题目
7.9 从两个正态总体中分别抽取两个独立的随机样本,它们的均值和标准差如下表:-|||-来自总体1的样本 来自总体2的样本-|||-(overline {x)}_(1)=25 _(2)=23-|||-_(1)^2=16 _(2)^2=20-|||-(1)设 _(1)=(n)_(2)=100, 求 (mu )_(1)-(mu )_(2) 的95%的置信区间;

题目解答
答案
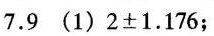
解析
考查要点:本题主要考查两个独立正态总体均值差的置信区间估计,属于大样本情况下的区间估计问题。
解题核心思路:
- 确定使用Z分布:由于样本量较大($n_1 = n_2 = 100$),根据中心极限定理,样本均值之差近似服从正态分布,因此使用Z分布计算临界值。
- 计算标准误:结合两个样本方差,计算均值差的标准误。
- 构造置信区间:利用置信水平对应的Z临界值,结合标准误和样本均值差,得到置信区间。
破题关键:正确识别大样本场景,选择Z分布,并准确代入公式计算标准误和边际误差。
第(1)题
步骤1:确定置信水平与Z临界值
置信水平为95%,对应双侧检验的显著性水平$\alpha = 0.05$,查标准正态分布表得临界值:
$Z_{\alpha/2} = Z_{0.025} = 1.96$
步骤2:计算样本均值差
来自总体1和总体2的样本均值分别为$\overline{x}_1 = 25$和$\overline{x}_2 = 23$,因此均值差为:
$\overline{x}_1 - \overline{x}_2 = 25 - 23 = 2$
步骤3:计算标准误
两个样本方差分别为$s_1^2 = 16$和$s_2^2 = 20$,标准误公式为:
$\text{标准误} = \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}} = \sqrt{\frac{16}{100} + \frac{20}{100}} = \sqrt{0.16 + 0.20} = \sqrt{0.36} = 0.6$
步骤4:计算边际误差
边际误差为Z临界值与标准误的乘积:
$\text{边际误差} = Z_{\alpha/2} \times \text{标准误} = 1.96 \times 0.6 = 1.176$
步骤5:构造置信区间
最终置信区间为:
$(\overline{x}_1 - \overline{x}_2) \pm \text{边际误差} = 2 \pm 1.176$