()=2.073593<,所以应拒绝:;因为t()=26.10376〉,所以应拒绝:。这表明,本市生产总值对地方预算内财政收入确有显著影响。2.41)。模型设定为了研究最终消费(Y)与国民总收入(X)的关系,作如下散点图从散点图可以看出最终消费(Y)和国民总收入(X)大体上呈现为线性关系,为分析最终消费随国民总收入变动的数量规律性,可以建立如下简单线性回归模型:2).估计参数假定所建模型及其中的随机扰动项uᵢ由相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实确实存在严重多重共线性。(2)因为存在多重共线性,解决方法如下:1)。修正理论假设,在高度相关的变量中选择相关程度最高的变量进行回归建立模型:2).进行逐步回归,直至模型符合需要研究的问题,具有实际的经济意义和统计意义。5。1(1)因为,所以取,用乘给定模型两端,得上述模型的随机误差项的方差为一固定常数,即(2)根据加权最小二乘法,可得修正异方差后的参数估计式为其中5。21).估计结果为:(3.638437)(0.019903)t=(2。569104)(32。00881)=0。946423F=1024.5642).Goldfeld-Quandt法检验A. 。对变量取值排序(按递增); B. 构造子样本区间,建立回归模型.在本例中,样本容量n=60,删除中间1/4的观测值,即约15个观测值,余下部分平分得两个样本区间:1~22和39~60. 样本区间为1~22的回归估计结果为: C. 样本区间为39~60的回归估计结果为: D. E. 统计量值:由上表可得,,根据 F. oldfeld—Quandt检验,F统计量为: G. 分布表得临界值,因为F=4。14>,表明模型确实存在异方差。 While检验: While检验结果,如表: While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为 =10.86401〉,表明模型确实存在异方差。 3)。用权数,作加权最小二乘估计,得如下结果: (2。629716)(0.018532) t=(3.943587)(34.04667) W=0。958467,F=1159.176 5.3 X代表家庭人均纯收入,Y家庭生活消费支出) 由回归结果可得:(221。5775)(0。0457) t=(0.808709)(15。74411) =247。8769 While检验,辅助函数为:,经经估计出现While检验结果,如表:从表中可以看出,=10.52295,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为 =10.52295>,表明模型确实存在异方差。 分析该模型存在异方差的理由是,从数据可以看出,一是截面数据;二是各省市经济发展不平衡,使得一些省市农村居民收入高出其它省市很多,如上海市、北京市、天津市和浙江省等。而有的省就很低,如甘肃省、贵州省、云南省和陕西省等。 ^2,w3=1/sqr(x),经检验用权数的效果最好,用权数w3的结果如下: ⏺
拟合优度和统计检验
拟合优度的度量:由表中可以看出本题中可决系数为0。977058,说明所建模型整体上对样本数据拟合度较好,即解释变量“本市生产总值”对被解释变量“地方预算内财政收入”的绝大部分差异做出了解释。
对回归系数的t检验:针对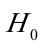 :
: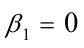 和:
和: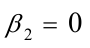 ,由表中还可以看出,估计的回归系数
,由表中还可以看出,估计的回归系数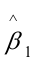 的标准误差和t值分别为:SE()=9。867440,t()=2.073593;
的标准误差和t值分别为:SE()=9。867440,t()=2.073593;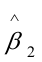 的标准误差和t值分别为:SE()=0。003255,t()=26.10376。取ɑ=0.05,查t分布表得自由度为n—2=18—2=16的临界值
的标准误差和t值分别为:SE()=0。003255,t()=26.10376。取ɑ=0.05,查t分布表得自由度为n—2=18—2=16的临界值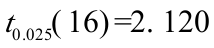 。因为t()=2.073593<,所以应拒绝:;因为t()=26.10376〉,所以应拒绝:。这表明,本市生产总值对地方预算内财政收入确有显著影响。
。因为t()=2.073593<,所以应拒绝:;因为t()=26.10376〉,所以应拒绝:。这表明,本市生产总值对地方预算内财政收入确有显著影响。
2.4
1)。模型设定
为了研究最终消费(Y)与国民总收入(X)的关系,作如下散点图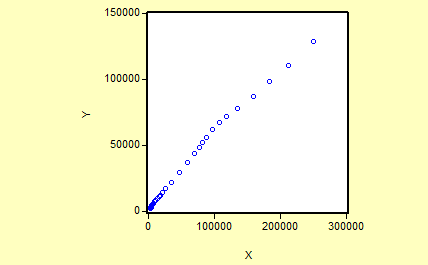 从散点图可以看出最终消费(Y)和国民总收入(X)大体上呈现为线性关系,为分析最终消费随国民总收入变动的数量规律性,可以建立如下简单线性回归模型:
从散点图可以看出最终消费(Y)和国民总收入(X)大体上呈现为线性关系,为分析最终消费随国民总收入变动的数量规律性,可以建立如下简单线性回归模型: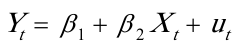 2).估计参数
2).估计参数
假定所建模型及其中的随机扰动项uᵢ
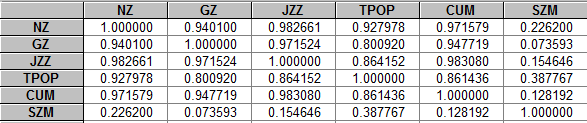
由相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实确实存在严重多重共线性。
(2)因为存在多重共线性,解决方法如下:
1)。修正理论假设,在高度相关的变量中选择相关程度最高的变量进行回归建立模型:
2).进行逐步回归,直至模型符合需要研究的问题,具有实际的经济意义和统计意义。5。1
(1)因为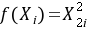 ,所以取
,所以取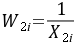 ,用
,用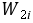 乘给定模型两端,得
乘给定模型两端,得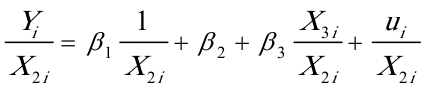 上述模型的随机误差项的方差为一固定常数,即
上述模型的随机误差项的方差为一固定常数,即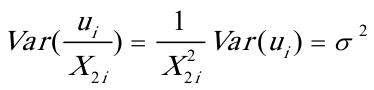 (2)根据加权最小二乘法,可得修正异方差后的参数估计式为
(2)根据加权最小二乘法,可得修正异方差后的参数估计式为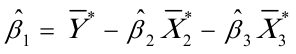
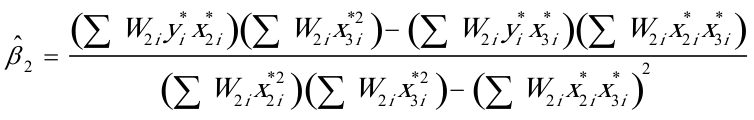
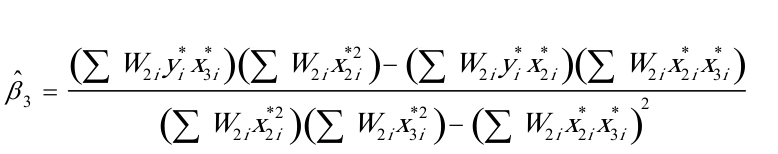 其中
其中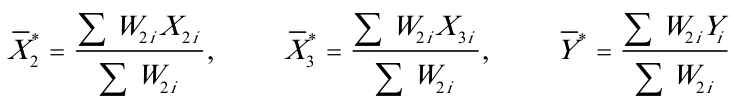
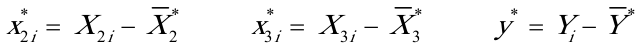
5。2
1).
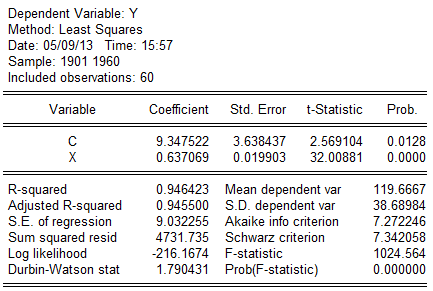
估计结果为: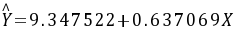 (3.638437)(0.019903)
(3.638437)(0.019903)
t=(2。569104)(32。00881)
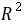 =0。946423F=1024.564
=0。946423F=1024.564
2).
Goldfeld-Quandt法检验
A. 。对变量取值排序(按递增);B. 构造子样本区间,建立回归模型.在本例中,样本容量n=60,删除中间1/4的观测值,即约15个观测值,余下部分平分得两个样本区间:1~22和39~60. 样本区间为1~22的回归估计结果为:
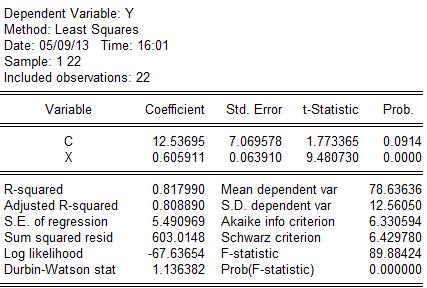
C. 样本区间为39~60的回归估计结果为:
D.
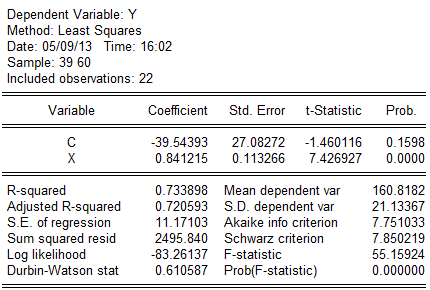
E. 统计量值:由上表可得
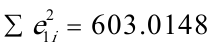 ,
,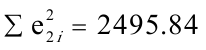 ,根据
,根据F. oldfeld—Quandt检验,F统计量为:
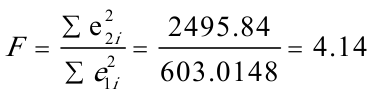
G. 分布表得临界值
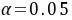 ,因为F=4。14>
,因为F=4。14>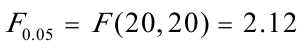 ,表明模型确实存在异方差。
,表明模型确实存在异方差。While检验:
While检验结果,如表:
While检验知,在
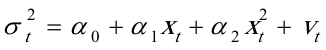 下,查
下,查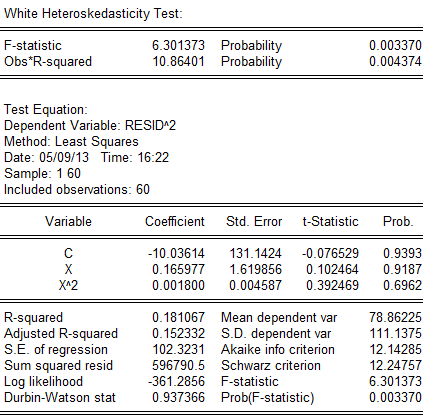 分布表,得临界值
分布表,得临界值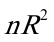 ,同时
,同时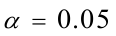 和
和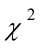 的t检验值也显著,因为
的t检验值也显著,因为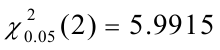 =10.86401〉
=10.86401〉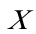 ,表明模型确实存在异方差。
,表明模型确实存在异方差。3)。用权数
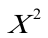 ,作加权最小二乘估计,得如下结果:(2。629716)(0.018532)
,作加权最小二乘估计,得如下结果:(2。629716)(0.018532)t=(3.943587)(34.04667)
W=0。958467,F=1159.176
5.3
X代表家庭人均纯收入,Y家庭生活消费支出)
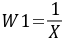
由回归结果可得:
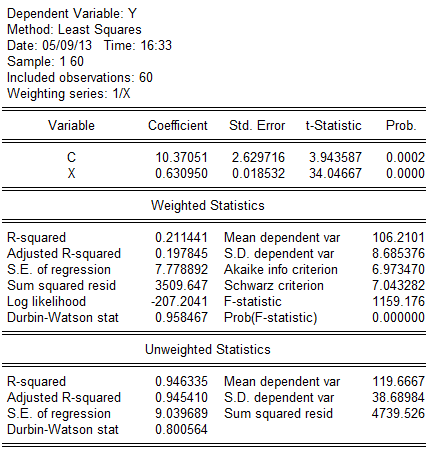 (221。5775)(0。0457)
(221。5775)(0。0457)t=(0.808709)(15。74411)
=247。8769
While检验,辅助函数为:
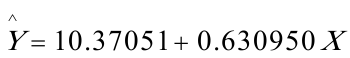 ,经经估计出现While检验结果,如表:
,经经估计出现While检验结果,如表: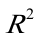 从表中可以看出,
从表中可以看出,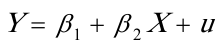 =10.52295,由While检验知,在
=10.52295,由While检验知,在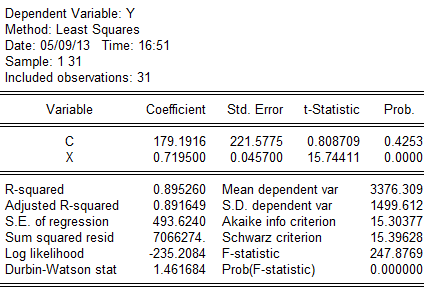 下,查
下,查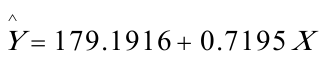 分布表,得临界值,同时和
分布表,得临界值,同时和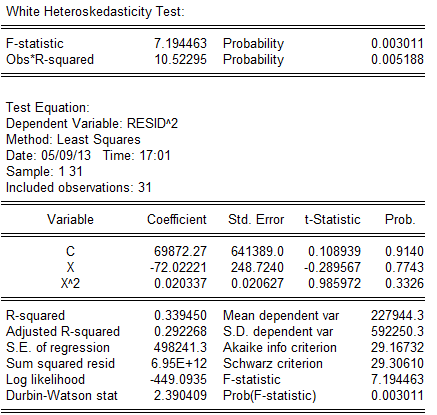 的t检验值也显著,因为=10.52295>,表明模型确实存在异方差。
的t检验值也显著,因为=10.52295>,表明模型确实存在异方差。分析该模型存在异方差的理由是,从数据可以看出,一是截面数据;二是各省市经济发展不平衡,使得一些省市农村居民收入高出其它省市很多,如上海市、北京市、天津市和浙江省等。而有的省就很低,如甘肃省、贵州省、云南省和陕西省等。
^2,w3=1/sqr(x),经检验用权数
的效果最好,用权数w3的结果如下:⏺
题目解答
答案
拟合优度和统计检验
拟合优度的度量:由表中可以看出本题中可决系数为0.990769,说明所建模型整体上对样本数据拟合度较好,即解释变量“国民总收入”对被解释变量“最终消费”的绝大部分差异做出了解释。
对回归系数的t检验:针对:和:,由表中还可以看出,估计的回归系数的标准误差和t值分别为:SE()=895。4040,t()=3。399965;的标准误差和t值分别为:SE()=0.009670,t()=54。82076。取ɑ=0。05,查t分布表得自由度为n-2=30-2=28的临界值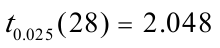 。因为t()=3。399965〉,所以应拒绝:;因为t()=54。82076〉,所以应拒绝:.这表明,国民总收入对最终消费确有显著影响。
。因为t()=3。399965〉,所以应拒绝:;因为t()=54。82076〉,所以应拒绝:.这表明,国民总收入对最终消费确有显著影响。
2.5
1).模型设定
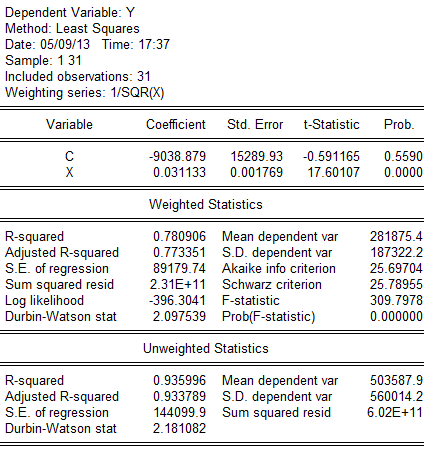
估计结果为: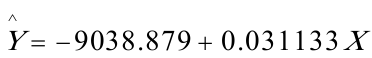 (15289.93)(0。001769)
(15289.93)(0。001769)
t=(-0。591165)(17。60107)
=0.780906,DW=2.097539,F=309.7978
5。6
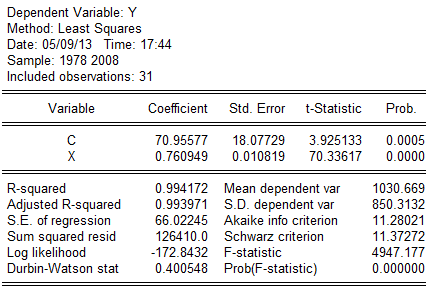
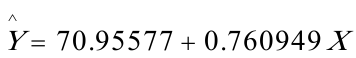
(18。07729)(0。010819)
t=(3.925133)(70。33617)
=0。994172,F=4947。177
根据While检验,辅助函数为:,经经估计出现While检验结果,如表: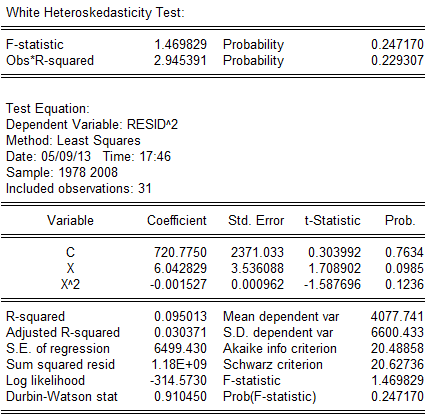 从表中可以看出,=2.945391,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为=2。945391〉,表明模型确实存在异方差。
从表中可以看出,=2.945391,由While检验知,在下,查分布表,得临界值,同时和的t检验值也显著,因为=2。945391〉,表明模型确实存在异方差。
分别选用权数w1=1/x,w2=1/x^2,w3=1/sqr(x),经检验用权数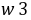 的效果最好,用权数w3的结果如下:
的效果最好,用权数w3的结果如下:
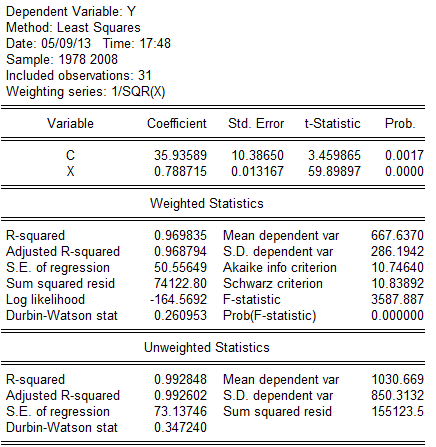
估计结果为: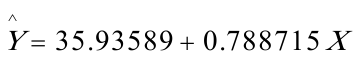 (10。3865)(0.013167)
(10。3865)(0.013167)
t=(3.459865)(59.89897)
=0。969835,DW=0。260935,F=3587。8876。1
(1).根据数据其回归结果为:
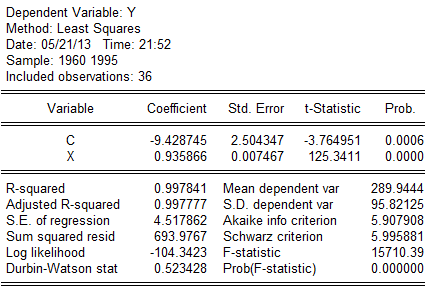
建立模型如下: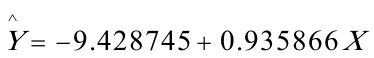 (2。504347)(0.007467)
(2。504347)(0.007467)
t=(—3。764951)(125。3411)
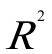 =0。997841,F=15710.39,DW=0。523428
=0。997841,F=15710.39,DW=0。523428
.其残差图如下: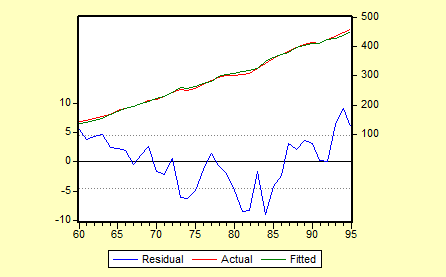 由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。
由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。
对样本容量为36、一个解释变量的模型、1%显著水平,查DW统计表可知,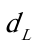 =1.026,
=1.026,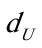 =1.315,0<DW〈,显然模型中存在自相关.
=1.315,0<DW〈,显然模型中存在自相关.
(2)对残差进行回归分析:
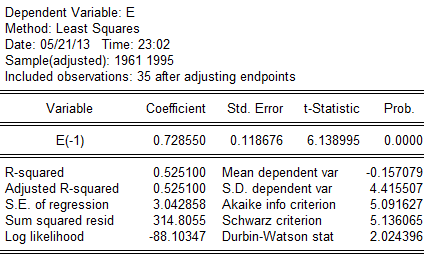
回归方程为: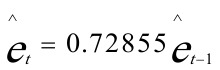 对原模型进行广义差分,得广义差分方程:
对原模型进行广义差分,得广义差分方程: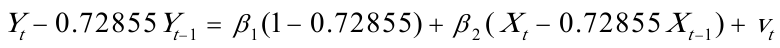 回归结果为:
回归结果为: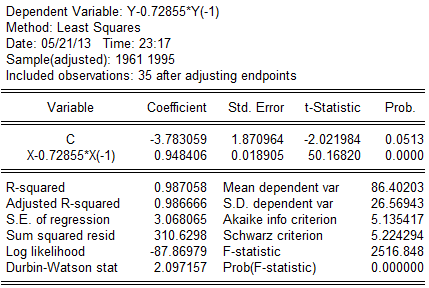 可得回归方程为:
可得回归方程为: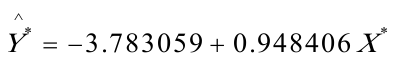 (1.870964)(0.018905)
(1.870964)(0.018905)
t=(—2.021984)(50.1682)
=0.987058,F=2516.848,DW=2。097157
其中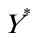 =
=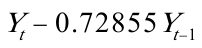 ,
,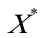 =
=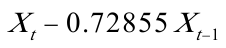 .
.
⏺
由于使用了广义差分数据,样本容量减少了一个,为35个,查1%显著水平的DW统计表可知=1。195,=1.307,模型中DW>,说明模型在1%显著性水平下广义差分模型已无自相关,不必再进行迭代。同时可见,可决系数,t,F统计量也均达到理想水平。
由差分方程得: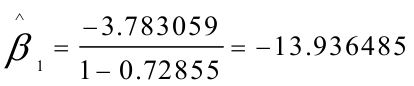 所以,最终模型为:
所以,最终模型为: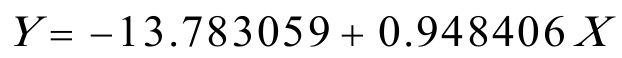 6。3
6。3
(1)。根据数据其回归结果为: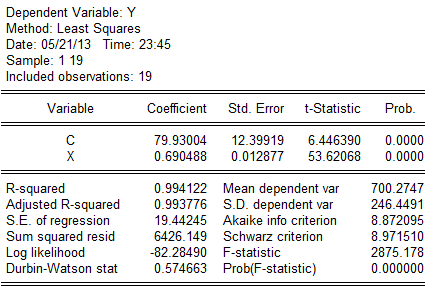 建立模型如下:
建立模型如下: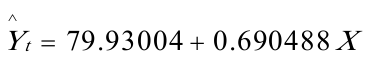 (12。39919)(0.012877)
(12。39919)(0.012877)
t=(6.446390)(53。62068)
=0。994122,F=2875。178,DW=0.574663
其残差图如下:
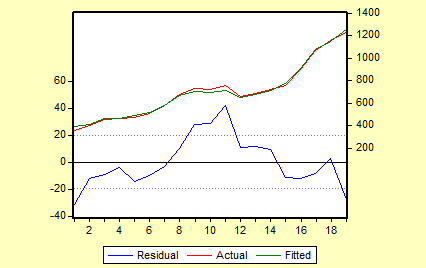
由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。
对样本容量为19、一个解释变量的模型、1%显著水平,查DW统计表可知,=0。928,=1。132,0〈DW〈,显然模型中存在自相关。
(2).对残差进行回归分析: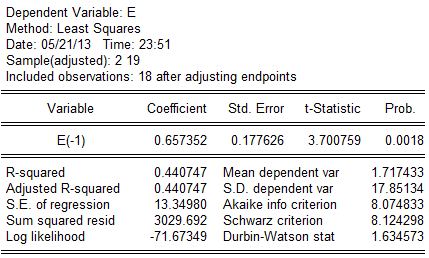 回归方程为:
回归方程为: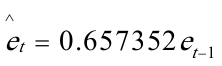 对原模型进行广义差分,得广义差分方程:
对原模型进行广义差分,得广义差分方程: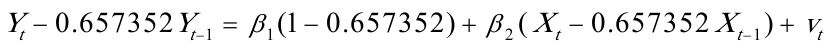 回归结果为:
回归结果为:
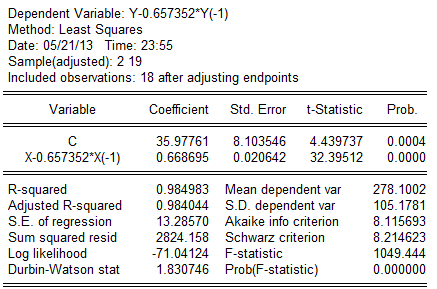
可得回归方程为: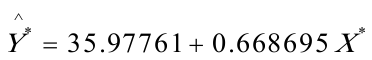 (8。103546)(0。020642)
(8。103546)(0。020642)
t=(4。439737)(32。39512)
=0。984983,F=1049。444,DW=1.830746
其中=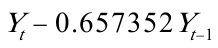 ,=
,=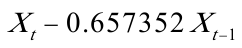 .
.
由于使用了广义差分数据,样本容量减少了一个,为18个,查1%显著水平的DW统计表可知=0。902,=1.132,模型中DW〉,说明模型在1%显著性水平下广义差分模型已无自相关,不必再进行迭代.同时可见,可决系数,t,F统计量也均达到理想水平。
由差分方程得: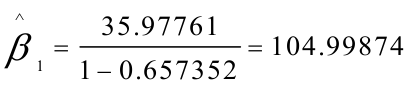 所以,最终模型为:
所以,最终模型为: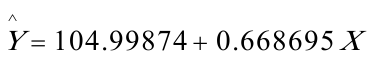 (3)。其经济意义为:其经济意义为:北京市人均实际收入增加1元时,平均说来人均实际生活消费支出将增加0。668695元.
(3)。其经济意义为:其经济意义为:北京市人均实际收入增加1元时,平均说来人均实际生活消费支出将增加0。668695元.
6.4
(1).根据数据其回归结果为:
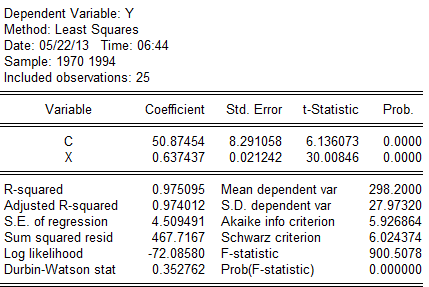
建立模型如下: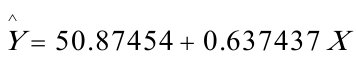 (8。291058)(0。021242)
(8。291058)(0。021242)
t=(6.136073)(30.00846)
=0。975095,F=900。5078,DW=0.352762
其残差图如下: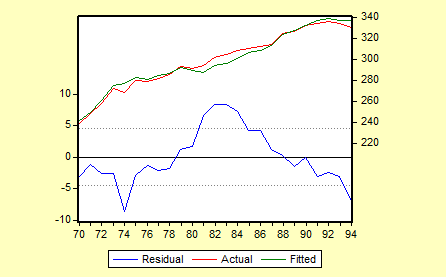 由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。
由残差图可知,残差的变动有系统模式,连续为正和连续为负,表明残差项可能存在一阶正自相关。
对样本容量为25、一个解释变量的模型、1%显著水平,查DW统计表可知,=1。055,=1。211,0〈DW<,显然模型中存在自相关.
(2)。对残差进行回归分析:
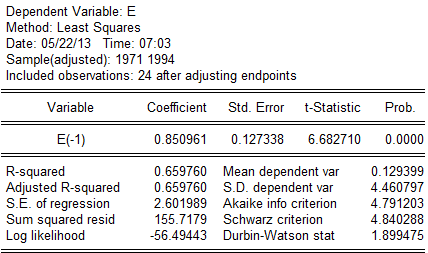
回归方程为: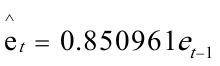 对原模型进行广义差分,得广义差分方程:
对原模型进行广义差分,得广义差分方程: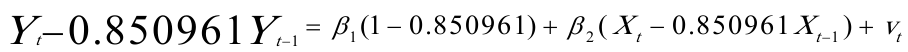 回归结果为:
回归结果为: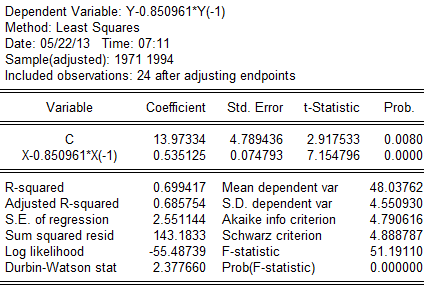 可得回归方程为:
可得回归方程为: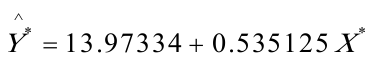 (4。789436)(0.074793)
(4。789436)(0.074793)
t=(2。917533)(7.154796)
=0.699417,F=51。1911,DW=2.37766
其中=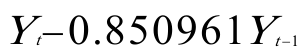 ,=
,=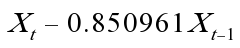 。
。
⏺
选择“航班正点率"为解释变量(用X表示),“每10万乘客投诉一次的投诉率”为被解释变量(用Y表示)。为了研究航班正点率(X)与每10万乘客投诉一次的投诉率(Y)的关系,作如下散点图: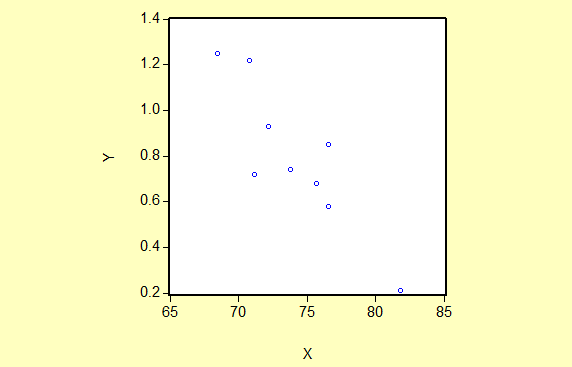 从散点图可以看出投诉率(Y)和航班正点率(X)大体上呈现为负相关关系,为分析投诉率随航班正点率变动的数量规律性,可以建立如下简单线性回归模型:2)。估计参数
从散点图可以看出投诉率(Y)和航班正点率(X)大体上呈现为负相关关系,为分析投诉率随航班正点率变动的数量规律性,可以建立如下简单线性回归模型:2)。估计参数
假定所建模型及其中的随机扰动项uᵢ满足各项古典假设,用EViews软件分析的回归结果如下表所示: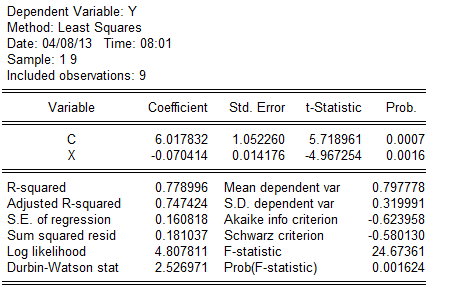 可用规范的形式将参数估计和检验的结果写为
可用规范的形式将参数估计和检验的结果写为
由于使用了广义差分数据,样本容量减少了一个,为24个,查1%显著水平的DW统计表可知=1。037,=1。199,模型中DW〉,说明模型在1%显著性水平下广义差分模型已无自相关,不必再进行迭代。同时可见,可决系数,t,F统计量也均达到理想水平。
由差分方程得: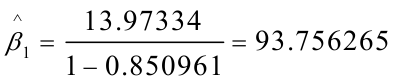 所以,最终模型为:
所以,最终模型为: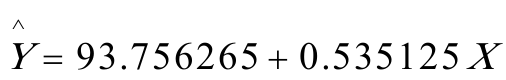 (3).模型说明日本工薪居民的边际消费倾向为0。535125,即收入每增加1元,平均说来消费增加0.535125元。
(3).模型说明日本工薪居民的边际消费倾向为0。535125,即收入每增加1元,平均说来消费增加0.535125元。
(1。052260)(0.014176)
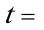 (5。718961)(—4。967254)
(5。718961)(—4。967254)
R2=0。778996F=24。67361n=9
从表中可以看出航班正点率对投诉率确有显著影响,本题中可决系数为0.778996,说明所建模型整体上对样本数据拟合度较好,即解释变量“航班正点率"对被解释变量“投诉率"的绝大部分差异做出了解释。
所估计的参数=6.017832,=—0.070414,说明航班正点率每下降一个百分点,平均说来可导致投诉率增加0.070414个百分点
2。6
1).模型设定
为了研究某年公益股票的每股账面价值(Y)与当年红利(X)的关系,作如下散点图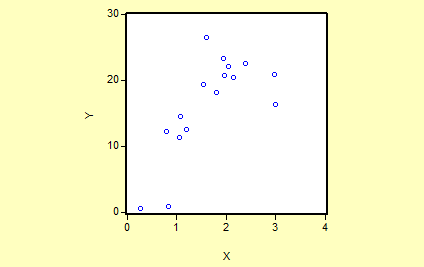 从散点图可以看出每股账面价值(Y)和当年红利(X)大体上呈现为一定的相关关系,为分析每股账面价值随当年红利变动的数量规律性,可以建立如下简单线性回归模型:2)。估计参数
从散点图可以看出每股账面价值(Y)和当年红利(X)大体上呈现为一定的相关关系,为分析每股账面价值随当年红利变动的数量规律性,可以建立如下简单线性回归模型:2)。估计参数
假定所建模型及其中的随机扰动项uᵢ满足各项古典假设,用EViews软件分析的回归结果如下表所示:
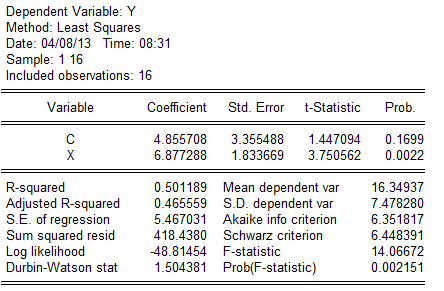
可用规范的形式将参数估计和检验的结果写为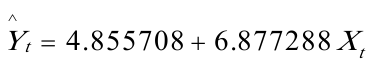 (3.355488)(1。833669)
(3.355488)(1。833669)
(1。447094)(3。750562)
R2=0。501189n=16
3)。模型检验
1。经济意义检验
所估计的参数=4.855708,=6。877288,说明某股票的当年红利每增加1元,平均说来可导致账面价值增加6.877288元。
2。拟合优度和统计检验
拟合优度的度量:由表中可以看出本题中可决系数为0,501189,说明所建模型整体上对样本数据拟合度较好,即解释变量“当年红利"对被解释变量“账面价值”的绝大部分差异做出了解释。
对回归系数的t检验:因为t()=3.750562〉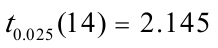 ,这表明,当年每股红利对账面价值确有显著影响。
,这表明,当年每股红利对账面价值确有显著影响。
2。8
分别设定简单线性回归模型,分析亚洲各国人均寿命(Y)与按购买力平价计算的人均GDP(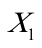 )、成人识字率(
)、成人识字率(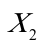 )、一岁儿童疫苗接种率(
)、一岁儿童疫苗接种率(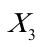 )之间的关系;
)之间的关系;
(1)。为分析各国人均寿命(Y)随人均GDP()变动的数量规律性,可以建立如下简单线性回归模型: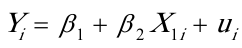 估计检验结果:
估计检验结果:
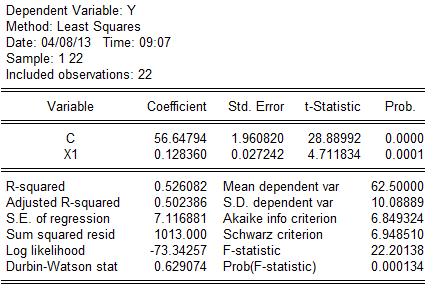
(2)。为分析各国人均寿命(Y)随成人识字率()变动的数量规律性,可以建立如下简单线性回归模型: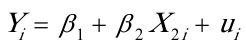 估计检验结果:
估计检验结果: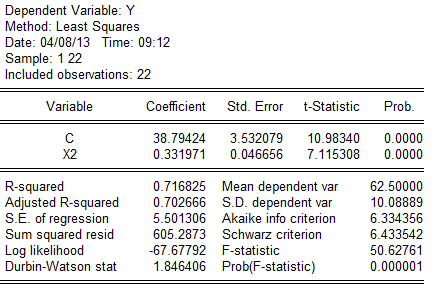 (3)。为分析各国人均寿命(Y)随一岁儿童疫苗接种率()变动的数量规律性,可以建立如下简单线性回归模型:
(3)。为分析各国人均寿命(Y)随一岁儿童疫苗接种率()变动的数量规律性,可以建立如下简单线性回归模型: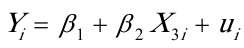 估计检验结果:
估计检验结果:
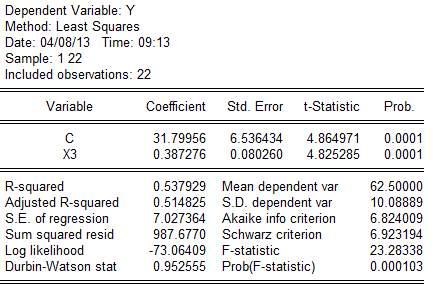
(4).对所建立的多个回归模型进行检验:
由人均GDP、 成人识字率、 一岁儿童疫苗接种率分别对人均寿命回归结果的参数t检验 值均明确大于其临界值,所以人均GDP、成人识字率、一 岁儿童疫苗接种率分别对人均寿命都有显著影响。
(5).分析对比各个简单线性回归模型 :
人均寿命与人均GDP回归的可决系数为0。5261 人均寿命与成人识字率回归的可决系数为0.7168 人均寿命与一岁儿童疫苗接种率的可决系数为0.5379 相对说来,人均寿命由成人识字率作出解释的比重更大一些。
3。3
为了研究家庭书刊年消费支出(Y)与家庭月平均收入(X)、户主受教育年数(T)之间的关系,作如下线性图: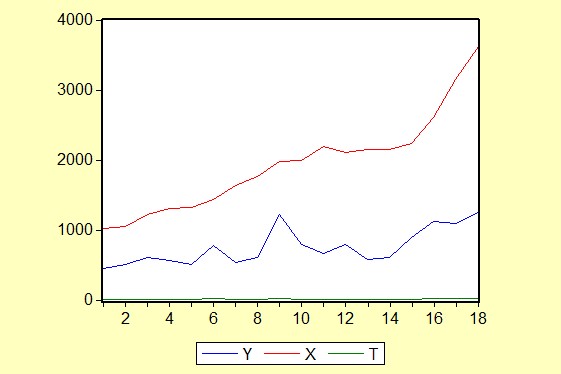
可以看出Y、X都是逐年增长的,但增长速率有所变动,而T在多数情况下呈现出水平波动。说明各变量间不一定是线性关系,故设模型为: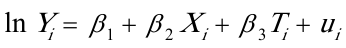 回归结果为:
回归结果为: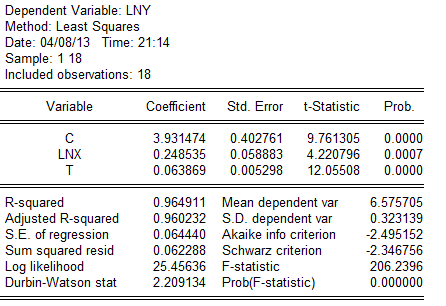 模型统计的结果为:
模型统计的结果为: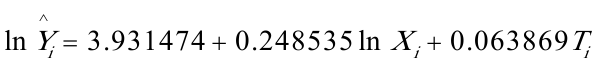 (0.402761)(0。058883)(0。005298)
(0.402761)(0。058883)(0。005298)
t=(9.761305)(4.220796)(12。05508)
=0。964911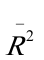 =0.960232F=206.2396n=18
=0.960232F=206.2396n=18
经济检验:
模型估计结果说明,在假定其他变量不变的情况下,家庭月平均收入每增加1元,平均来说家庭书刊年消费支出会增加0.248535元;在假定其他变量不变的情况下,户主受教育年数每增加1年,平均来说家庭书刊年消费支出会增加0。063869元。
统计检验:
1).F检验在F分布表中查出自由度为k-1=2和n—k=15的临界值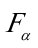 (2,15)=3。68,F=206.2396>(2,15)=3。68,说明“户主受教育年数”对“家庭书刊年消费支出"有显著影响。
(2,15)=3。68,F=206.2396>(2,15)=3。68,说明“户主受教育年数”对“家庭书刊年消费支出"有显著影响。
2)。T检验查t分布表得自由度为n-k=26的临界值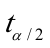 (15)=2.131,与户主受教育年数对应的t统计量为12。05508>(15)=2.131,说明“户主受教育年数”对“家庭书刊年消费支出”有显著影响。
(15)=2.131,与户主受教育年数对应的t统计量为12。05508>(15)=2.131,说明“户主受教育年数”对“家庭书刊年消费支出”有显著影响。
3。4
为了研究实际通货膨胀率(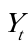 )与失业率(
)与失业率(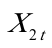 )、预期的通货膨胀率(
)、预期的通货膨胀率(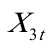 )之间的关系,即
)之间的关系,即