题目
某工厂生产的产品以100个为一批。在进行抽样检查时,只从每批中抽取10个来检查,如果发现其中有次品,则认为这批产品是不合格的,假定每一批产品中的次品最多不超过4个,并且其中恰有i(i =0,1,2,3,4)个次品的概率如下:一批产品中有次品数 0 1 2 3 4-|||-概 率 0.1 0.2 0.4 0.2 0.1求:(1)各批产品通过检查的概率。(2)通过检查的各批产品中恰有i个次品的概率(i=0,1,2,3,4)。
某工厂生产的产品以100个为一批。在进行抽样检查时,只从每批中抽取10个来检查,如果发现其中有次品,则认为这批产品是不合格的,假定每一批产品中的次品最多不超过4个,并且其中恰有$$i(i =0,1,2,3,4)$$个次品的概率如下:

求:(1)各批产品通过检查的概率。
(2)通过检查的各批产品中恰有i个次品的概率$$(i=0,1,2,3,4)$$。
题目解答
答案


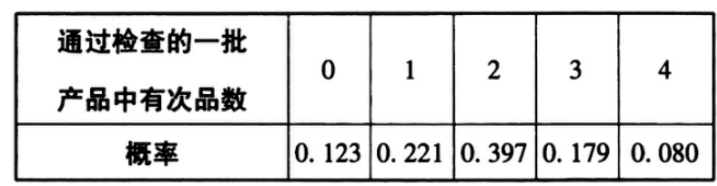
解析
步骤 1:定义事件
设事件$B_i$表示一批产品中有$i$个次品,$i=0,1,2,3,4$。设事件$A$表示这批产品通过检查,即抽样检查的10个产品都是合格品。
步骤 2:计算条件概率
根据题意,$P(B_0)=0.1$,$P(B_1)=0.2$,$P(B_2)=0.4$,$P(B_3)=0.2$,$P(B_4)=0.1$。对于事件$A$,当一批产品中有$i$个次品时,$A$发生的概率为$P(A|B_i)$,即从$100-i$个合格品中抽取10个的概率。
步骤 3:计算$P(A|B_i)$
$P(A|B_0)=1$,因为没有次品,所以10个都是合格品。
$P(A|B_1)=\dfrac{{C}_{99}^{10}}{{C}_{100}^{10}}$,从99个合格品中抽取10个。
$P(A|B_2)=\dfrac{{C}_{98}^{10}}{{C}_{100}^{10}}$,从98个合格品中抽取10个。
$P(A|B_3)=\dfrac{{C}_{97}^{10}}{{C}_{100}^{10}}$,从97个合格品中抽取10个。
$P(A|B_4)=\dfrac{{C}_{96}^{10}}{{C}_{100}^{10}}$,从96个合格品中抽取10个。
步骤 4:计算各批产品通过检查的概率
根据全概率公式,$P(A)=\sum_{i=0}^{4}P(B_i)P(A|B_i)$。
步骤 5:计算通过检查的各批产品中恰有i个次品的概率
根据贝叶斯公式,$P(B_i|A)=\dfrac{P(B_i)P(A|B_i)}{P(A)}$。
设事件$B_i$表示一批产品中有$i$个次品,$i=0,1,2,3,4$。设事件$A$表示这批产品通过检查,即抽样检查的10个产品都是合格品。
步骤 2:计算条件概率
根据题意,$P(B_0)=0.1$,$P(B_1)=0.2$,$P(B_2)=0.4$,$P(B_3)=0.2$,$P(B_4)=0.1$。对于事件$A$,当一批产品中有$i$个次品时,$A$发生的概率为$P(A|B_i)$,即从$100-i$个合格品中抽取10个的概率。
步骤 3:计算$P(A|B_i)$
$P(A|B_0)=1$,因为没有次品,所以10个都是合格品。
$P(A|B_1)=\dfrac{{C}_{99}^{10}}{{C}_{100}^{10}}$,从99个合格品中抽取10个。
$P(A|B_2)=\dfrac{{C}_{98}^{10}}{{C}_{100}^{10}}$,从98个合格品中抽取10个。
$P(A|B_3)=\dfrac{{C}_{97}^{10}}{{C}_{100}^{10}}$,从97个合格品中抽取10个。
$P(A|B_4)=\dfrac{{C}_{96}^{10}}{{C}_{100}^{10}}$,从96个合格品中抽取10个。
步骤 4:计算各批产品通过检查的概率
根据全概率公式,$P(A)=\sum_{i=0}^{4}P(B_i)P(A|B_i)$。
步骤 5:计算通过检查的各批产品中恰有i个次品的概率
根据贝叶斯公式,$P(B_i|A)=\dfrac{P(B_i)P(A|B_i)}{P(A)}$。