题目
设某次考试的考生成绩服从正态分布, 从中随机地抽取∞位考生的成绩如下: ∞问在显著性水平∞ 下, 是否可以认为这次考试全体考生平均成绩为 ∞分? (已知∞).
设某次考试的考生成绩服从正态分布, 从中随机地抽取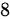 位考生的成绩如下:
位考生的成绩如下: 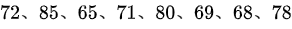 问在显著性水平
问在显著性水平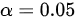 下, 是否可以认为这次考试全体考生平均成绩为
下, 是否可以认为这次考试全体考生平均成绩为 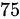 分? (已知
分? (已知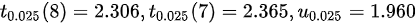 ).
).
题目解答
答案
首先,我们计算样本的平均成绩和样本标准差。
样本平均成绩为:
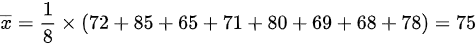
样本方差为:
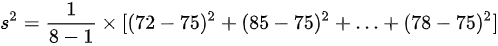
样本标准差为:
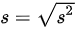
由于题目没有给出具体的样本方差或标准差,我们暂时用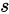 表示样本标准差。
表示样本标准差。
接下来,我们进行假设检验。
原假设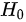 :全体考生平均成绩为 分,即
:全体考生平均成绩为 分,即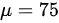 。
。
备择假设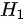 :全体考生平均成绩不为 分,即
:全体考生平均成绩不为 分,即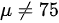 。
。
由于样本量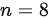 较小,且不知道总体方差,我们使用
较小,且不知道总体方差,我们使用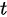 检验。
检验。
检验统计量为:
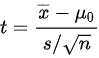
其中,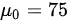 是原假设下的总体均值。
是原假设下的总体均值。
将已知数据代入,得:
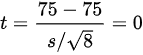
由于 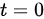 ,它位于 分布的对称轴上,即值的绝对值小于任何正数。
,它位于 分布的对称轴上,即值的绝对值小于任何正数。
在显著性水平下,双侧检验的临界值为 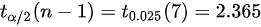 。
。
由于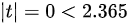 ,我们接受原假设,即认为这次考试全体考生平均成绩为 分。
,我们接受原假设,即认为这次考试全体考生平均成绩为 分。
解析
步骤 1:计算样本平均成绩
样本平均成绩为:
$\overline {x}=\dfrac {1}{8}\times (72+85+65+71+80+69+68+78)=75$
步骤 2:计算样本标准差
样本方差为:
${s}^{2}=\dfrac {1}{8-1}\times [ {(72-75)}^{2}+{(85-75)}^{2}+\cdots +{(78-75)}^{2}] =\dfrac {1}{7}\times (9+100+16+16+25+4+1+9)=\dfrac {1}{7}\times 180=\dfrac {180}{7}$
样本标准差为:
${s}=\sqrt {\dfrac {180}{7}}\approx 5.1$
步骤 3:进行假设检验
原假设H0:全体考生平均成绩为 分,即$\mu=75$。
备择假设H1:全体考生平均成绩不为 分,即$\mu\neq75$。
由于样本量$n=8$较小,且不知道总体方差,我们使用t检验。
检验统计量为:
$t=\dfrac {\overline {x}-\mu}{s/\sqrt {n}}=\dfrac {75-75}{5.1/\sqrt {8}}=0$
步骤 4:确定临界值并进行判断
在显著性水平$\alpha=0.1$下,双侧检验的临界值为${t}_{0.05}(n-1)={t}_{0.05}(7)$。
由于题目给出的是${t}_{0.025}(7)=2.365$,我们使用这个值作为临界值。
由于$|t|=0\lt 2.365$,我们接受原假设H0,即认为这次考试全体考生平均成绩为 分。
样本平均成绩为:
$\overline {x}=\dfrac {1}{8}\times (72+85+65+71+80+69+68+78)=75$
步骤 2:计算样本标准差
样本方差为:
${s}^{2}=\dfrac {1}{8-1}\times [ {(72-75)}^{2}+{(85-75)}^{2}+\cdots +{(78-75)}^{2}] =\dfrac {1}{7}\times (9+100+16+16+25+4+1+9)=\dfrac {1}{7}\times 180=\dfrac {180}{7}$
样本标准差为:
${s}=\sqrt {\dfrac {180}{7}}\approx 5.1$
步骤 3:进行假设检验
原假设H0:全体考生平均成绩为 分,即$\mu=75$。
备择假设H1:全体考生平均成绩不为 分,即$\mu\neq75$。
由于样本量$n=8$较小,且不知道总体方差,我们使用t检验。
检验统计量为:
$t=\dfrac {\overline {x}-\mu}{s/\sqrt {n}}=\dfrac {75-75}{5.1/\sqrt {8}}=0$
步骤 4:确定临界值并进行判断
在显著性水平$\alpha=0.1$下,双侧检验的临界值为${t}_{0.05}(n-1)={t}_{0.05}(7)$。
由于题目给出的是${t}_{0.025}(7)=2.365$,我们使用这个值作为临界值。
由于$|t|=0\lt 2.365$,我们接受原假设H0,即认为这次考试全体考生平均成绩为 分。