下列描述错误的是()A.样本含量越大,检验效能越高B.o的估计值越大,所需样本含量越大C的估计值越接近0.5,所需样本含量越大D.容许误差越大,样本含量越大E o和的估计值反映计量资料和计数资料的变异程度
下列描述错误的是()
A.样本含量越大,检验效能越高
B.o的估计值越大,所需样本含量越大
C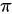 的估计值越接近0.5,所需样本含量越大
的估计值越接近0.5,所需样本含量越大
D.容许误差越大,样本含量越大
E o和的估计值反映计量资料和计数资料的变异程度
题目解答
答案
根据题目中的描述,我们逐项分析选项,找出错误的选项:
A. 样本含量越大,检验效能越高
正确。样本量越大,通常能够更好地反映总体特征,提升统计检验的效能(发现差异的概率)。
B. o的估计值越大,所需样本含量越大
正确。这里的 o 是总体标准差,标准差越大,数据的变异性越大,估计时需要的样本量也就越大,以保证结果的准确性。
C. π的估计值越接近0.5,所需样本含量越大
正确。这里的 π 是总体比例,接近0.5时,样本所需量会最大,因为此时支持的范围最大(标准误最大)。
D. 容许误差越大,样本含量越大
错误。容许误差越大,所需的样本量通常是越小的,因为你允许的误差范围扩大了,那么就不需要那么多样本来达到一定的置信度。
E. o和π的估计值反映计量资料和计数资料的变异程度
正确。总体标准差 o 反映计量资料的变异程度,比例
π 反映计数资料的变异程度。
综上所述,错误的选项是 D:容许误差越大,样本含量应该越小。
解析
本题考查样本含量估算的基本原理,需掌握以下关键点:
- 检验效能与样本量的关系:样本量越大,检验效能越高;
- 总体参数对样本量的影响:总体标准差越大或比例接近0.5时,所需样本量越大;
- 容许误差的作用:容许误差越大,所需样本量越小;
- 资料类型与参数对应关系:σ(标准差)对应计量资料,π(比例)对应计数资料。
选项分析
A. 样本含量越大,检验效能越高
正确。检验效能(把握度)随样本量增加而提高,更大样本能更可靠地检测出实际存在的差异。
B. σ的估计值越大,所需样本含量越大
正确。总体标准差σ越大,数据波动性越大,需更大样本才能保证估计精度。
C. π的估计值越接近0.5,所需样本含量越大
正确。比例π接近0.5时,方差最大(方差公式为π(1-π)),需更大样本才能控制误差范围。
D. 容许误差越大,样本含量越大
错误。容许误差(允许的估计误差范围)越大,所需样本量应越小。公式中样本量与容许误差平方成反比,误差增大时样本量减少。
E. σ和π的估计值反映计量资料和计数资料的变异程度
正确。σ衡量连续性计量资料的离散程度,π衡量二分类计数资料的分布情况。